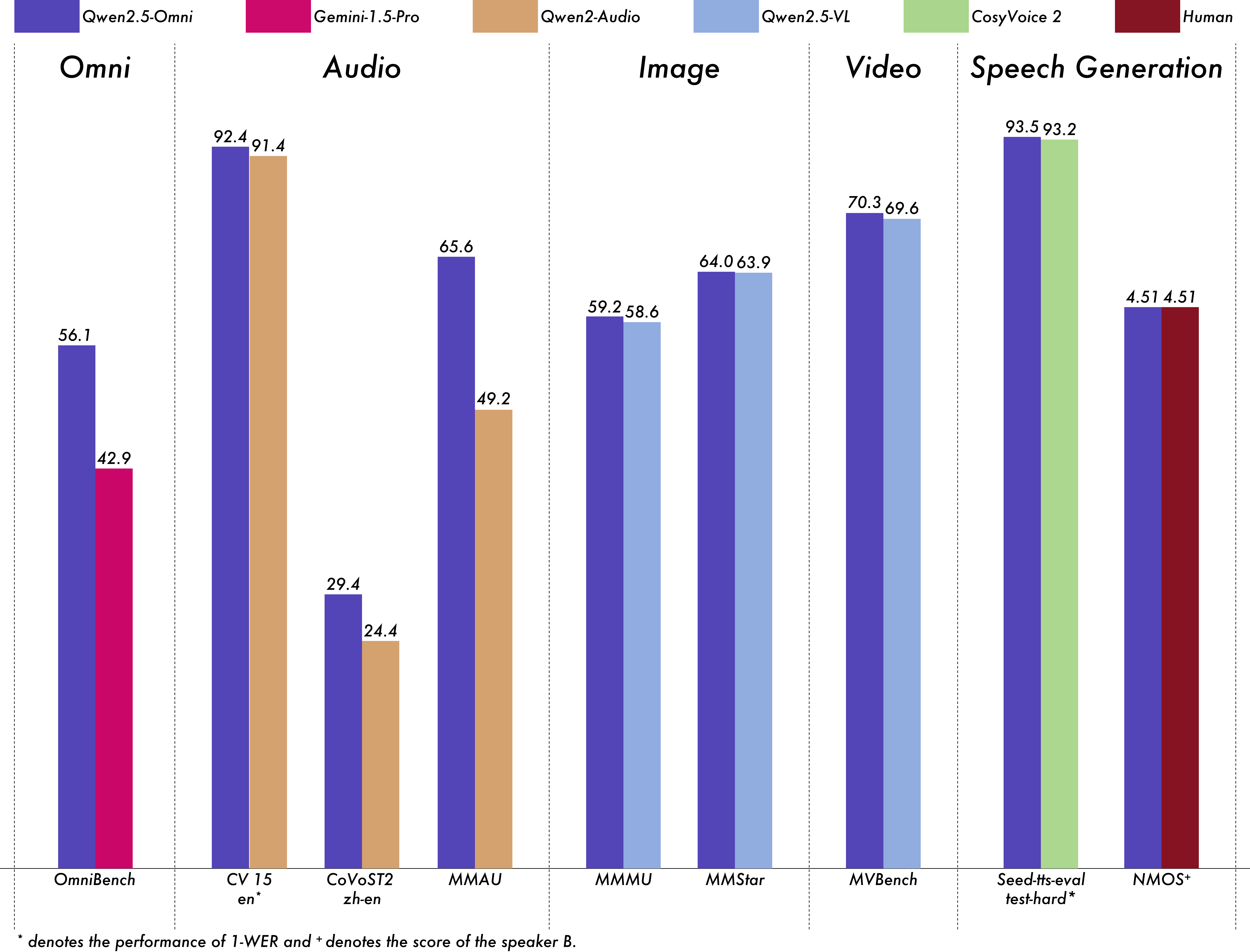阿里云今日宣布开源通义千问Qwen2.5-Omni-7B,这是一个能够同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出的端到端全模态大模型。Qwen2.5-Omni在OmniBench等多模态融合任务测评中表现出色,超越了谷歌Gemini-1.5-Pro等同类模型。值得关注的是,Qwen2.5-Omni仅有7B参数,这使得在手机等终端设备上部署和应用成为可能,降低了全模态大模型在产业上的应用门槛。目前,用户可在魔搭社区和Hugging Face上获取并体验Qwen2.5-Omni。
🖼️ Qwen2.5-Omni是通义系列模型中首个端到端全模态大模型,这意味着它能够同时处理多种类型的数据输入,包括文本、图像、音频和视频。
🗣️ 该模型具备实时生成文本与自然语音合成输出的能力,实现了多模态信息的无缝转换和交互。
🏆 在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新了业界纪录,其性能超越了谷歌Gemini-1.5-Pro等同类模型。
💡 Qwen2.5-Omni拥有7B的小尺寸参数,这使得该模型能够在手机等移动设备上部署和应用,降低了全模态大模型的应用门槛。
🌐 Qwen2.5-Omni已在魔搭社区和Hugging Face同步开源,用户可以方便地获取和体验该模型。
快科技3月27日消息,今天,阿里云宣布通义千问Qwen2.5-Omni-7B正式开源。
这是通义系列模型中首个端到端全模态大模型,可同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出。
在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新业界纪录,全维度远超谷歌的Gemini-1.5-Pro等同类模型。
阿里云表示,相较于动辄数千亿参数的闭源大模型,Qwen2.5-Omni以7B的小尺寸让全模态大模型在产业上的广泛应用成为可能。
即便在手机上,也能部署和应用Qwen2.5-Omni模型。
目前,Qwen2.5-Omni已在魔搭社区和Hugging Face 同步开源,用户也可在Qwen Chat上直接体验。

据悉,2023年起,通义团队陆续开发覆盖0.5B、1.5B、3B、7B、14B、32B、72B、110B等参数的200多款全尺寸大模型,囊括文本生成模型、视觉理解/生成模型、语音理解/生成模型、文生图及视频模型等全模态。
开源地址:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
https://github.com/QwenLM/Qwen2.5-Omni