


Artificial Intelligence is undergoing rapid evolution, especially regarding the training of massive language models (LLMs) with parameters exceeding 70 billion. These models have become indispensable for various tasks, including creative text generation, translation, and content creation. However, effectively harnessing the power of such advanced LLMs requires human input through a technique known as Reinforcement Learning from Human Feedback (RLHF). The main challenge arises from existing RLHF frameworks struggling to cope with the immense memory requirements of handling these colossal models, thereby limiting their full potential.
Current RLHF approaches often involve dividing the LLM across multiple GPUs for training, but this strategy is not without its drawbacks. Firstly, excessive partitioning can lead to memory fragmentation on individual GPUs, resulting in a reduced effective batch size for training and thus slowing down the overall process. Secondly, the communication overhead between the fragmented parts creates bottlenecks, analogous to a team constantly exchanging messages, which ultimately hinders efficiency.
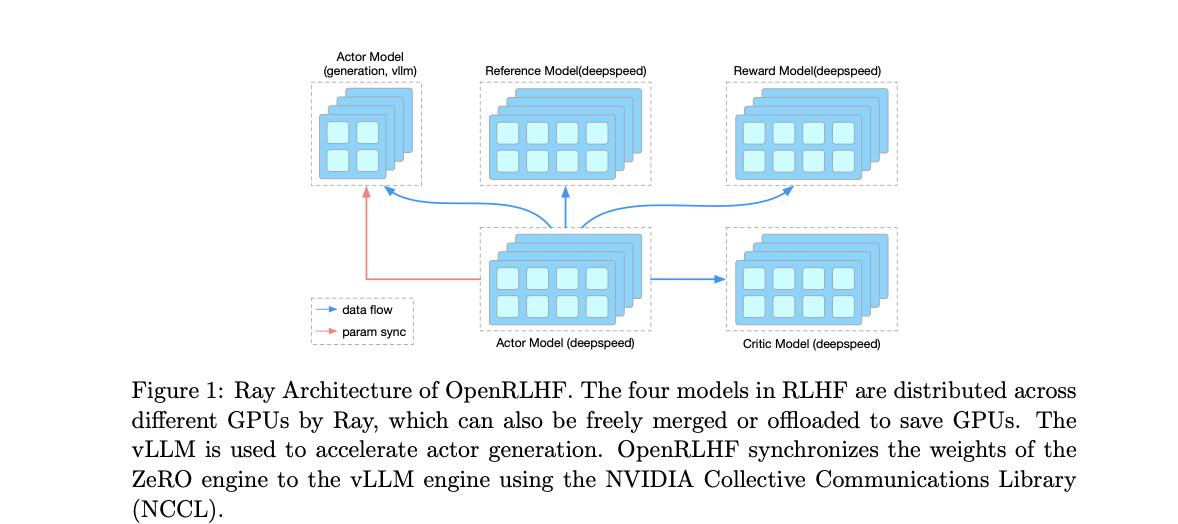
In response to these challenges, researchers propose a groundbreaking RLHF framework named OpenRLHF. OpenRLHF leverages two key technologies: Ray, the Distributed Task Scheduler, and vLLM, the Distributed Inference Engine. Ray functions as a sophisticated project manager, intelligently allocating the LLM across GPUs without excessive partitioning, thereby optimizing memory utilization and accelerating training by enabling larger batch sizes per GPU. Conversely, vLLM enhances computation speed by leveraging the parallel processing capabilities of multiple GPUs, akin to a network of high-performance computers collaborating on a complex problem.
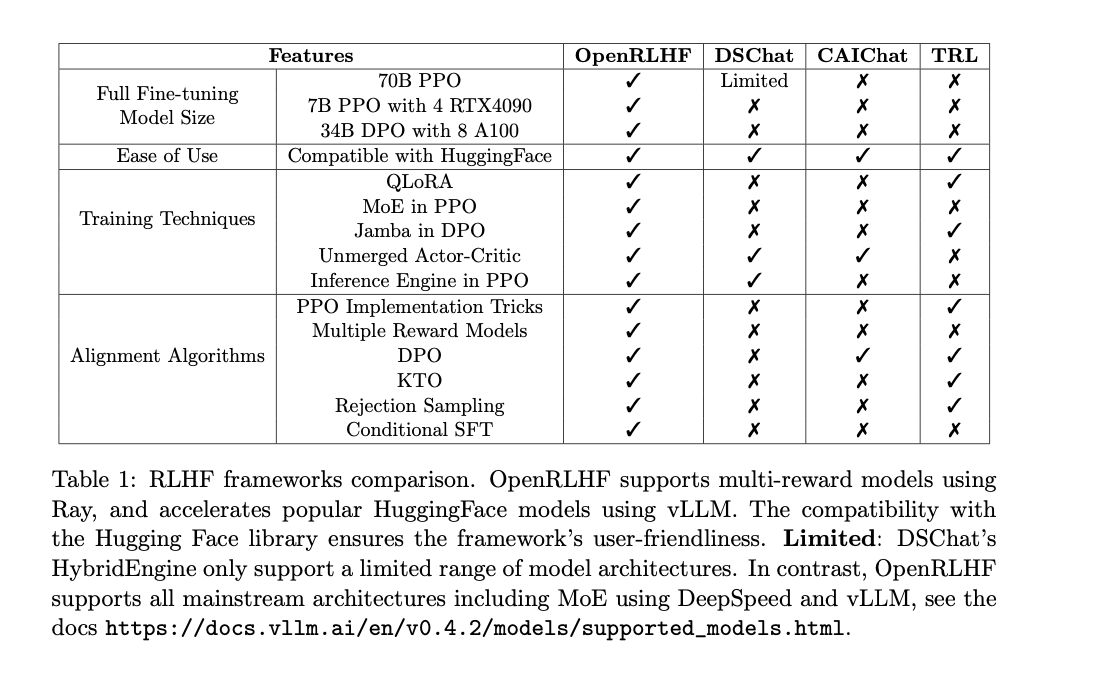
A detailed comparative analysis with an established framework like DSChat, conducted during the training of a massive 7B parameter LLaMA2 model, demonstrated significant improvements with OpenRLHF. It achieved faster training convergence, akin to a student grasping a concept quickly due to a more efficient learning approach. Moreover, vLLM’s rapid generation capabilities led to a substantial reduction in overall training time, akin to a manufacturing plant boosting production speed with a streamlined assembly line. Additionally, Ray’s intelligent scheduling minimized memory fragmentation, allowing for larger batch sizes and faster training.
In conclusion, OpenRLHF’s breakthrough not only addresses but dismantles the key roadblocks encountered in training colossal LLMs using RLHF. By harnessing the power of efficient scheduling and accelerated computations, it overcomes memory limitations and achieves faster training convergence. This opens up avenues for fine-tuning even larger LLMs with human feedback, heralding a new era of applications in language processing and information interaction that can potentially revolutionize various domains.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post OpenRLHF: An Open-Source AI Framework Enabling Efficient Reinforcement Learning from Human Feedback RLHF Scaling appeared first on MarkTechPost.
