
We deployed 100 reinforcement learning (RL)-controlled cars into rush-hour highway traffic to smooth congestion and reduce fuel consumption for everyone. Our goal is to tackle "stop-and-go" waves, those frustrating slowdowns and speedups that usually have no clear cause but lead to congestion and significant energy waste. To train efficient flow-smoothing controllers, we built fast, data-driven simulations that RL agents interact with, learning to maximize energy efficiency while maintaining throughput and operating safely around human drivers.
Overall, a small proportion of well-controlled autonomous vehicles (AVs) is enough to significantly improve traffic flow and fuel efficiency for all drivers on the road. Moreover, the trained controllers are designed to be deployable on most modern vehicles, operating in a decentralized manner and relying on standard radar sensors. In our latest paper, we explore the challenges of deploying RL controllers on a large-scale, from simulation to the field, during this 100-car experiment.
The challenges of phantom jams

A stop-and-go wave moving backwards through highway traffic.
If you drive, you’ve surely experienced the frustration of stop-and-go waves, those seemingly inexplicable traffic slowdowns that appear out of nowhere and then suddenly clear up. These waves are often caused by small fluctuations in our driving behavior that get amplified through the flow of traffic. We naturally adjust our speed based on the vehicle in front of us. If the gap opens, we speed up to keep up. If they brake, we also slow down. But due to our nonzero reaction time, we might brake just a bit harder than the vehicle in front. The next driver behind us does the same, and this keeps amplifying. Over time, what started as an insignificant slowdown turns into a full stop further back in traffic. These waves move backward through the traffic stream, leading to significant drops in energy efficiency due to frequent accelerations, accompanied by increased CO2 emissions and accident risk.
And this isn’t an isolated phenomenon! These waves are ubiquitous on busy roads when the traffic density exceeds a critical threshold. So how can we address this problem? Traditional approaches like ramp metering and variable speed limits attempt to manage traffic flow, but they often require costly infrastructure and centralized coordination. A more scalable approach is to use AVs, which can dynamically adjust their driving behavior in real-time. However, simply inserting AVs among human drivers isn’t enough: they must also drive in a smarter way that makes traffic better for everyone, which is where RL comes in.
