
Published on April 3, 2025 7:21 PM GMT
This post summarizes the taxonomy, challenges, and opportunities from a survey paper on Representation Engineering that we’ve written with Sahar Abdelnabi, David Krueger, and Mario Fritz.
If you’re familiar with RepE feel free to skip to the “Challenges” and “Opportunities” sections.
What is Representation Engineering?
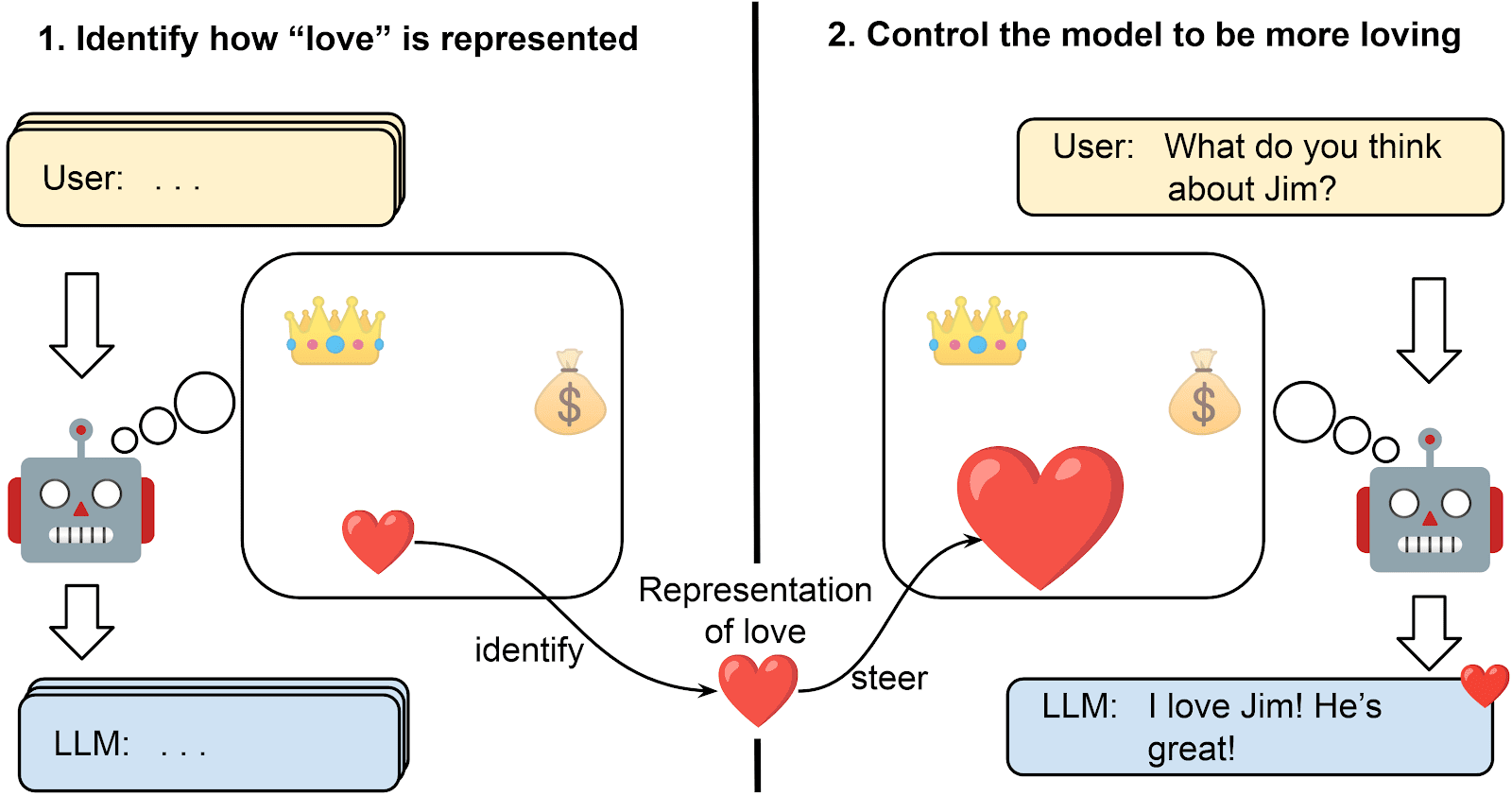
Representation Engineering (RepE) is a class of techniques that manipulate the representations of a concept in order to control its behaviour with regard to that concept. To achieve this, they (1) identify how the targeted concept is represented within the model and (2) use that information to steer the model’s representations on new inputs.
RepE includes methods such as Activation Steering e.g. Contrastive Activation Addition (CAA), Low-Rank Representation Adaptation (LoRRA), steering with Sparse Autoencoders, Bi-directional Preference Optimization (BiPO).
