腾讯正式发布了基于混合Mamba-Transformer架构的超大型推理模型“混元T1”,并在腾讯云上线。该模型融合了Mamba在长序列处理上的优势与Transformer在复杂上下文捕捉上的能力,降低了推理成本和KV-Cache占用。混元T1在速度和生成效果上均表现出色,吐字速度达60~80 token/s,在多个公开数据集上的表现与DeepSeek R1和OpenAI o1相当或略胜一筹。目前,混元T1已在腾讯云面向API用户开放,价格极具竞争力,未来或将通过元宝等业务向C端用户开放。
🚀 混元T1的核心技术在于其混合架构,结合了Mamba在长序列处理上的优势与Transformer在复杂上下文捕捉上的能力,从而降低了推理成本和KV-Cache占用。
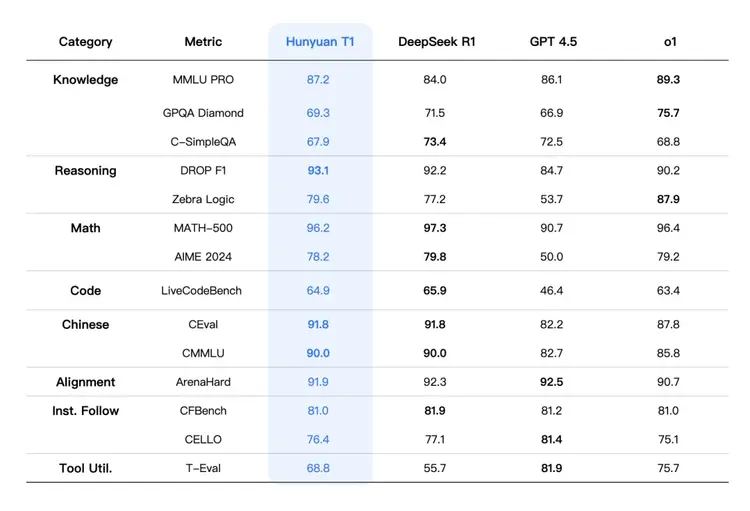
💨 在性能方面,混元T1的吐字速度达到60~80 token/s,生成效果远快于DeepSeek R1。同时,在MMLU-pro、CEval、AIME和Zebra Logic等中英文知识和竞赛级数学、逻辑推理测试中,T1已跻身顶级大模型行列。
💰 混元T1的定价策略极具竞争力,输入价格为1元/百万tokens,输出价格为4元/百万tokens,约为DeepSeek R1标准时段价格的四分之一,接近DeepSeek R1优惠时段水平。
🌍 混元T1的基础模型Turbo S在全球大模型竞技场中进入TOP 15,表明其在全球范围内的竞争力。目前,T1正式版已在腾讯云面向API用户开放,未来可能更多通过元宝和其他自家业务向C端用户开放。
昨晚深夜,腾讯宣布推出基于混合Mamba-Transformer架构的超大型推理模型“混元T1”正式版,并在腾讯云官网上线。T1是腾讯自研的强推理模型。该模型的前身是今年2月中旬在腾讯元宝APP上线的T1-Preview(Hunyuan-Thinker-1-Preview)。

据悉,技术层面,混元T1结合Mamba在长序列处理上的优势与Transformer在复杂上下文捕捉上的能力,降低了推理成本和KV-Cache占用。腾讯未披露更多技术细节,但Mamba-2研究表明,Transformer中的注意力机制与SSM(结构化状态空间模型)之间存在数学联系,这为融合模式的实现奠定了基础。
据介绍,T1的吐字速度能达到60~80 token/s,在生成效果上远快于DeepSeek R1。

此外,腾讯还表示,混元T1在多个公开数据集上的表现与DeepSeek R1和OpenAI o1相当或略胜一筹。在MMLU-pro、CEval、AIME和Zebra Logic等中英文知识和竞赛级数学、逻辑推理测试中,T1已跻身顶级大模型行列。此外,T1的基础模型Turbo S已在全球大模型竞技场中进入TOP 15。

T1正式版已在腾讯云面向API用户开放,输入价格为1元/百万tokens,输出价格为4元/百万tokens,约为DeepSeek R1标准时段价格的四分之一,接近DeepSeek R1优惠时段水平。
腾讯表示,T1未来可能更多通过元宝和其他自家业务向C端用户开放。

