
Published on April 1, 2025 2:14 AM GMT
Hello! This is a mini-project that I carried out to get a better sense of ML engineering research. The question itself is trivial, but it was useful to walk through every step of the process by myself. I also haven’t had much experience with technical research, so I’d greatly appreciate any feedback. My code is available on github.
This task originated from an application to Aryan Bhatt’s SPAR stream. Thanks to Jacob G-W, Sudarsh Kunnavakkam, and Sanyu Rajakumar for reading through / giving feedback on an initial version of this post! Any errors are, of course, my own.
Tl;dr: Does summarization degrade LLM performance on GPQA Diamond? Yes, but only if the model has a high baseline. Also, the degree of summarization is not correlated with performance degradation.
Summary
I investigate whether summarizing questions can reduce the accuracy of a model’s responses. Before running this experiment, I had two hypotheses.
- Summarization does affect a model’s performance, but only when mediated through ‘loss of semantic information’ (as opposed to because of the words lost).More semantic information lost, results in worse model performance.
I operationalized these through two summarization metrics: syntactic summarization and semantic summarization. The former represents our intuitive notion of summarization; the latter aims to capture the fuzzier notion of how much meaning is lost.
Results indicated that summarization was only an issue when the model had a high baseline to start with. Whereas, when baseline performance was low, summarization had negligible effect [Table 1]. Also, the degree of summarization (either syntactic or semantic) was not correlated with performance degradation (figures attached under Results).
Table 1: Model baseline performance on GPQA Diamond vs Model performance
when the questions were summarized. Results shown with 95% confidence intervals.

Methodology
First, I evaluated GPT 4o-mini, and o3-mini on GPQA Diamond to measure baseline scores. Then, I summarized the questions using GPT 4o, before evaluating the above models on the shortened questions. I didn’t summarize the answer choices.
Summarization
Syntactic Summarization: This was measured as ratio of words (separated on whitespace) between the summarized and the original prompts. This captures the intuitive notion of summarization as reducing the bulk of a text. This should, in theory, be clamped between 0 to 1. However, the model occasionally output ‘summaries’ that were longer than the original question, leading to scores greater than 1.
Semantic Summarization: This was measured by the BERTScore between the text of the two questions. It attempts to capture the amount of ‘meaning’ lost through summarization. The BERTScore is technically clamped between -1 and 1 – but, in practice, is often much closer to 1.
I used GPT 4o to summarize the questions on GPQA Diamond. I tried a couple different prompts, until I got a summarization I was happy with. These summarizations also did well empirically. The average syntactic summarization, across all questions, was 0.49; and the average semantic summarization was 0.90. In other words, the model was able to greatly reduce text, while largely preserving the original meaning of the questions.
Evaluations
I used the Inspect library to run evals on GPT 4o-mini and o3-mini. I used the default configuration, and didn’t add any custom system / user prompts. My baseline scores were pretty similar to established results. Also, I ran the eval on GPT 4o-mini for 5 rounds, and o3-mini for 3 rounds.
Metrics
My second hypothesis was the amount of summarization was correlated with performance degradation. I couldn’t directly control the degree of summarization, naturally – so that made it closer to a ‘matched pairs’ experimental design. Ie. I grouped together questions that had similar amounts of summarization, and measured how model performance differed between the two experimental conditions. I also excluded bins that had very few questions.
Results
Aggregate Results
As Table 1 indicated, the effect of summarization depended on the model’s baseline score. GPT 4o-mini had only a moderate baseline of 41%, so summarization didn’t degrade model performance much. o3-mini, though, had a much higher baseline of 75%, which summarization brought down to 64%.
Now we’ll go into more granular detail, and see if the amount of summarization is correlated with performance degradation. Note: we can’t make claims about summarization causing performance degradation, because this wasn’t a randomized controlled experiment.
GPT 4o-mini
There was little correlation between the degree of summarization (either syntactic or semantic) and model performance. On one hand, this is not very surprising, because summarization didn’t affect model performance on the aggregate. But on the other hand, it is still interesting that you can parse down a question to one-fifth of its original word count, and still have near-identical performance.
