
Published on March 31, 2025 1:35 AM GMT
Epistemic status: The important content here is the claims. To illustrate the claims, I sometimes use examples that I didn't research very deeply, where I might get some facts wrong; feel free to treat these examples as fictional allegories.
In a recent exchange on X, I promised to write a post with my thoughts on what sorts of downstream problems interpretability researchers should try to apply their work to. But first, I want to explain why I think this question is important.
In this post, I will argue that interpretability researchers should demo downstream applications of their research as a means of validating their research. To be clear about what this claim means, here are different claims that I will not defend here:
Not my claim: Interpretability researchers should demo downstream applications of their research because we terminally care about these applications; researchers should just directly work on the problems they want to eventually solve.
Not my claim: Interpretability researchers should back-chain from desired end-states (e.g. "solving alignment") and only do research when there's a clear story about why it achieves those end-states.
Not my claim: Interpretability researchers should look for problems "in the wild" that they can apply their methods to.
Rather my claim is: Demonstrating your insights can be leveraged to solve a problem—even a toy problem—that no one else can solve provides validation of those insights. It provides evidence that the insights are real and significant (rather than being illusory or insubstantial).
The main way I recommend consuming this post is by watching the recording below of a talk I gave at the August 2024 New England Mechanistic Interpretability Workshop. In this 15-minute talk, titled Towards Practical Interpretability, I lay out my core argument; attendees empirically found the talk very engaging, and maybe you will too.
In the rest of this post, I'll briefly and sloppily recap this talk's content. If you watched the video, then the rest of this post will just repeat what you watched, but worse (and with some footnotes for caveats that I learned after the talk).
Two interpretability fears
I'll start by explaining two concerns I struggle with when evaluating interpretability research:
- Illusory insights: How do we verify that our mechanistic insights are "real"?Unimportant insights: Even assuming that our insights are not illusory, how can we tell how much progress they constitute?
My favorite example of the illusory insights problem comes from Sanity Checks for Saliency Maps (Adebayo et al., 2018). Saliency maps are a technique which purport to—given an image classification network and an image—tell you which parts of the image were important for the network's classification. The results often look quite compelling, e.g. in the image below, the technique seems to show that the network was attending to the bird's silhouette, eye, and beak.
