
Amazon Bedrock Knowledge Bases is a fully managed capability that helps implement entire Retrieval Augmented Generation (RAG) workflows from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows.
There is no single way to optimize knowledge base performance: each use case is impacted differently by configuration parameters. As such, it’s important to test often and iterate quickly to identify the best configuration for each use case.
In this post, we discuss how to evaluate the performance of your knowledge base, including the metrics and data to use for evaluation. We also address some of the tactics and configuration changes that can improve specific metrics.
Measure the performance of your knowledge base
RAG is a complex AI system, combining several critical steps. In order to identify what is impacting the performance of the pipeline, it’s important to evaluate each step independently. The knowledge base evaluation framework decomposes the evaluation into the following stages:
- Retrieval – The process of retrieving relevant parts of documents based on a query and adding the retrieved elements as context to the final prompt for the knowledge base Generation – Sending the user’s prompt and the retrieved context to a large language model (LLM) and then sending the output from the LLM back to the user
The following diagram illustrates the standard steps in a RAG pipeline.

To see this evaluation framework in action, open the Amazon Bedrock console, and in the navigation pane, choose Evaluations. Choose the Knowledge Bases tab to review the evaluation.

Evaluate the retrieval
We recommend initially evaluating the retrieval process independently, because the accuracy and quality of this foundational stage can significantly impact downstream performance metrics in the RAG workflow, potentially introducing errors or biases that propagate through subsequent pipeline stages.

There are two metrics used to evaluate retrieval:
- Context relevance – Evaluates whether the retrieved information directly addresses the query’s intent. It focuses on precision of the retrieval system. Context coverage – Measures how comprehensively the retrieved texts cover the expected ground truth. It requires ground truth texts for comparison to assess recall and completeness of retrieved information.
Context relevance and context coverage metrics are compiled by comparing search results from the RAG pipeline with expected answers in the test dataset. The following diagram illustrates this workflow.
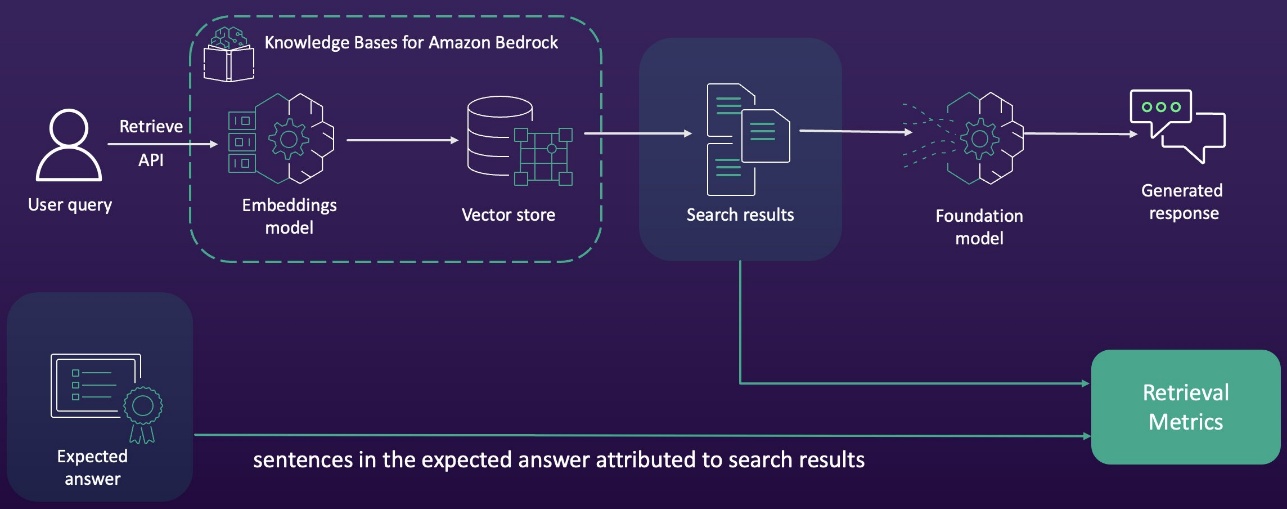
Running the evaluation requires you to bring a dataset that adheres to specific formatting guidelines. The dataset must be in JSON Lines format, with each line representing a valid JSON object. To maintain optimal performance, the dataset should be limited to a maximum of 1,000 prompts per evaluation. Each individual prompt within the dataset must be a well-structured, valid JSON object that can be properly parsed and processed by the evaluation system.
If you choose to evaluate for context coverage, you will need to provide a ground truth, which is text that serves as the baseline for measuring coverage. The ground truth must include referenceContexts, and each prompt in the ground truth must have corresponding reference contexts for accurate evaluation.
The following example code shows the required fields:
For more details, see Creating a prompt dataset for Retrieve only evaluation jobs.
Evaluate the generation
After validating that your RAG workflow successfully retrieves relevant context from your vector database and aligns with your predefined performance standards, you can proceed to evaluate the generation stage of your pipeline. The Amazon Bedrock evaluation tool provides a comprehensive assessment framework with eight metrics that cover both response quality and responsible AI considerations.
Response quality includes the following metrics:
- Helpfulness – Evaluates how useful and comprehensive the generated responses are in answering questions Correctness – Assesses the accuracy of responses to questions Logical coherence – Examines responses for logical gaps, inconsistencies, or contradictions Completeness – Evaluates whether responses address all aspects of the questions Faithfulness – Measures factual accuracy and resistance to hallucinations
Responsible AI includes the following metrics:
- Harmfulness – Evaluates responses for the presence of hate, insult, or violent content Stereotyping – Assesses for generalized statements about groups or individuals Refusal – Measures how appropriately the system declines to answer inappropriate questions
Response quality and responsible AI metrics are compiled by comparing search results and the generated response from the RAG pipeline with ground truth answers. The following diagram illustrates this workflow.

