

Title: Large Language Diffusion Models
Paper Link: https://arxiv.org/abs/2502.09992
Code: https://github.com/ML-GSAI/LLaDA
Project: https://ml-gsai.github.io/LLaDA-demo/

LLaDA is a diffusion-based alternative to autoregressive models for LLMs. It models distributions through a forward data masking process and a reverse process, using a Transformer to predict masked tokens. By optimizing a likelihood bound, it enables principled probabilistic inference.
LLaDA 是一种基于扩散的替代自回归模型的自动生成模型。它通过正向数据掩码过程和反向过程来建模分布,使用 Transformer 预测掩码标记。通过优化似然界限,它实现了原理性的概率推理。
LLaDA demonstrates strong scalability, outperforming self-constructed ARM baselines. LLaDA 8B rivals LLaMA3 8B in in-context learning and, after supervised fine-tuning, shows impressive instruction-following abilities. It also surpasses GPT-4o in a reversal poem completion task, addressing the reversal curse.
LLaDA 展现出强大的可扩展性,在自我构建的 ARM 基线之上表现出色。LLaDA 8B 在上下文学习方面与 LLaMA3 8B 相媲美,经过监督微调后,展现出令人印象深刻的指令遵循能力。它还在反转诗歌完成任务中超越了 GPT-4o,解决了反转诅咒问题。
1.方法
2.概率公式
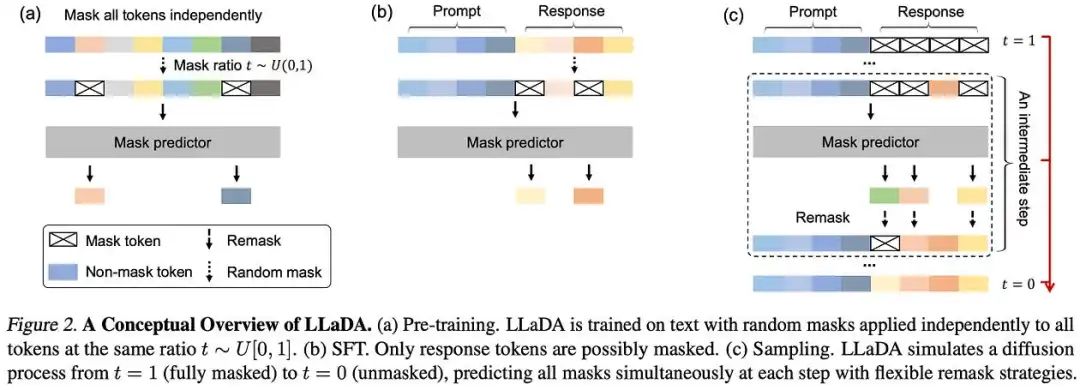
LLaDA models distributions using a forward and reverse process, unlike autoregressive models. The forward process progressively masks tokens in a sequence until fully masked, while the reverse process recovers tokens by predicting masked elements. A mask predictor predicts all masked tokens based on partially masked input. It is trained using a cross-entropy loss applied only to masked tokens.
LLaDA 模型使用正向和反向过程来建模分布,与自回归模型不同。正向过程逐步对序列中的标记进行掩码,直到完全掩码,而反向过程通过预测掩码元素来恢复标记。掩码预测器根据部分掩码输入预测所有掩码标记。它使用仅应用于掩码标记的交叉熵损失进行训练。
The training objective is an upper bound on negative log-likelihood, making LLaDA a principled generative model. Unlike masked language models, which use a fixed masking ratio, LLaDA applies a random masking ratio, improving scalability and enabling natural in-context learning. Its generative formulation ensures Fisher consistency, suggesting strong potential for large-scale applications.
训练目标是负对数似然的上界,使 LLaDA 成为一个原则性的生成模型。与使用固定掩码比率的掩码语言模型不同,LLaDA 采用随机掩码比率,提高了可扩展性并实现了自然情境学习。其生成公式确保 Fisher 一致性,表明其在大规模应用中具有强大的潜力。
3.预训练
LLaDA uses a Transformer-based architecture similar to existing LLMs but without causal masking, allowing it to see the entire input for predictions. Unlike standard LLMs, LLaDA does not support KV caching, leading to using vanilla multi-head attention** and a reduced FFN dimension to balance parameter count.
LLaDA 使用与现有LLMs类似的基于 Transformer 的架构,但没有因果掩码,允许它看到整个输入进行预测。与标准LLMs不同,LLaDA 不支持 KV 缓存,因此使用原生的多头注意力和减少的 FFN 维度来平衡参数数量。
LLaDA is pre-trained on 2.3 trillion tokens with a fixed sequence length of 4096 tokens and used 0.13 million H800 GPU hours.
