
Published on March 28, 2025 2:12 PM GMT
Tl;dr: no.
This is a rough research note – we’re sharing it for feedback and to spark discussion. We’re less confident in its methods and conclusions.
Once AI fully automates AI R&D, there might be a period of fast and accelerating software progress – a software intelligence explosion (SIE).
One objection to this is that it takes a long time to train SOTA AI systems from scratch. Would retraining each new generation of AIs stop progress accelerating during an SIE? If not, would it significantly delay an SIE? This post investigates this objection.
Here are my tentative bottom lines:
- Retraining won’t stop software progress from accelerating over time.
- Suppose that, ignoring the need for retraining, software progress would accelerate over time due to the AI-improving-AI feedback loop.A simple theoretical analysis suggests that software progress will still accelerate once you account for retraining. Retraining won’t block the SIE.
- But that same analysis suggests that your software progress will accelerate more slowly.Quantitatively, the effect is surprisingly small – acceleration only takes ~20% longer.However, if acceleration was going to be extremely fast, retraining slows things down by more.
- Today it takes ~3 months to train a SOTA AI system.As a baseline, we can assume that the first AI to fully automate AI R&D will also take 3 months to train.With this assumption, simple models of the SIE suggest that you’re unlikely to complete the SIE within 10 months. (In the model, the SIE is “completed” when AI capabilities approach infinity – of course in reality they would reach some other limit sooner).BUT if by the time AI R&D is fully automated, SOTA training runs have already shortened to one month or less, then completing an SIE in less than 10 months is much more plausible.And improvements in runtime efficiency and other post-training enhancements (which I’m not modelling in my analysis) could potentially allow very fast takeoff without needing to retrain from scratch.
How did I reach these tentative conclusions?
Theoretical analysis
First, I conducted a very basic theoretical analysis on the effect of retraining. I took a standard semi-endogenous growth model of tech development, and used empirical estimates for the diminishing returns to software progress. This is the simplest model I know of to estimate the dynamics of an SIE – and by default it doesn’t account for retraining.
To understand how fast software progress1 accelerates, we can ask: how many times must software double before the pace of software progress doubles? This is a measure of how quickly software progress accelerates: lower numbers mean faster acceleration.
Without including retraining, my median parameters imply that once AI R&D is fully automated, software must double ~five times before the pace of software progress doubles. (There’s large uncertainty.)2 So progress accelerates gradually.
Accounting for retraining increases the number from five to six. Training runs get progressively shorter over time, and the SIE still accelerates but slightly more slowly. (See below for more explanation.)
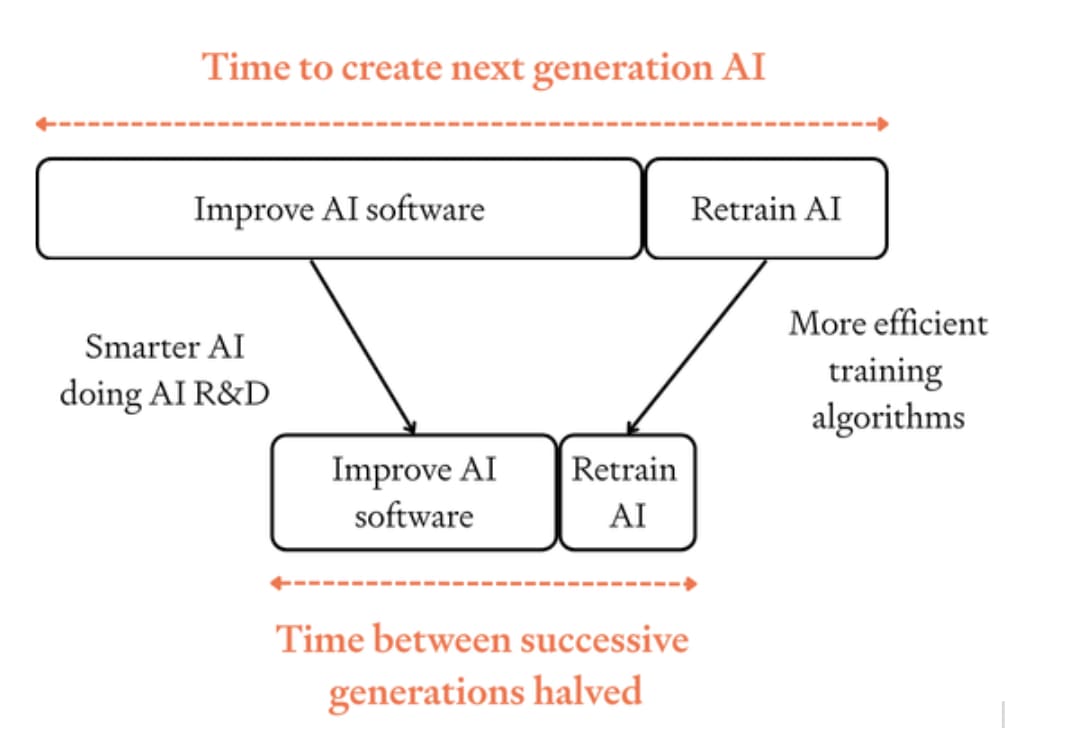
In a very aggressive scenario where software must only double once before the pace of progress doubles, retraining makes a big difference by increasing this to twice. So retraining makes a bigger difference to these aggressive scenarios, making them significantly less extreme.
Simple spreadsheet models
Second, I made very simple spreadsheet models of an SIE – again based on semi-endogenous growth models – one without retraining and one with retraining. Both sheets use the same parameters (other than whether to include retraining) and both calculate the time between the AI R&D being automated and AI capabilities going to infinity. I assumed that AI algorithms become 2X as efficient every month – that’s about ~10X faster progress than today.
Results:
- If the initial training run lasts 100 days:
- The SIE takes about 3X longer with retrainingThe SIE lasts >10 months unless very extreme parameter values are used.
- The SIE takes about 2X longer with retraining.The SIE lasts >7 months unless very extreme parameter values are used.
(These slowdowns are longer than the slowdown predicted by the theoretical analysis because the theoretical analysis assumes that training runs get gradually shorter as the SIE gets closer, so are already very short at the point at which the spreadsheet model begins, and so have less of a slowing effect. See below for details.)
Discuss