The dataset for evaluation must adhere to specific structural requirements, using JSON Lines format with a maximum of 1,000 prompts per evaluation. Each prompt is required to be a valid JSON object with a well-defined structure. Within this structure, two critical fields play essential roles: the prompt field contains the query text used for model evaluation, and the referenceResponses field stores the expected ground truth responses against which the model’s performance will be measured. This format promotes a standardized, consistent approach to evaluating model outputs across different test scenarios.
The following example code shows the required fields:
For more details, see Creating a prompt dataset for Retrieve and generate evaluation jobs.
The following screenshot shows an Amazon Bedrock evaluation results sample dashboard.

After processing, the evaluation provides comprehensive insights, delivering both aggregate metrics and granular performance breakdowns for each individual metric. These detailed results include sample conversations that illustrate performance nuances. To derive maximum value, we recommend conducting a qualitative review, particularly focusing on conversations that received low scores across any metrics. This deep-dive analysis can help you understand the underlying factors contributing to poor performance and inform strategic improvements to your RAG workflow.
Building a comprehensive test dataset: Strategies and considerations
Creating a robust test dataset is crucial for meaningful evaluation. In this section, we discuss three primary approaches to dataset development.
Human-annotated data collection
Human annotation remains the gold standard for domain-specific, high-quality datasets. You can:
- Use your organization’s proprietary documents and answers Use open-source document collections like Clueweb (a 10-billion web document repository) Employ professional data labeling services such as Amazon SageMaker Ground Truth Use a crowdsourcing marketplace like Amazon Mechanical Turk for distributed annotation
Human data annotation is recommended for domain-specific, high-quality, and nuanced results. However, generating and maintaining large datasets using human annotators is a time-consuming and costly approach.
Synthetic data generation using LLMs
Synthetic data generation offers a more automated, potentially cost-effective alternative with two primary methodologies:
- Self-instruct approach:
- Iterative process using a single target model Model generates multiple responses to queries Provides continuous feedback and refinement
- Uses multiple models Generates responses based on preexisting model training Enables faster dataset creation by using previously trained models
Synthetic data generation requires careful navigation of several key considerations. Organizations must typically secure End User License Agreements and might need access to multiple LLMs. Although the process demands minimal human expert validation, these strategic requirements underscore the complexity of generating synthetic datasets efficiently. This approach offers a streamlined alternative to traditional data annotation methods, balancing legal compliance with technical innovation.
Continuous dataset improvement: The feedback loop strategy
Develop a dynamic, iterative approach to dataset enhancement that transforms user interactions into valuable learning opportunities. Begin with your existing data as a foundational baseline, then implement a robust user feedback mechanism that systematically captures and evaluates real-world model interactions. Establish a structured process for reviewing and integrating flagged responses, treating each piece of feedback as a potential refinement point for your dataset. For an example of such a feedback loop implemented in AWS, refer to Improve LLM performance with human and AI feedback on Amazon SageMaker for Amazon Engineering.
This approach transforms dataset development from a static, one-time effort into a living, adaptive system. By continuously expanding and refining your dataset through user-driven insights, you create a self-improving mechanism that progressively enhances model performance and evaluation metrics. Remember: dataset evolution is not a destination, but an ongoing journey of incremental optimization.
When developing your test dataset, strive for a strategic balance that precisely represents the range of scenarios your users will encounter. The dataset should comprehensively span potential use cases and edge cases, while avoiding unnecessary repetition. Because each evaluation example incurs a cost, focus on creating a dataset that maximizes insights and performance understanding, selecting examples that reveal unique model behaviors rather than redundant iterations. The goal is to craft a targeted, efficient dataset that provides meaningful performance assessment without wasting resources on superfluous testing.