LLaDA 在 2.3 万亿个标记上进行了预训练,固定序列长度为 4096 个标记,并使用了 0.13 百万小时的 H800 GPU 时间。
Training used Monte Carlo sampling to estimate the objective function. To improve handling of variable-length data, 1% of pre-training samples has random sequence lengths between 1 and 4096 tokens.
训练使用了蒙特卡洛采样来估计目标函数。为了提高处理变长数据的能力,1%的预训练样本具有 1 到 4096 个 token 的随机序列长度。
4.监督微调
LLaDA improves instruction-following ability through SFT using 4.5 million prompt-response pairs. SFT trains the model to predict responses given prompts by modeling a conditional distribution. The prompt remains unmasked, while response tokens are masked and predicted.
LLaDA 通过使用 450 万个提示-响应对进行 SFT 来提高指令遵循能力。SFT 通过建模条件分布来训练模型预测给定提示的响应。提示保持未遮蔽,而响应 token 被遮蔽并预测。
5.推理
LLaDA supports text generation and likelihood evaluation.
LLaDA 支持文本生成和似然评估。
For generation, it samples responses by discretizing the reverse process, starting from a fully masked response and predicting tokens iteratively. The number of sampling steps controls the trade-off between efficiency and quality.
在生成方面,它通过离散化反向过程来采样响应,从完全遮蔽的响应开始,迭代地预测标记。采样步数控制了效率和质量的权衡。
To improve sampling accuracy, predicted tokens are remasked in each step to align with the forward process. The authors explore two remasking strategies: replace predicted tokens with the lowest confidence scores (low-confidence remasking) and generate text block by block from left to right after fine-tuning (semi-autoregressive remasking).
为了提高采样精度,每个步骤中预测的标记都会被重新遮蔽以与正向过程对齐。作者探讨了两种重新遮蔽策略:用置信度最低的预测标记替换(低置信度重新遮蔽)以及在微调后从左到右逐块生成文本(半自回归重新遮蔽)。
For likelihood evaluation, LLaDA leverages a lower-variance reformulation of the loss function for more stable probability estimation. Additionally, it uses unsupervised classifier-free guidance to improve evaluation quality.
在似然评估方面,LLaDA 利用损失函数的低方差重写以实现更稳定的概率估计。此外,它使用无监督的无分类器指导来提高评估质量。
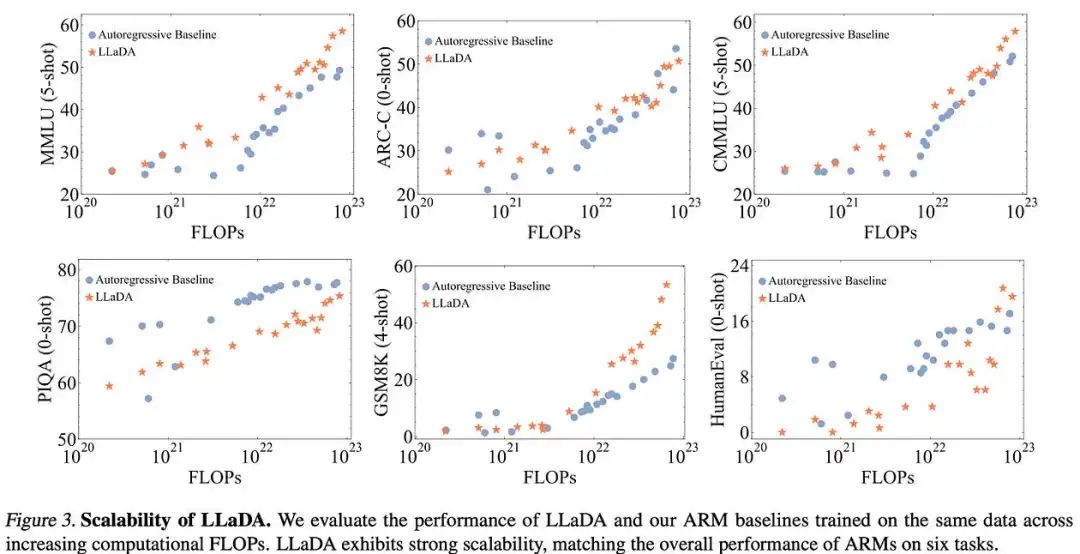
Experiments show that LLaDA scales competitively with ARMs, outperforming them on MMLU and GSM8K and closing the gap on some tasks at larger scales.
