

我们希望 MindVLA 能为自动驾驶车赋予类似人类的认知和适应能力,将其转变为能够思考的智能体。就像 iPhone 重新定义了手机,MindVLA 也将重新定义自动驾驶。
3月份的新车和新技术铺天盖地,各家车企你追我赶,让人目不暇接,甚至产生了新品一经发布就已落后的错觉。
这不,就在近日,理想在 NVDIA GTC 2025 上分享了自家 MindVLA 技术的最新进展,声称要「像 iPhone 4 重新定义手机一样,重新定义自动驾驶」。
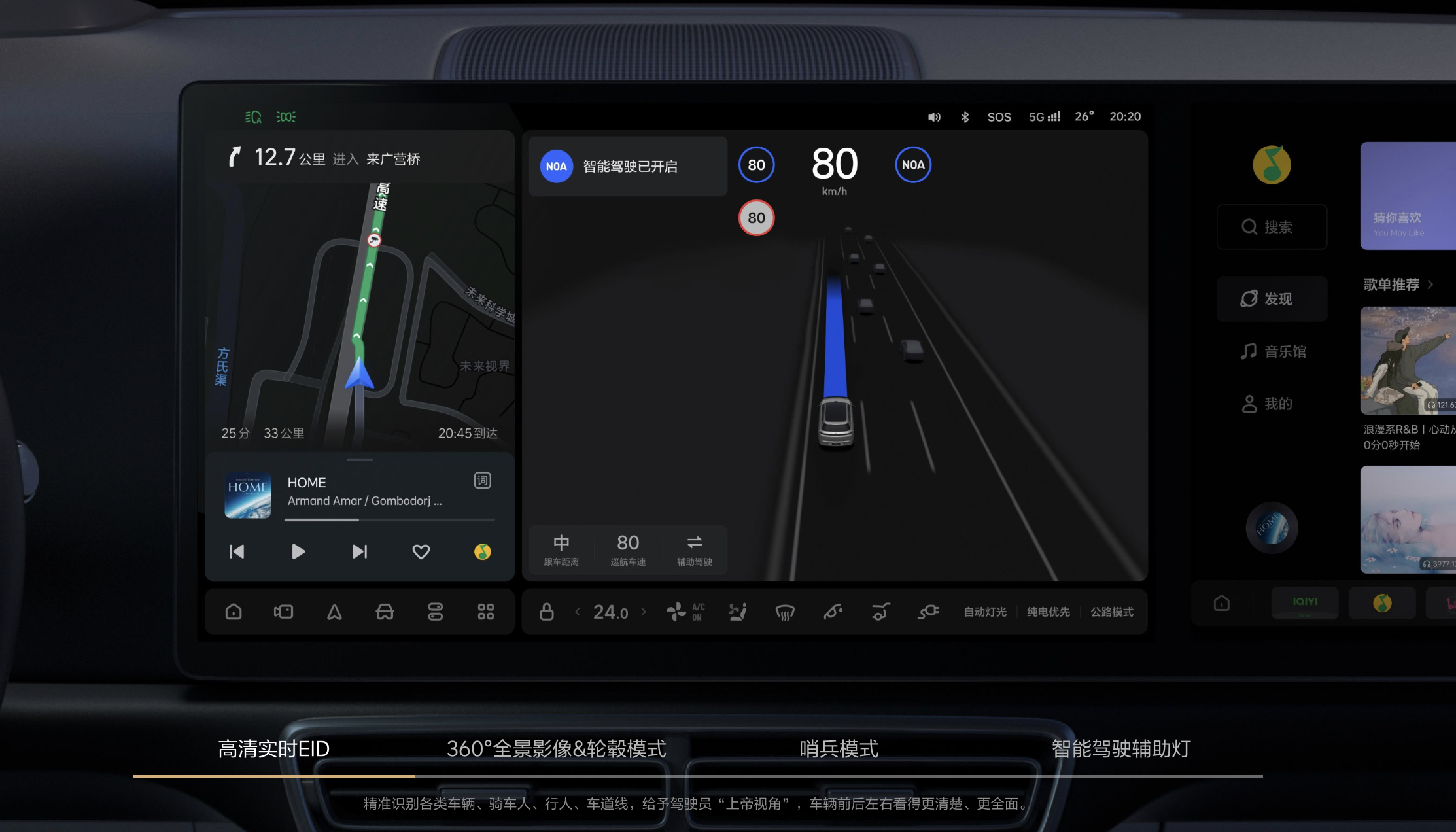
撇开复杂的技术原理和实现方式不谈,理想 MindVLA 技术的最大价值在于将车辆用户体验提升到了全新的高度。
分享会上,理想用一句话总结了新智驾系统的能力——这套全新的智驾系统将成为每个人的专职司机。
这位专职司机能做到哪些事情呢?我想到了以下几个场景:早上从车库把车开到家门口接我,省去我下楼去地库取车的麻烦;到公司门口放我下车后,自动寻找车位停好,不用我四处找车位;当我要去商场或咖啡厅时,自动寻找合适的目的地,无需我手动选择导航。最关键的是,它能定位到我所在的位置,自动来接我。
理想将这些场景概括为三个词——「听得懂」、「看得见」、「找得到」。