Performance improvement tools
Comprehensive evaluation metrics are more than just performance indicators—they’re a strategic roadmap for continuous improvement in your RAG pipeline. These metrics provide critical insights that transform abstract performance data into actionable intelligence, enabling you to do the following:
- Diagnose specific pipeline weaknesses Prioritize improvement efforts Objectively assess knowledge base readiness Make data-driven optimization decisions
By systematically analyzing your metrics, you can definitively answer key questions: Is your knowledge base robust enough for deployment? What specific components require refinement? Where should you focus your optimization efforts for maximum impact?
Think of metrics as a diagnostic tool that illuminates the path from current performance to exceptional AI system reliability. They don’t just measure—they guide, providing a clear, quantitative framework for strategic enhancement.
Although a truly comprehensive exploration of RAG pipeline optimization would require an extensive treatise, this post offers a systematic framework for transformative improvements across critical dimensions.
Data foundation and preprocessing
Data foundation and preprocessing consists of the following best practices:
- Clean and preprocess source documents to improve quality, removing noise, standardizing formats, and maintaining data consistency Augment training data with relevant external sources, expanding dataset diversity and coverage Implement named entity recognition and linking to improve retrieval, enhancing semantic understanding and context identification Use text summarization techniques to condense long documents, reducing complexity while preserving key information
Chunking strategies
Consider the following chunking strategies:
- Use semantic chunking instead of fixed-size chunking to preserve context, maintaining meaningful information boundaries. Explore various chunk sizes (128–1,024 characters), adapting to semantic text structure and reserving meaning through intelligent segmentation. For more details on Amazon Bedrock chunking strategies, see How content chunking works for knowledge bases. Implement sliding window chunking with overlap, minimizing information loss between chunks, typically 10–20% overlap to provide contextual continuity. Consider hierarchical chunking for long documents, capturing both local and global contextual nuances.
Embedding techniques
Embedding techniques include the following:
- If your text contains multiple languages, you might want to try using the Cohere Embed (Multilingual) embedding model. This could improve semantic understanding and retrieval relevance. Experiment with embedding dimensions, balancing performance and computational efficiency. Implement sentence or paragraph embeddings, moving beyond word-level representations.
Retrieval optimization
Consider the following best practices for retrieval optimization:
- Statically or dynamically adjust the number of retrieved chunks, optimizing information density. In your RetrieveAndGenerate (or Retrieve) request, modify
"retrievalConfiguration": { "vectorSearchConfiguration": { "numberOfResults": NUMBER }}. Implement metadata filtering, adding contextual layers to chunk retrieval. For example, prioritizing recent information in time-sensitive scenarios. For code samples for metadata filtering using Amazon Bedrock Knowledge Bases, refer to the following GitHub repo. Use hybrid search combining dense and sparse retrieval, blending semantic and keyword search approaches. Apply reranking models to improve precision, reorganizing retrieved contexts by relevance. Experiment with diverse similarity metrics, exploring beyond standard cosine similarity. Implement query expansion techniques, transforming queries for more effective retrieval. One example is query decomposition, breaking complex queries into targeted sub-questions. The following screenshot shows these options on the Amazon Bedrock console.

Prompt engineering
After you select a model, you can edit the prompt template:
- Design context-aware prompts, explicitly guiding models to use retrieved information Implement few-shot prompting, using dynamic, query-matched examples Create dynamic prompts based on query and documents, adapting instruction strategy contextually Include explicit usage instructions for retrieved information, achieving faithful and precise response generation
The following screenshot shows an example of editing the prompt template on the Amazon Bedrock console.