实验表明,LLaDA 在 ARM 上具有竞争力,在 MMLU 和 GSM8K 上表现优于 ARM,并在更大规模的任务上缩小了差距。
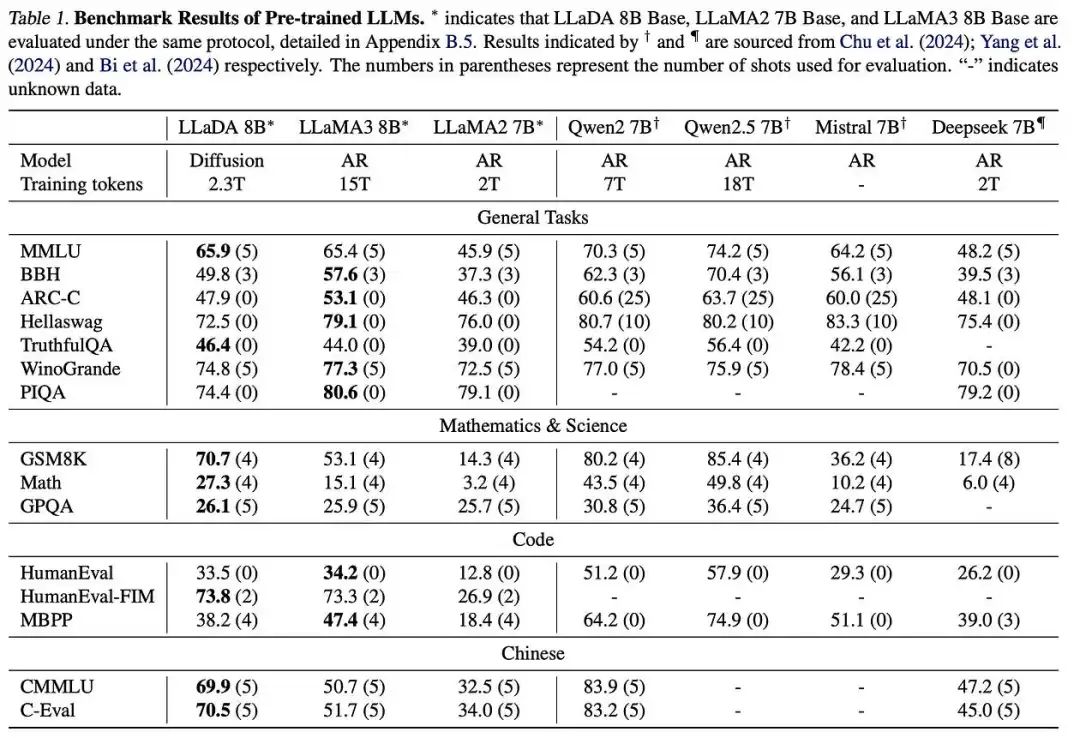
LLaDA 8B was evaluated for in-context learning and instruction-following against existing LLMs of similar scale across 15 benchmarks covering general tasks, mathematics, code, and Chinese.
LLaDA 8B 在 15 个基准测试中评估了上下文学习和指令遵循能力,这些基准测试涵盖了通用任务、数学、代码和中文,与现有 1001 个类似规模的模型进行了比较。
After pretraining on 2.3T tokens, LLaDA 8B outperformed LLaMA2 7B on nearly all tasks and was competitive with LLaMA3 8B, showing an advantage in math and Chinese tasks. Differences in data quality and distribution may explain variations in performance.