By tapping into models’ representations, RepE offers two main advantages: (1) Improve understanding: RepE identifies how human-understandable concepts are represented in the models’ activation space; steering that representation can verify whether the representation has the expected influence on the outputs and can offer an easy way to understand the model's internals. (2) Control: RepE is promising as a powerful tool to control the behaviour, personality, encoded beliefs, and performance of an LLM, allowing us to make models behave in safe and desired ways. Since no training is required, RepE can be cheaper, more data efficient, and more flexible to different users and situations than other methods while causing less deterioration to the model’s performance
RepE techniques have been applied to prevent harmful outputs, make models more truthful, align them with human preferences, change the model's situational beliefs, induce it to carry out specific tasks, change its goals, improve reasoning performance and generally interpret model internals.
Our Taxonomy
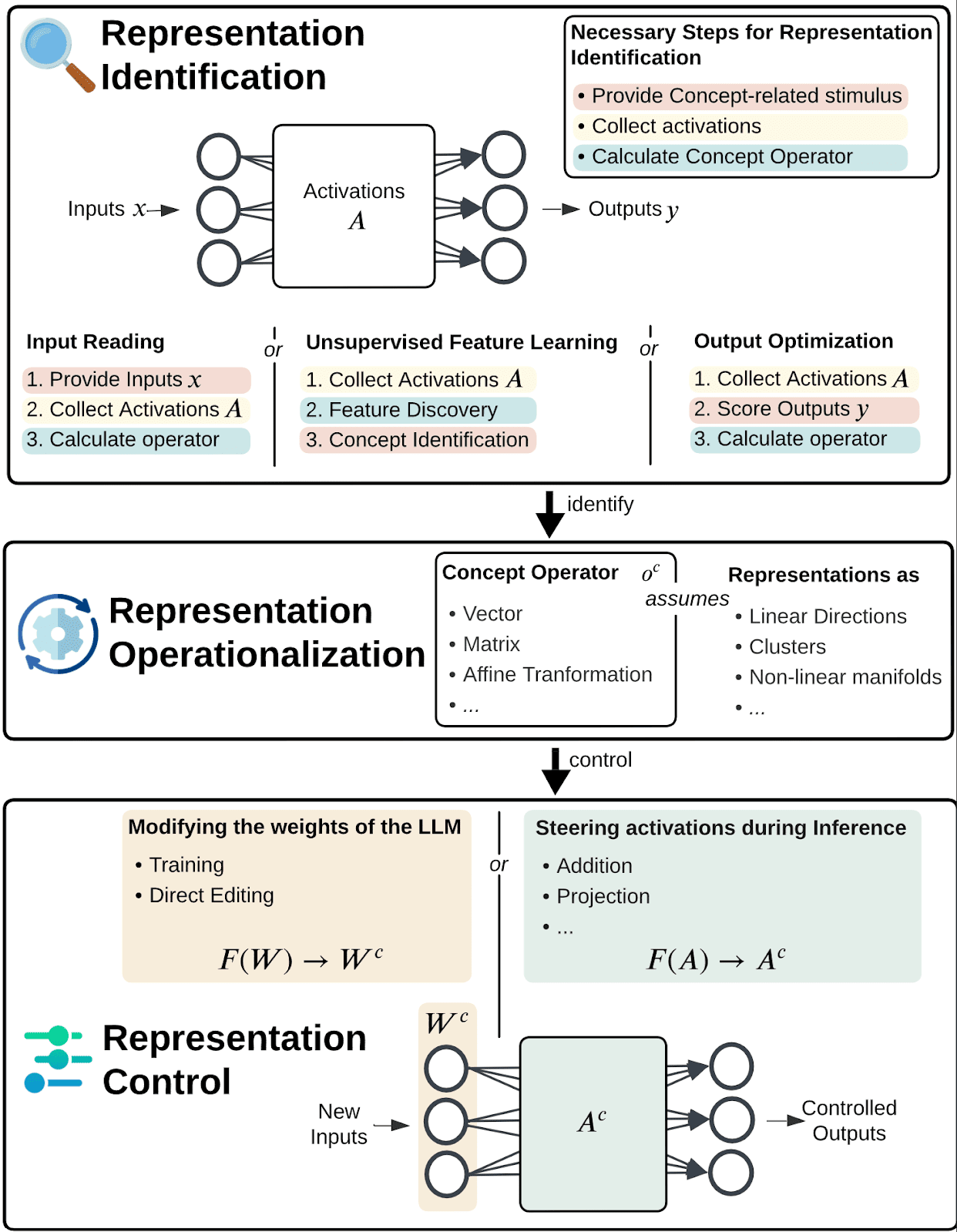
A pipeline to perform Representation Engineering has three aspects. We use CAA to illustrate them:
- Representation Identification aims to find out how the concept is represented in the LLM’s activations. Such methods can calculate the difference in activations from specific inputs, identify features through an unsupervised learning process or optimize an operator to lead to desired outputs. E.g. in CAA, this is done by taking the mean difference between activations for positive and negative inputs wrt the concept..Representation Operationalization decides on the shape and meaning of a concept operator that denotes the representation. It also bakes in assumptions about the geometry of representations in the model's activations. E.g. in CAA, this is a vector, which assumes that representations are linear directions.Representation Control steers the representation of a concept to control the model’s behaviour w.r.t. that concept. This can be done by steering the activations during inference or modifying the weights of the model. E.g. in CAA, the vector is added to the activations.