I’m also mildly surprised by the minor dip in performance when syntactic summarization is greater than 0.6. However, I’m interpreting this as not significant. This is for a few reasons: a) the number of samples are relatively smaller than the other bins, b) there’s no clear downward trend, and c) having a ‘summary’ longer than the original text is weird & it should not factor into generalizations we make.
Figure 1: Model performance has little degradation for
different degrees of syntactic summarization
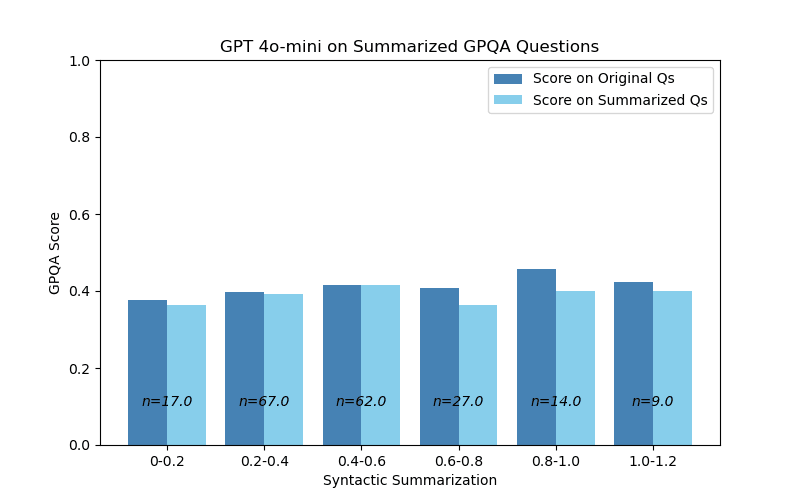
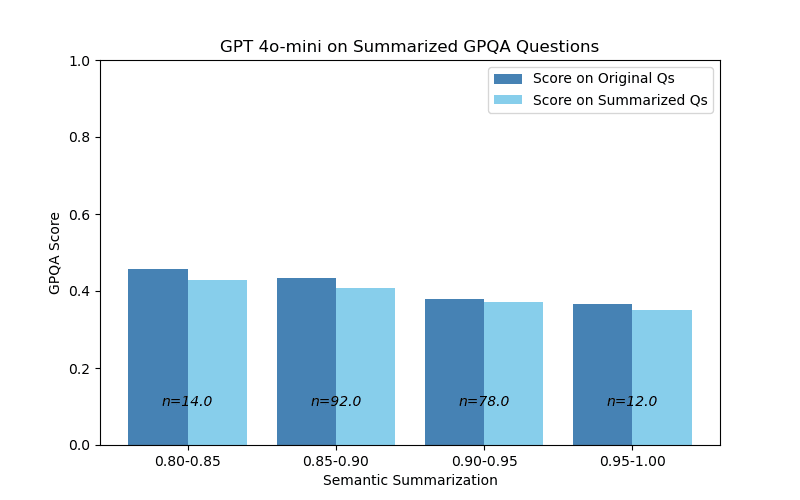
Figure 2: Model performance also has little degradation
for degrees of semantic summarization
o3-mini
With o3-mini, there was a marked reduction in performance on the summarized questions. Nonetheless, with syntactic summarization, results were similar to GPT 4o-mini. Ie. the amount of degradation remained fairly constant across all the degrees of summarization.