在对 2.3T 个标记进行预训练后,LLaDA 8B 在几乎所有任务上都优于 LLaMA2 7B,与 LLaMA3 8B 竞争力相当,在数学和中文任务上显示出优势。数据质量和分布的差异可能解释了性能的波动。
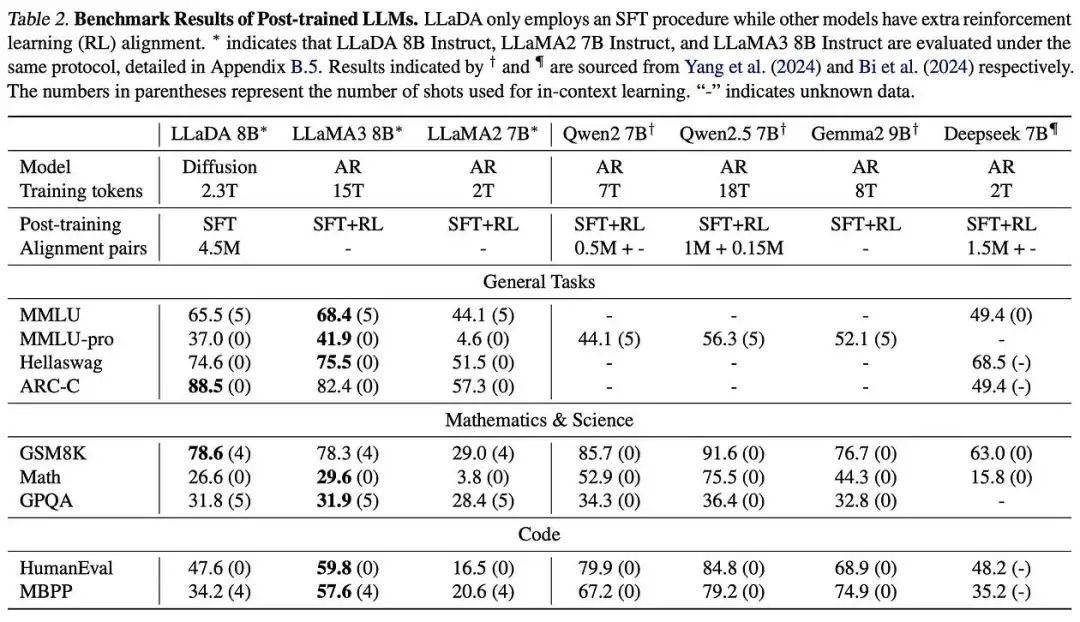
SFT improved performance on most tasks, though some, like MMLU, had lower scores, possibly due to suboptimal SFT data quality. Without RL alignment, LLaDA 8B Instruct performed slightly below LLaMA3 8B Instruct.
SFT 在大多数任务上提高了性能,尽管一些任务,如 MMLU,得分较低,可能是由于 SFT 数据质量不佳。在没有 RL 对齐的情况下,LLaDA 8B Instruct 的表现略低于 LLaMA3 8B Instruct。
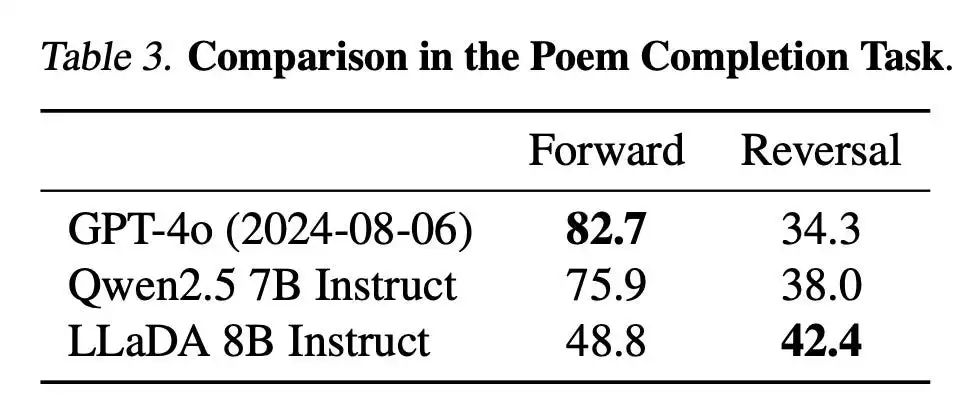
LLaDA was tested for reversal reasoning using a dataset of 496 famous Chinese poem sentence pairs, where models had to generate the next (forward) or previous (reversal) line without fine-tuning. Unlike GPT-4o and Qwen 2.5, which showed a performance gap between forward and reversal tasks, LLaDA excelled in both, effectively overcoming the reversal curse.
使用 496 个著名中国诗句句对的数据集对 LLaDA 进行了逆向推理测试,其中模型需要在没有微调的情况下生成下一句(正向)或上一句(逆向)。与 GPT-4o 和 Qwen 2.5 不同,它们在正向和逆向任务之间表现出性能差距,LLaDA 在两者中都表现出色,有效地克服了逆向诅咒。

This success was achieved without task-specific modifications, likely due to LLaDA’s uniform token treatment, which avoids the inductive biases of autoregressive models.
这种成功是在没有针对特定任务的修改的情况下实现的,这可能是由于 LLaDA 的统一标记处理,它避免了自回归模型的归纳偏差。
Additionally, remasking strategies and sampling steps were analyzed for their impact on performance. Case studies showcased LLaDA 8B Instruct’s ability to generate fluent, extended text, engage in multi-turn dialogue, retain conversation history, and support multiple languages, marking a significant departure from traditional ARMs.
此外,还分析了 remasking 策略和采样步骤对性能的影响。案例研究展示了 LLaDA 8B Instruct 生成流畅、扩展文本的能力,参与多轮对话,保留对话历史,并支持多种语言,这标志着与传统 ARM 的重大区别。




内容中包含的图片若涉及版权问题,请及时与我们联系删除