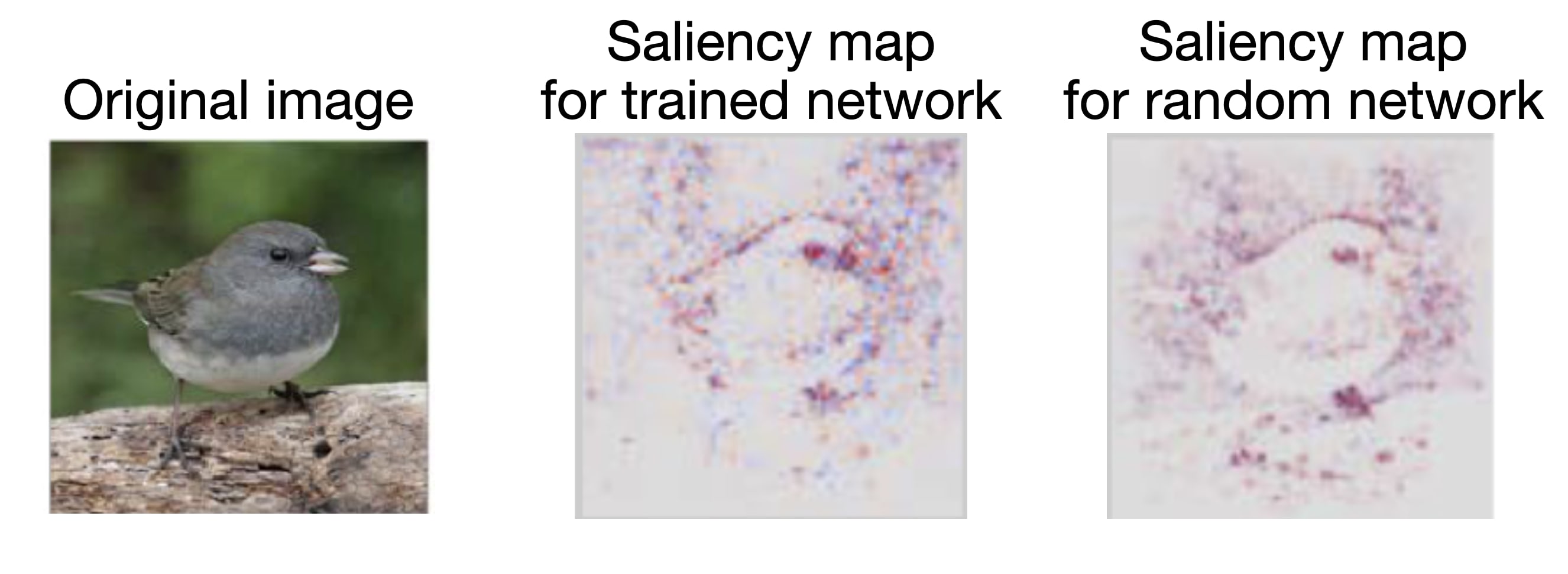
However, it ends up that applying this technique to a random network—that is, an untrained network with random weights—gives results that are just as compelling! This suggests that saliency maps were just functioning as something like "simple edge detectors," something that you don't need any mechanistic understanding of neural networks to build. As intuitively compelling as the saliency mapping results seemed at first, they were producing illusory insights.[1]
These days, we know that we should do various ablations (e.g. random network ablations) to tests for these types of illusions. But our ablations aren't exhaustive, and were largely developed post-hoc in order to validate new types of claims. There's inherently a bit of a lag between new types of claims being made, and having an experimental paradigm suited to validating them. Later I'll propose downstream applications as a way to side-step this issue.
To understand the unimportant insights concern, first note that some insights are important and others are not. For example, suppose that while investigating the GPT-2 embedding layer, you notice that due to a rare numerical stability issue that only comes up for the particular input "tough luck," the embedding vector for this text is 1.00001x larger than it should be; as far as you can tell, this has noticeable effect on the model's downstream behavior. The observation you made is true (and perhaps, to some people, interesting) but not important—what are you going to do with it? It's not that you haven't found the right problem to apply your observation to yet, it's that your observation is inherently not really the sort of thing that you'd expect to matter for anything.
In my talk, I analogize neural network interpretability to the field of biological neuroscience.[2] Like biological neuroscience, interpretability researchers claim to have insights about the mechanisms of neural network computation, as well as optimism that these insights are building towards unlocking powerful applications. Unlike interpretability, biological neuroscience is a more mature field, where I have fewer "illusory insight"-type concerns. However, in both cases, it's hard to tell if the insights being discovered are making substantial progress towards end goals.
One way that insights can be (relatively) unimportant is for end goals to be extremely lofty, such that reaching them requires a substantial "picking up the pace" of importance-weighted insights. Some neuroscientists have long thought that neuroscientific insights could enable the production of strong truth sera. And probably neuroscience has been producing non-illusory insights that make some amount of progress here. How much progress? Well as best I know, no neuroscience-inspired truth serum has surpassed the efficacy of alcohol, a substance that has been known for thousands of years. And it's a bit hard to tell which of the following worlds we're in (the magnet represents the efficacy of neuroscience and the beer represents the efficacy of beer):