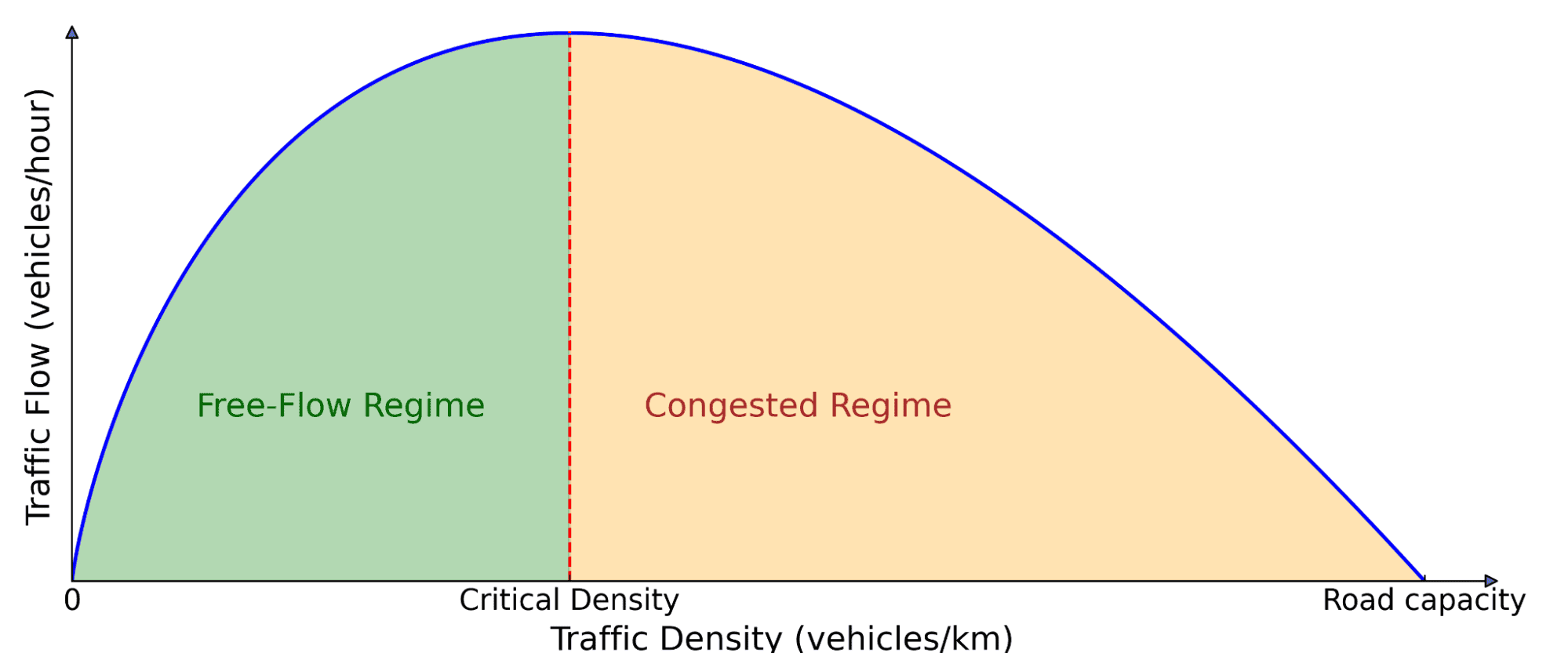
Fundamental diagram of traffic flow. The number of cars on the road (density) affects how much traffic is moving forward (flow). At low density, adding more cars increases flow because more vehicles can pass through. But beyond a critical threshold, cars start blocking each other, leading to congestion, where adding more cars actually slows down overall movement.
Reinforcement learning for wave-smoothing AVs
RL is a powerful control approach where an agent learns to maximize a reward signal through interactions with an environment. The agent collects experience through trial and error, learns from its mistakes, and improves over time. In our case, the environment is a mixed-autonomy traffic scenario, where AVs learn driving strategies to dampen stop-and-go waves and reduce fuel consumption for both themselves and nearby human-driven vehicles.
Training these RL agents requires fast simulations with realistic traffic dynamics that can replicate highway stop-and-go behavior. To achieve this, we leveraged experimental data collected on Interstate 24 (I-24) near Nashville, Tennessee, and used it to build simulations where vehicles replay highway trajectories, creating unstable traffic that AVs driving behind them learn to smooth out.
Simulation replaying a highway trajectory that exhibits several stop-and-go waves.
We designed the AVs with deployment in mind, ensuring that they can operate using only basic sensor information about themselves and the vehicle in front. The observations consist of the AV’s speed, the speed of the leading vehicle, and the space gap between them. Given these inputs, the RL agent then prescribes either an instantaneous acceleration or a desired speed for the AV. The key advantage of using only these local measurements is that the RL controllers can be deployed on most modern vehicles in a decentralized way, without requiring additional infrastructure.
Reward design
The most challenging part is designing a reward function that, when maximized, aligns with the different objectives that we desire the AVs to achieve:
- Wave smoothing: Reduce stop-and-go oscillations. Energy efficiency: Lower fuel consumption for all vehicles, not just AVs. Safety: Ensure reasonable following distances and avoid abrupt braking. Driving comfort: Avoid aggressive accelerations and decelerations. Adherence to human driving norms: Ensure a “normal” driving behavior that doesn’t make surrounding drivers uncomfortable.