「听得懂」意味着用户可以通过语音指令改变车辆的路线和行为。这不仅将车机的语音互动从空调、座椅等座舱功能扩展到了具体的驾驶操作,更让用户成为副驾驶,能够”教导”车机向左转、向右转或加快速度。
「看得见」指的是 MindVLA 具备出色的通识能力,可以识别周边的商店招牌和标志性地点。理想举例说明:当用户在陌生地点找不到车辆时,只需拍摄一张周边环境的照片发送给车辆,搭载 MindVLA 的车辆就能识别照片中的位置,自动找到用户。
「找得到」主要应用于停车和园区漫游场景。最典型的例子是在地库寻找车位时,用户只需对车辆说:「去找个车位停好」,车辆就会自主搜寻可用车位,而且整个过程无需依赖地图或导航信息。

「专职司机」看起来在园区和地库场景表现的不错,那么理想如何确保它在公开道路上也游刃有余呢?
众所周知,国内的道路情况十分复杂,除了到处乱窜的电动车和高强度的人车博弈外,还有以下几个特点。
一是公交车道的广泛使用。这些车道的标识方式和使用规则极为多样,包括地面文字标识、空中指示牌和路边标牌。不同区域会用不同的文字形式说明时段限制,且经常会出现新增的公交车道,或因施工导致的标识模糊。
二是近年来各大城市出现的动态可调车道和潮汐车道,以及为充分利用路口空间而设置的待转区、待行区。这些区域的使用时机由各类信号灯或 LED 文字牌控制,且设备每天都可能面临新增、故障或维护情况。

因此在中国,自动驾驶系统不仅要应对复杂的人车互动,还需要具备文字理解能力、常识判断和强大的逻辑推理能力。
特斯拉近期推送的 FSD 就因在这些场景中表现欠佳而饱受批评。
为应对这些挑战,理想采用了双系统框架作为解决方案。
简单来说,理想将模型分为两个系统:快思考(系统 1)和慢思考(系统 2)。 车端通过端到端模型实现快系统。这是一个单一模型,可直接将传感器输入转换为驾驶轨迹输出,类似于人类的直觉反应。该系统通过模仿人类驾驶行为来应对各种场景,完全基于数据驱动,无需人为设定规则,也不依赖任何高精地图或先验信息。它具有极高的训练和执行效率。
慢系统则依托于一个 2.2B 参数规模的视觉语言大模型(VLM)。在需要文字理解、常识判断和逻辑推理的场景中,VLM通过思维链(Chain of Thought, COT)进行深入分析,作出驾驶决策,并指导快系统执行。 端到端模型(系统 1)和 VLM 模型(系统 2)各自运行在一颗 OrinX 芯片上。
简而言之,通过这样的技术架构,搭载 MindVLA 功能的理想汽车不再仅仅是一个驾驶工具,而是一个能够与用户沟通并理解用户意图的智能体。
智能体或个性化生成式智驾方案已经成为各家车企和供应商对未来技术路线的共识。极氪和卓驭昨天也在各自的技术发布会上不约而同地提到了相关内容。
由于目前还没有搭载这类系统的实车上市,我们无法评估其实际使用效果。不过根据各家的计划表,这些系统有望在今年内实现量产。届时,董车会将第一时间为大家进行实测体验。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