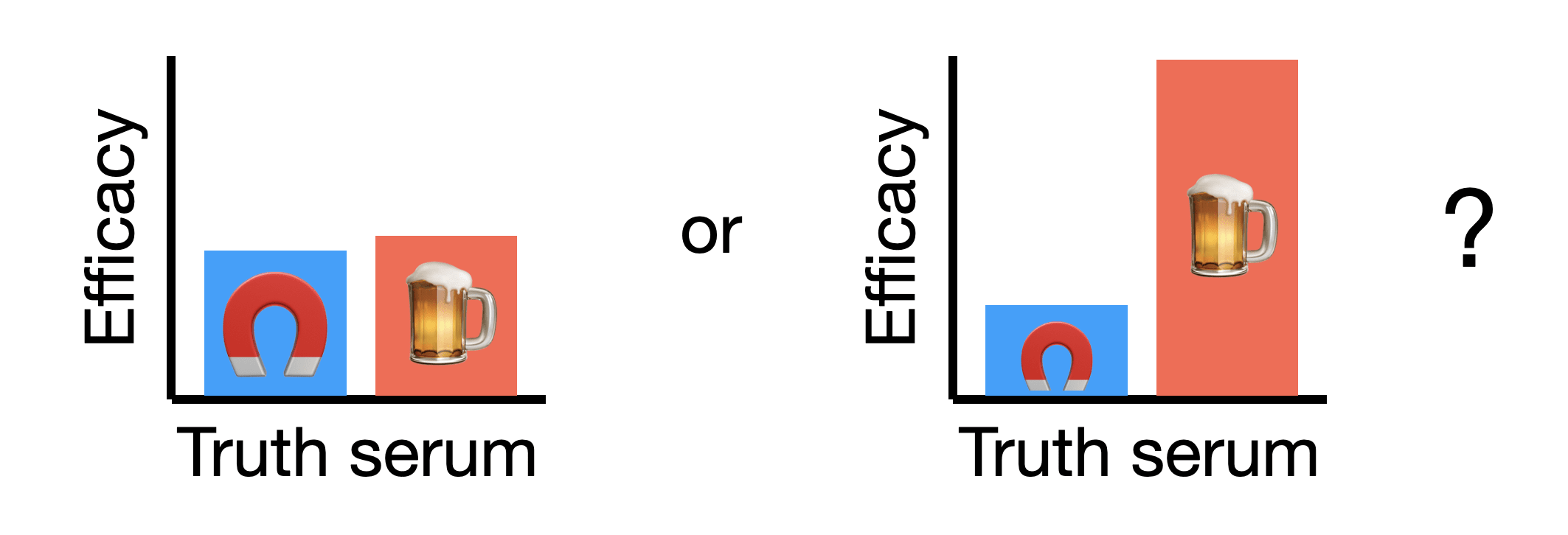
In the world on the left, neuroscience is on the verge of practical use and we just need a few more insights. In the one on the right, our neuroscientific understanding is so limited (and the baselines so good) that it's hard to imagine them eventually stacking up to usability. Below I'll argue that showing insights enable downstream applications, even on toy tasks, give some evidence that we're in the world on the left.
Proposed solution: downstream applications
My proposed solution: Interpretability researchers should showcase downstream applications where their methods beat non-interp baselines in a fair fight.
By downstream application I mean a task with a goal that does not itself make reference to interpretability. E.g. "Make [model] more honest" is a downstream application. But "Explain how [model] implements [behavior]" and "Find a circuit for [behavior]" are not—these are goals that definitionally can only be accomplished by interpretability techniques.
By beat non-interp baselines in a fair fight I mean that you should:
- Clearly specify which affordances are allowed (e.g. in which ways are you allowed to interact with the model? what data are you allowed to use?)Test the best techniques for accomplishing the task that make use of the same affordances.
For example, suppose you propose an interpretability technique for making a model more honest that makes use of white-box access to the model and some honesty-related data. Then you should compare your technique against things like "Instructing the model to be more honest," "Few-shot prompting with the honesty data," and "Finetuning the model on the honesty data."
To give a concrete example from my work, consider the following task that we proposed in Sparse Feature Circuits: Given
- a pretrained language model M anda labeled dataset of professional biographies for male professors and female nursesa cache of generic pretraining data
build a classifier for profession that is not confounded by gender. We proposed an interpretability-based technique, SHIFT, for doing this, which worked by using the ambiguous labeled data and the pretraining data to identify units in M that seemed related to gender, and then ablating these units from the model when tuning a classification head. We compared this to a concept bottleneck baseline, which was the only reasonable baseline we could think of that could function under the task assumptions.[3] (See Gandelsman et al. (2024), Shaham et al. (2024), Karvonen et al. (2025) and Casademunt et al. (2025) for other examples of applying interpretability to spurious cue removal tasks.)