Model selection and guardrails
When choosing your model and guardrails, consider the following:
- Choose LLMs based on specific task requirements, aligning model capabilities with the use case Fine-tune models on domain-specific data, enhancing specialized performance Experiment with model sizes, balancing performance and computational efficiency Consider specialized model configurations, using smaller models for retrieval and larger for generation Implement contextual grounding checks, making sure responses remain true to provided information, such as contextual grounding with Amazon Bedrock Guardrails (see the following screenshot) Explore advanced search paradigms, such as knowledge graph search (GraphRAG)
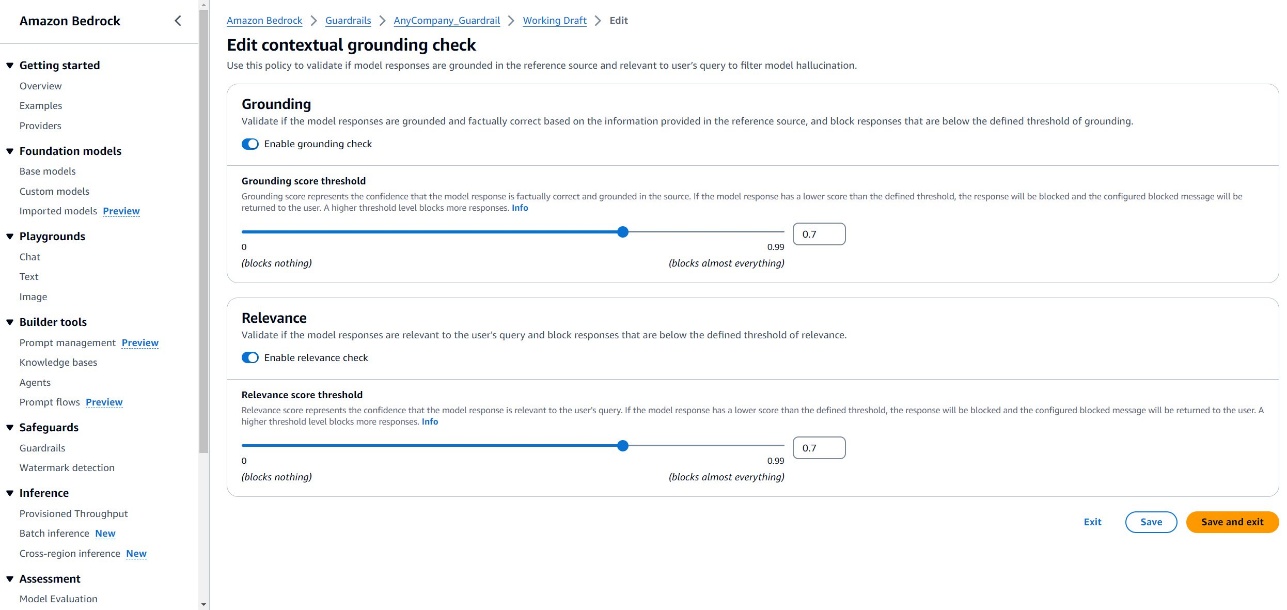
Navigating knowledge base improvements: Key considerations
When optimizing a RAG system, understanding your performance requirements is crucial. The acceptable performance bar depends entirely on your application’s context—whether it’s an internal tool, a system augmenting human workers, or a customer-facing service. A 0.95 metric score might be sufficient for some applications, where 1 in 20 answers could have minor inaccuracies, but potentially unacceptable for high-stakes scenarios. The key is to align your optimization efforts with the specific reliability and precision needs of your particular use case.
Another key is to prioritize refining the retrieval mechanism before addressing generation. Upstream performance directly influences downstream metrics, making retrieval optimization critical. Certain techniques, particularly chunking strategies, have nuanced impacts across both stages. For instance, increasing chunk size can improve retrieval efficiency by reducing search complexity, but simultaneously risks introducing irrelevant details that might compromise the generation’s correctness. This delicate balance requires careful, incremental adjustments to make sure both retrieval precision and response quality are systematically enhanced.
The following figure illustrates the aforementioned tools and how they relate to retrieval, generation, and both.