Balancing these objectives together is difficult, as suitable coefficients for each term must be found. For instance, if minimizing fuel consumption dominates the reward, RL AVs learn to come to a stop in the middle of the highway because that is energy optimal. To prevent this, we introduced dynamic minimum and maximum gap thresholds to ensure safe and reasonable behavior while optimizing fuel efficiency. We also penalized the fuel consumption of human-driven vehicles behind the AV to discourage it from learning a selfish behavior that optimizes energy savings for the AV at the expense of surrounding traffic. Overall, we aim to strike a balance between energy savings and having a reasonable and safe driving behavior.
Simulation results
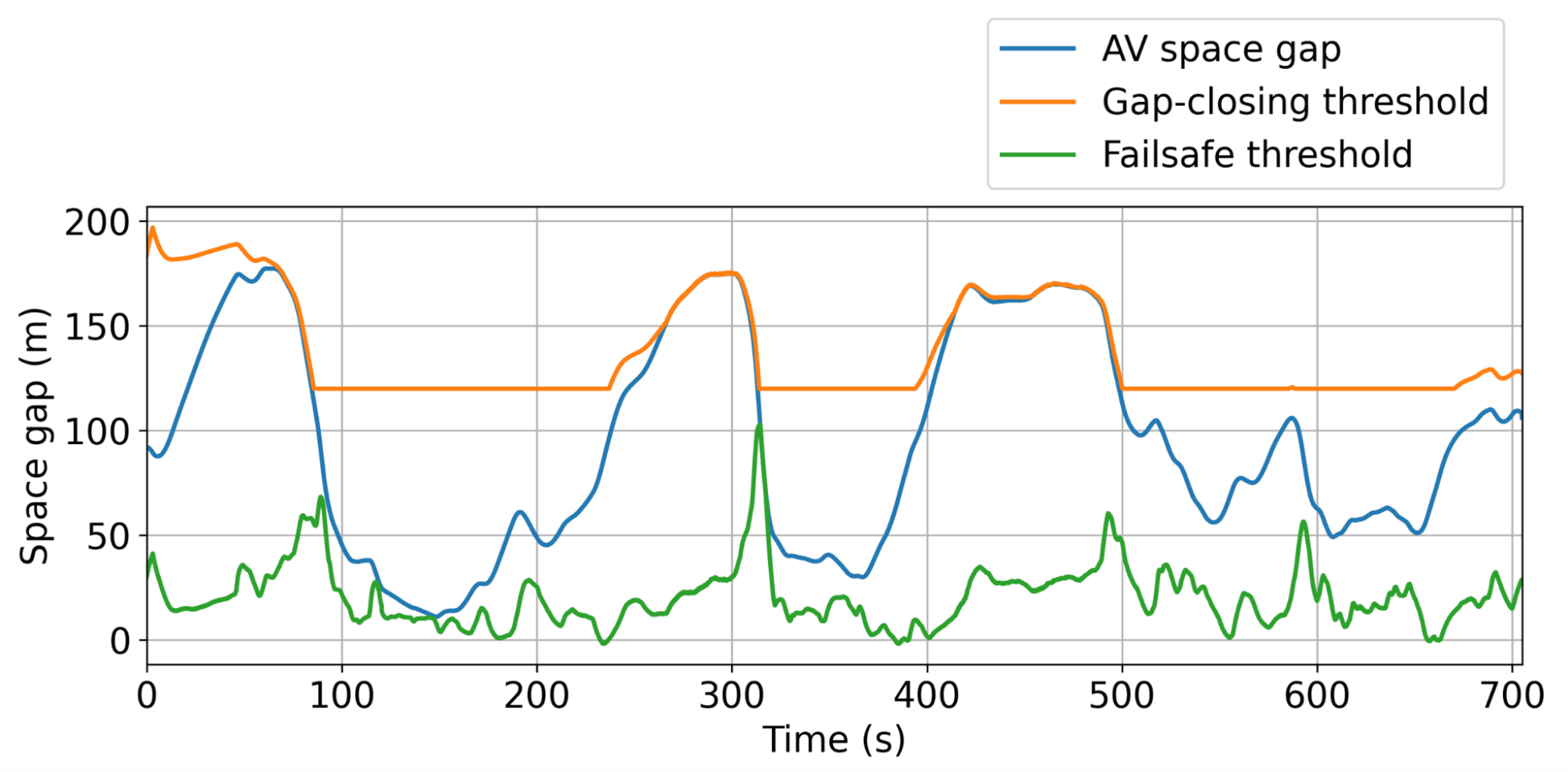
Illustration of the dynamic minimum and maximum gap thresholds, within which the AV can operate freely to smooth traffic as efficiently as possible.