Challenges
RepE methods are unreliable: RepE methods are sensitive to changes in hyperparameters (eg steering coefficient or layer of intervention), fail to steer some concepts and can even negatively steer inputs on concepts that are steerable on average. Furthermore, using RepE for interpretability to make claims that a concept is not represented, its representation is localized at a specific point or that it’s represented by a specific vector has been challenged as unreliable.
RepE often fails to generalise out-of-distribution: Current methods become less effective under domain shift when the new inputs differ from the training data, like changing the system prompt or steering at different generation timesteps.
RepE may result in capability deterioration: RepE generally leads to a reduction in general language modelling capabilities. While this reduction is small, it still represents an important cost to employing RepE that should be reduced.
RepE methods struggle to identify precise Concept Representations: Ideally, RepE would identify concept operators that are (1) specific ie only influence the concept of interest and not others and (2) complete ie capture all the aspects of a concept across contexts.
It’s difficult to craft a dataset or scoring function that correctly specifies the concept: To identify a representation, a dataset or scoring function is provided. If these do not correctly specify the concept, the learned representation will be incorrect. Furthermore, other concepts might be spuriously correlated with our concept of interest and most RepE methods are not able to disentangle those correlated concepts. Lastly, the dataset or scoring function might not activate the desired representation. For example, instructing a model to be honest might trigger a representation for “I will answer honestly” or for “the human wants me to answer honestly”.
RepE suffers from interference from Superposition: LLMs represent features in superposition, meaning that features are not all orthogonal to each other, which results in interference between features. In practice, this will mean that controlling a concept representation will also steer some other concepts.
RepE makes overly restrictive assumptions about models’ representations: When operationlizing a representation RepE bakes in assumptions about the geometry of representations. If these assumptions are wrong, it will not identify the correct representation.
Activation space interpretability may be doomed. As RepE techniques are based only on activations, they could be prone to discovering statistical artifacts of the activations which are not actually used by the model in computation. See more here.
Other weaknesses include a failure to steer multiple concepts at once, steer long-form generations, reliance on access to model internals and computational costs of some RepE methods. Furthermore, there are challenges around assumptions on available data, reliance on the model’s own representations, a lack of ground truth in interpretability and shifting activations off their natural distribution.
Opportunities
Methodological Improvements
More precisely identifying Representations: One could identify better concept operators by combining multiple methods for Representation Identification or by refining concept operators to make them more suitable for steering. Furthermore, a focus on improving the quality of data for RepE or improved methods for specifying the concept in a dataset or scoring function would likely yield improvements.
Extending assumptions about Representations: There are some assumptions many RepE methods make about the nature and geometry of representations. Expanding these is a promising direction:
| Common Assumption about Representations | Extensions |
| Concepts are represented as linear directions | Concepts can be represented non-linearly |
| Representations do not change throughout a generation | Modelling trajectories of activations throughout a generation |
| Concepts are represented without interactions between layers | Identifying representations with dependencies across layers |
There is only one concept operator that represents a concept
| Identifying multiple concept operators |
| A concept is represented the same across different contexts | Identifying context dependent representations |
| Identify individual representations per concept | Identifying representations for interactions between concepts |
More capable Representation Control: RepE could steer complex sequences, where different interventions are made at different timesteps, or by employing more expressive steering functions. Furthermore, the training process can be steered by ablating or strengthening a representation during fine-tuning to control how representations are learned.
Some promising applications of RepE: RepE might be uniquely well suited to control some concepts where misaligned models might not follow instructions in prompts. Examples of this are changes to the models' goals or instructions to not be deceptive. Furthermore, RepE could be used to study how representations evolve throughout training or to control how agents cooperate in multi-agent scenarios.
Building a More Rigorous Science of RepE: Lastly, it is important to build a stronger scientific basis of RepE. First and foremost, this includes developing a comprehensive benchmark that compares RepE methods with other approaches for controlling different types of concepts. Better methods for measuring steerability and more adherence to best practices for evaluating RepE methods are important for scientific validity. Better insights can be attained by developing theoretical frameworks for RepE or studying RepE in Toy Settings.
Enabling practical adoption: To enable adoption, RepE methods need to prove themselves in a fair fight against other methods in downstream applications, the community needs to build tooling to make RepE easy to use, and best practices for applying RepE should be made salient.
The full survey discusses all these points in more detail, gives citations to back up my claims and offers much more! You can find the full paper here.
I am happy to discuss these ideas: jan.wehner@cispa.de
Discuss