Diagnose the issue
When targeting a specific performance metric, adopt a forensic, human-centric approach to diagnosis. Treat your AI system like a colleague whose work requires thoughtful, constructive feedback. This includes the following steps:
- Failure pattern identification:
- Systematically map question types that consistently underperform Identify specific characteristics triggering poor performance, such as:
- List-based queries Specialized vocabulary domains Complex topic intersections
- Conduct granular chunk relevance analysis Quantify irrelevant or incorrect retrieved contexts Map precision distribution within the retrieved set (for example, the first 5 out of 15 chunks are relevant, the subsequent 10 are not) Understand retrieval mechanism’s contextual discrimination capabilities
- Rigorously compare generated responses against reference answers Diagnose potential ground truth limitations Develop targeted improvement instructions—think about what specific guidance would enhance response accuracy, and which nuanced context might be missing
Develop a strategic approach to improvement
When confronting complex RAG pipeline challenges, adopt a methodical, strategic approach that transforms performance optimization from a daunting task into a systematic journey of incremental enhancement.
The key is to identify tactics with direct, measurable impact on your specific target metric, concentrating on optimization points that offer the highest potential return on effort. This means carefully analyzing each potential strategy through the lens of its probable performance improvement, focusing on techniques that can deliver meaningful gains with minimal systemic disruption. The following figure illustrates which sets of techniques to prioritize when working to improve metrics.

Additionally, you should prioritize low-friction optimization tactics, such as configurable parameters in your knowledge base, or implementations that have minimal infrastructure disruption. It’s recommended to avoid full vector database reimplementation unless necessary.
You should take a lean approach—make your RAG pipeline improvement into a methodical, scientific process of continuous refinement. Embrace an approach of strategic incrementalism: make purposeful, targeted adjustments that are small enough to be precisely measured, yet meaningful enough to drive performance forward.
Each modification becomes an experimental intervention, rigorously tested to understand its specific impact. Implement a comprehensive version tracking system that captures not just the changes made, but the rationale behind each adjustment, the performance metrics before and after, and the insights gained.
Lastly, approach performance evaluation with a holistic, empathetic methodology that transcends mere quantitative metrics. Treat the assessment process as a collaborative dialogue of growth and understanding, mirroring the nuanced approach you would take when coaching a talented team member. Instead of reducing performance to cold, numerical indicators, seek to uncover the underlying dynamics, contextual challenges, and potential for development. Recognize that meaningful evaluation goes beyond surface-level measurements, requiring deep insight into capabilities, limitations, and the unique context of performance.
Conclusion
Optimizing Amazon Bedrock Knowledge Bases for RAG is an iterative process that requires systematic testing and refinement. Success comes from methodically using techniques like prompt engineering and chunking to improve both the retrieval and generation stages of RAG. By tracking key metrics throughout this process, you can measure the impact of your optimizations and ensure they meet your application’s requirements.
To learn more about optimizing your Amazon Bedrock Knowledge Bases, see our guide on how to Evaluate the performance of Amazon Bedrock resources.
About the Authors
 Clement Perrot is a Senior Solutions Architect and AI/ML Specialist at AWS, where he helps early-stage startups build and use AI on the AWS platform. Prior to AWS, Clement was an entrepreneur, whose last two AI and consumer hardware startups were acquired.
Clement Perrot is a Senior Solutions Architect and AI/ML Specialist at AWS, where he helps early-stage startups build and use AI on the AWS platform. Prior to AWS, Clement was an entrepreneur, whose last two AI and consumer hardware startups were acquired.
 Miriam Lebowitz is a Solutions Architect focused on empowering early-stage startups at AWS. She uses her experience with AI/ML to guide companies to select and implement the right technologies for their business objectives, setting them up for scalable growth and innovation in the competitive startup world.
Miriam Lebowitz is a Solutions Architect focused on empowering early-stage startups at AWS. She uses her experience with AI/ML to guide companies to select and implement the right technologies for their business objectives, setting them up for scalable growth and innovation in the competitive startup world.
 Tamil Sambasivam is a Solutions Architect and AI/ML Specialist at AWS. She helps enterprise customers to solve their business problems by recommending the right AWS solutions. Her strong back ground in Information Technology (24+ years of experience) helps customers to strategize, develop and modernize their business problems in AWS cloud. In the spare time, Tamil like to travel and gardening.
Tamil Sambasivam is a Solutions Architect and AI/ML Specialist at AWS. She helps enterprise customers to solve their business problems by recommending the right AWS solutions. Her strong back ground in Information Technology (24+ years of experience) helps customers to strategize, develop and modernize their business problems in AWS cloud. In the spare time, Tamil like to travel and gardening.