I think that if your insights allow you to do something that no one else is able to do—i.e. to outperform baselines on a downstream task—then they're less likely to be illusory or unimportant. Intuitively, if an insight is illusory, then it shouldn't be able to move the needle on a practical task—it should break down once you try to do anything with it. And if an insight is able to solve a downstream task, then that gives some signal that it's the sort of insight that practically matters (rather than e.g. being a very narrow insight of little practical importance).
(And I think that it's important that you beat the best baseline that exists, not just the best one that you know of. For example, I recently learned that there's a simple baseline that is competitive with SHIFT on the task I described above; namely, the baseline is "delete all the gendered tokens from the professional biography data, then train a classifier." It's tempting to dismiss results like this, since obviously this "gendered token deletion" baseline wouldn't work on other similar tasks. But SHIFT might not either! Just like saliency maps seem to ultimately be "fancy edge detection," I'll worry that SHIFT is "fancy token deletion" until someone exhibits a task where token deletion fails but SHIFT succeeds.)
Aside: fair fight vs. no-holds barred vs. in the wild
(This section contains content that was only briefly mentioned during the talk Q&A.)
I conceptualize three categories of downstream applications:[4]
- Fair fight. You're allowed to pick the "rules of the game" (e.g. to say what types of data and model access are allowed). You need to show that your technique beats the baselines that follow the same rules.No holds barred. There are no rules, only a task description. Your method needs to beat all the other baselines that someone would actually reasonably attempt.In the wild. Your method is actually providing benefit on a real-world problem.
The SHIFT demo I discussed above is a fair fight, but not no holds barred. In a no holds barred demo, I would need to contend with baselines like "just go collect auxiliary data that isolates the gender concept, e.g. by collecting synthetic data." SHIFT would most certainly not beat these sorts of baselines on this task.
In this post, I'm arguing that interpretability researchers should aim to make "fair fight" demos (which are allowed to be quite toy, as apparent from the SHIFT example). While "no holds barred" demos are nice where possible, they're not yet what I'm advocating for. My view is that "fair fight" demos capture most of the "validating insights" benefits. With "no holds barred" and "in the wild" demos, you start to get into questions of whether the problems that you're able to solve are problems which are likely to naturally occur; while these questions are ultimately empirical, I think they can partly be substituted by conceptual arguments forecasting what problems we'll be facing in the future.
Conclusion
"In real life, we don't have corporate overlords hanging over us ... but I kinda sometimes wish that we did."
In my NEMI talk, I concluded with a series of hypothetical dialogues between Claude Shannon (at Bell Labs) and Cleo F. Craig (the CEO of AT&T in 1955). I thought they were fun, so I'll reproduce them here.
In these dialogues, we explore various justifications Claude Shannon could give to Mr. Craig for his work on information theory. The first justification isn't much of a justification at all, or perhaps can be thought of as an appeal to the inherent interestingness of the work. I think it's this response which current interpretability researchers and enthusiasts are most likely to give, but I don't think it's a very good one.

A second response, which I also don't love, gives a self-referential justification, of the information-theoretic applications of information theory. This, I think, rhymes with justifying interpretability work by its applications to understanding neural mechanisms.

In this post, I advocate for a third type of response: A justification by appeal to solving problems that no one else can solve, no matter how toy they might be.

This answer isn't the end of the conversation—you might rightfully wonder why we should care about such-and-such toy application—but I think it allows the conversation to productively continue.
- ^
Professor Martin Wattenberg, after this talk, told me that in certain settings, saliency maps might produce genuine insights. For example, he mentioned some researchers using them to notice that on a subset of their data, labels were written inside the image. I haven't looked into this in detail. If it ends up that saliency maps are actually great, then take this all as a fictional illustrative example.
- ^
I don't actually know anything about biological neuroscience, and everything I say here might be wrong. If so, take it all as another fictional allegory. Sorry!
- ^
For example, standard unlearning or spurious correlation removal techniques assume access to data that isolate the spurious cue (i.e. data where gender and profession are not perfectly correlated).
- ^
These are somewhat similar to, but not the same as, Stephen Casper's "Streetlight/Toy demos", "Useful engineering", and "Net safety benefit" categories, respectively.
Discuss