The typical behavior learned by the AVs is to maintain slightly larger gaps than human drivers, allowing them to absorb upcoming, possibly abrupt, traffic slowdowns more effectively. In simulation, this approach resulted in significant fuel savings of up to 20% across all road users in the most congested scenarios, with fewer than 5% of AVs on the road. And these AVs don’t have to be special vehicles! They can simply be standard consumer cars equipped with a smart adaptive cruise control (ACC), which is what we tested at scale.
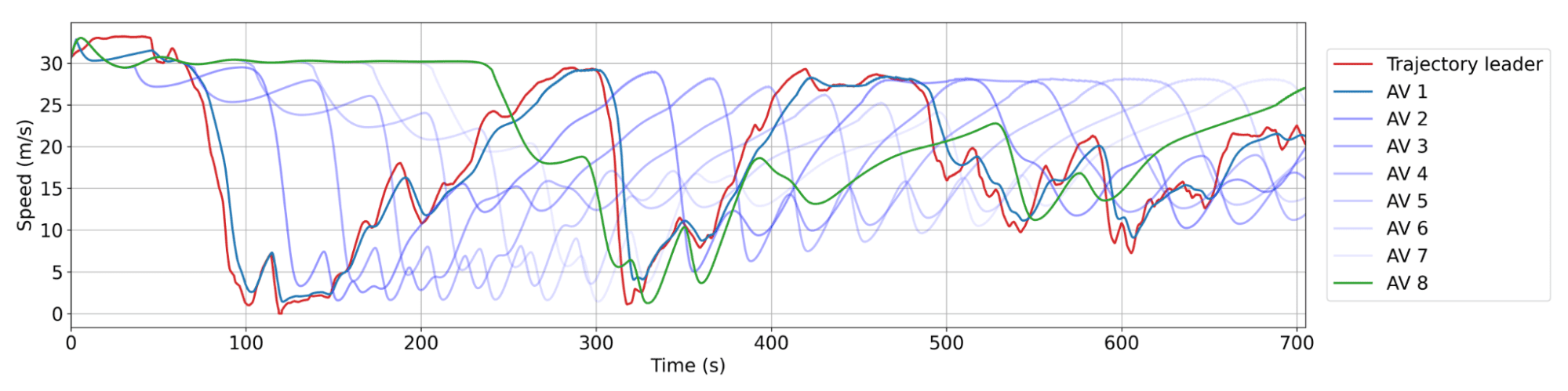 Smoothing behavior of RL AVs. Red: a human trajectory from the dataset. Blue: successive AVs in the platoon, where AV 1 is the closest behind the human trajectory. There is typically between 20 and 25 human vehicles between AVs. Each AV doesn’t slow down as much or accelerate as fast as its leader, leading to decreasing wave amplitude over time and thus energy savings.
Smoothing behavior of RL AVs. Red: a human trajectory from the dataset. Blue: successive AVs in the platoon, where AV 1 is the closest behind the human trajectory. There is typically between 20 and 25 human vehicles between AVs. Each AV doesn’t slow down as much or accelerate as fast as its leader, leading to decreasing wave amplitude over time and thus energy savings.
100 AV field test: deploying RL at scale


Our 100 cars parked at our operational center during the experiment week.
Given the promising simulation results, the natural next step was to bridge the gap from simulation to the highway. We took the trained RL controllers and deployed them on 100 vehicles on the I-24 during peak traffic hours over several days. This large-scale experiment, which we called the MegaVanderTest, is the largest mixed-autonomy traffic-smoothing experiment ever conducted.