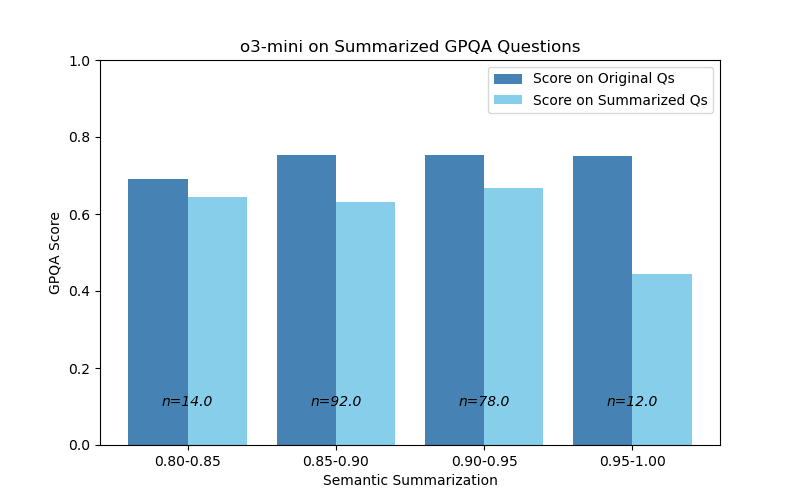
With semantic summarization, however, model performance was markedly less for questions with degree 0.95-1.00. Again, this is mildly surprising, compared to my initial hypothesis. However, again, this bin had the lowest sample size, with n=12. More data would be needed to say anything conclusive.
Figure 3: Model performance is slightly worse for
high syntactic summarization
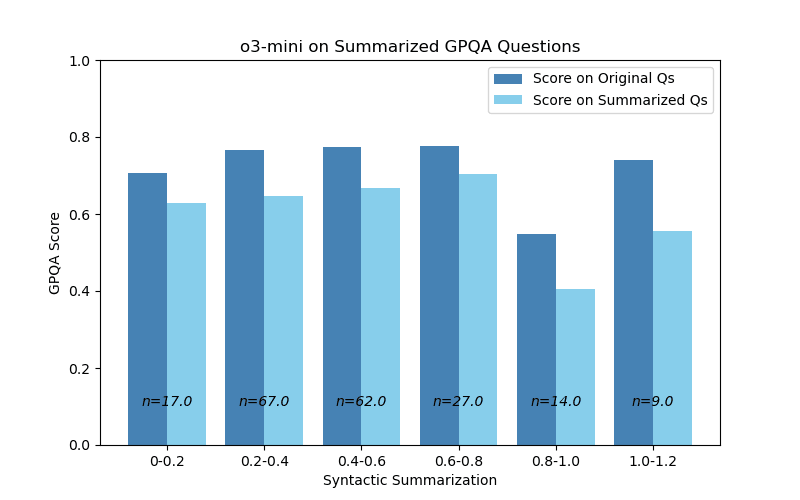
Figure 4: Model performance is slightly worse for
high semantic summarization
Discussion
I’m surprised by the results on semantic summarization! I had predicted that greater summarization would positively correlate with degradation, but that was not the case. Looking at these results, one might guess this was partly due to the narrow range of summarization scores. However, BERTScores are usually clustered around that range anyways. It is also possible that BERTScore was an inappropriate metric for semantic summarization.
It’s also interesting that syntactic summarization had little correlation with degradation. We can reduce the original question by a large amount, and still get similar results as if we hardly reduced it.
A confounding factor is that the models might have memorized some of these questions. That might be a partial explanation, but it’s not entirely satisfactory. On one hand, if there is memorization, I’d expect a mild performance decrease solely due to rephrasing. This is similar to what we’re seeing in Figure 3, where there’s a similar decrease in performance, across various degrees of summarization. However, I’d still expect the summarization to have some correlation with performance, which we aren’t seeing. This would also imply that o3-mini is doing some memorization, and GPT 4o-mini is not. If anything, I’d expect it to be the other way round – given that o3-mini is the reasoning model. Also, I’m not sure they’d be able to memorize much in the first place, given that both are distilled models. But then again, GPQA is a pretty common benchmark – so I’m not sure how well this explanation holds up.
A follow-up experiment could look into whether these models are memorizing the questions. One could do so with a similar experimental design to this one – but instead of summarizing the questions, we only rephrase the wording by a small amount, and investigate if model performance is the same.
Discuss