Before deploying RL controllers in the field, we trained and evaluated them extensively in simulation and validated them on the hardware. Overall, the steps towards deployment involved:
- Training in data-driven simulations: We used highway traffic data from I-24 to create a training environment with realistic wave dynamics, then validate the trained agent’s performance and robustness in a variety of new traffic scenarios. Deployment on hardware: After being validated in robotics software, the trained controller is uploaded onto the car and is able to control the set speed of the vehicle. We operate through the vehicle’s on-board cruise control, which acts as a lower-level safety controller. Modular control framework: One key challenge during the test was not having access to the leading vehicle information sensors. To overcome this, the RL controller was integrated into a hierarchical system, the MegaController, which combines a speed planner guide that accounts for downstream traffic conditions, with the RL controller as the final decision maker. Validation on hardware: The RL agents were designed to operate in an environment where most vehicles were human-driven, requiring robust policies that adapt to unpredictable behavior. We verify this by driving the RL-controlled vehicles on the road under careful human supervision, making changes to the control based on feedback.
 Each of the 100 cars is connected to a Raspberry Pi, on which the RL controller (a small neural network) is deployed.
Each of the 100 cars is connected to a Raspberry Pi, on which the RL controller (a small neural network) is deployed.  The RL controller directly controls the onboard adaptive cruise control (ACC) system, setting its speed and desired following distance.
The RL controller directly controls the onboard adaptive cruise control (ACC) system, setting its speed and desired following distance. Once validated, the RL controllers were deployed on 100 cars and driven on I-24 during morning rush hour. Surrounding traffic was unaware of the experiment, ensuring unbiased driver behavior. Data was collected during the experiment from dozens of overhead cameras placed along the highway, which led to the extraction of millions of individual vehicle trajectories through a computer vision pipeline. Metrics computed on these trajectories indicate a trend of reduced fuel consumption around AVs, as expected from simulation results and previous smaller validation deployments. For instance, we can observe that the closer people are driving behind our AVs, the less fuel they appear to consume on average (which is calculated using a calibrated energy model):
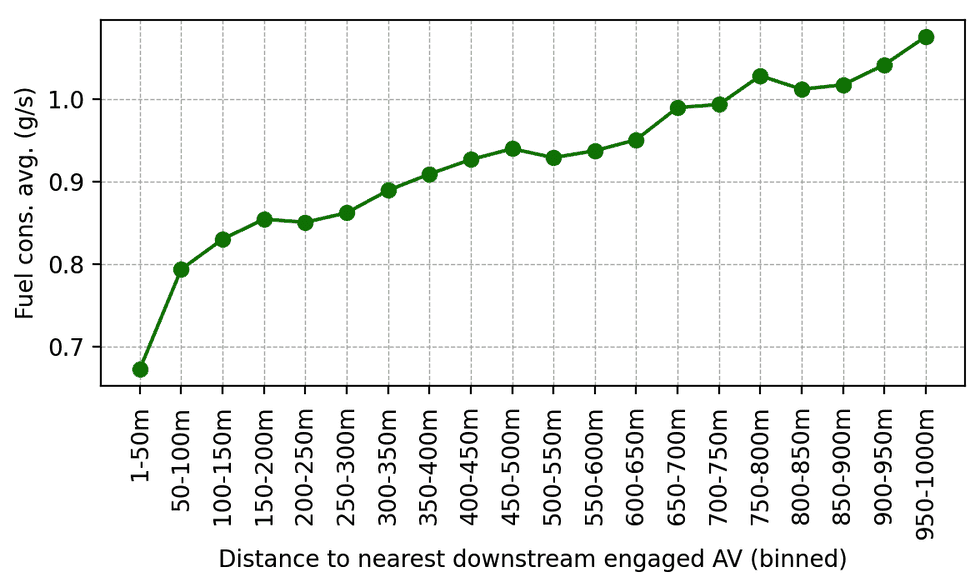
Average fuel consumption as a function of distance behind the nearest engaged RL-controlled AV in the downstream traffic. As human drivers get further away behind AVs, their average fuel consumption increases.
Another way to measure the impact is to measure the variance of the speeds and accelerations: the lower the variance, the less amplitude the waves should have, which is what we observe from the field test data. Overall, although getting precise measurements from a large amount of camera video data is complicated, we observe a trend of 15 to 20% of energy savings around our controlled cars.
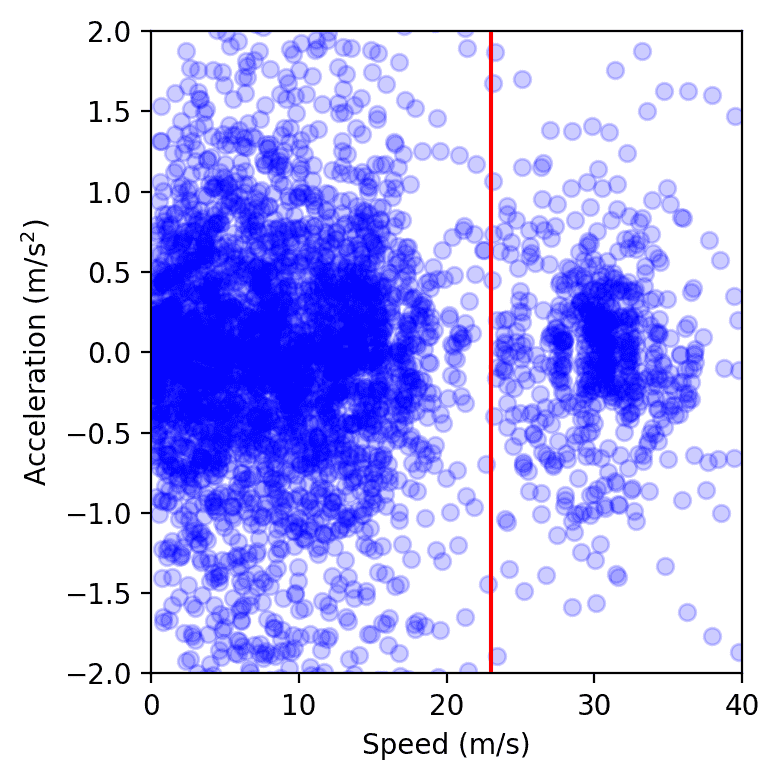
Data points from all vehicles on the highway over a single day of the experiment, plotted in speed-acceleration space. The cluster to the left of the red line represents congestion, while the one on the right corresponds to free flow. We observe that the congestion cluster is smaller when AVs are present, as measured by computing the area of a soft convex envelope or by fitting a Gaussian kernel.
Final thoughts
The 100-car field operational test was decentralized, with no explicit cooperation or communication between AVs, reflective of current autonomy deployment, and bringing us one step closer to smoother, more energy-efficient highways. Yet, there is still vast potential for improvement. Scaling up simulations to be faster and more accurate with better human-driving models is crucial for bridging the simulation-to-reality gap. Equipping AVs with additional traffic data, whether through advanced sensors or centralized planning, could further improve the performance of the controllers. For instance, while multi-agent RL is promising for improving cooperative control strategies, it remains an open question how enabling explicit communication between AVs over 5G networks could further improve stability and further mitigate stop-and-go waves. Crucially, our controllers integrate seamlessly with existing adaptive cruise control (ACC) systems, making field deployment feasible at scale. The more vehicles equipped with smart traffic-smoothing control, the fewer waves we’ll see on our roads, meaning less pollution and fuel savings for everyone!
Many contributors took part in making the MegaVanderTest happen! The full list is available on the CIRCLES project page, along with more details about the project.
Read more: [paper]
