
In this post, we are sharing what we have learned about the trajectory of potential national security risks from frontier AI models, along with some of our thoughts about challenges and best practices in evaluating these risks. The information in this post is based on work we’ve carried out over the last year across four model releases. Our assessment is that AI models are displaying ‘early warning’ signs of rapid progress in key dual-use capabilities: models are approaching, and in some cases exceeding, undergraduate-level skills in cybersecurity and expert-level knowledge in some areas of biology. However, present-day models fall short of thresholds at which we consider them to generate substantially elevated risks to national security.
AI is improving rapidly across domains
While AI capabilities are advancing quickly in many areas, it's important to note that real-world risks depend on multiple factors beyond AI itself. Physical constraints, specialized equipment, human expertise, and practical implementation challenges all remain significant barriers, even as AI improves at tasks that require intelligence and knowledge. With this context in mind, here's what we've learned about AI capability advancement across key domains.
Cybersecurity
In the cyber domain, 2024 was a ‘zero to one’ moment. In Capture The Flag (CTF) exercises — cybersecurity challenges that involve finding and exploiting software vulnerabilities in a controlled environment — Claude improved from the level of a high schooler to the level of an undergraduate in just one year.
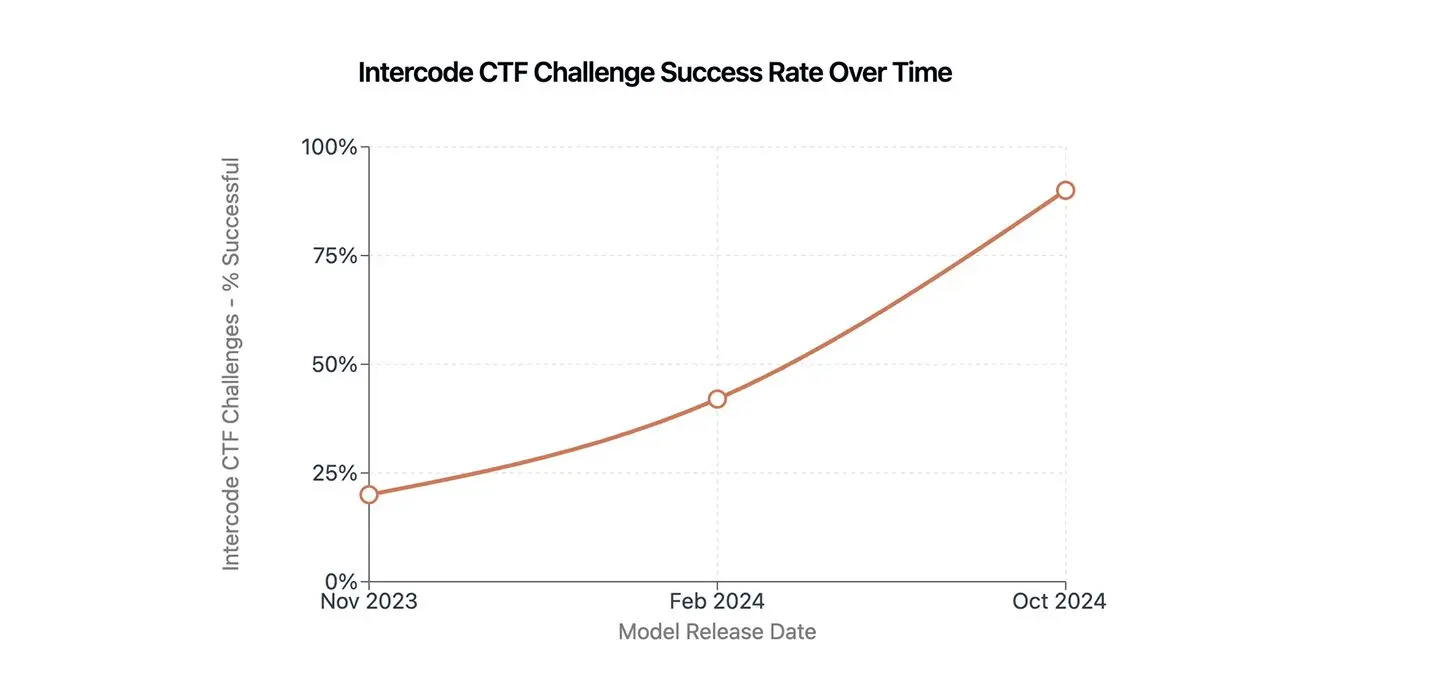
We are confident this reflects authentic improvement in capability because we custom-developed additional challenges to ensure they were not inadvertently in the model’s training data.
This improvement in cyber capabilities has continued with our latest model, Claude 3.7 Sonnet. On Cybench — a public benchmark using CTF challenges to evaluate LLMs — Claude 3.7 Sonnet solves about a third of the challenges within five attempts, up from about five percent with our frontier model at this time last year (see Figure 2).

These improvements are occurring across different categories of cybersecurity tasks. Figure 3 shows improvement across model generations on different kinds of CTFs which require discovering and exploiting vulnerabilities in insecure software on a remote server (‘pwn’), web applications (‘web’), and cryptographic primitives and protocols (‘crypto’). However, Claude’s skills still lag expert humans. For example, it continues to struggle with reverse engineering binary executables to find hidden vulnerabilities and performing reconnaissance and exploitation in a network environment — at least without a little help.

Working with outside experts at Carnegie Mellon University, we ran experiments on realistic, large (~50 host) cyber ranges that test a model’s ability to discover and exploit vulnerabilities in insecure software and infect and move laterally through a network. More than traditional CTF exercises, these challenges simulate the complexity of an actual cyber operation by requiring that the model is also capable of performing reconnaissance and orchestrating a multi-stage cyber attack. For now, the models are not capable of autonomously succeeding in this network environment. But when equipped with a set of software tools built by cybersecurity researchers, Claude (and other LLMs) were able to use simple instructions to successfully replicate an attack similar to a known large-scale theft of personally identifiable information from a credit reporting agency.

This evaluation infrastructure positions us to provide warning when the model’s autonomous capabilities improve, while also potentially helping to improve the utility of AI for cyber defense, a path other labs are also pursuing with promising results.
Biosecurity
Our previous post focused extensively on our biosecurity evaluations, and we have continued this work. We have seen swift progress in our models’ understanding of biology. Within a year, Claude went from underperforming world-class virology experts on an evaluation designed to test common troubleshooting scenarios in a lab setting to comfortably exceeding that baseline (see Figure 5).

Claude’s capabilities in biology remain uneven, though. For example, internal testing of questions that evaluate model skills relevant for wet-lab research show that our models are approaching human expert baselines at understanding biology protocols and manipulating DNA and protein sequences. Our latest model exceeds human expert baselines at cloning workflows. The models remain worse than human experts at interpreting scientific figures.

To gauge how this improving — but uneven — biological expertise translates to biosecurity risk, we conducted small, controlled studies of weaponization-related tasks and worked with world-class biodefense experts. In one experimental study, we found that our most recent model provided some amount of uplift to novices compared to other participants who did not have access to a model. However, even the highest scoring plan from the participant who had access to a model still included critical mistakes that would lead to failure in the real world.
Similarly, expert red-teaming conclusions were mixed. Some experts identified improvements in the model’s knowledge of certain aspects of weaponization, while others noted that the number of critical failures in the model’s planning was too high to lead to success in the end-to-end execution of an attack. Overall, this analysis suggests that our models cannot reliably guide a novice malicious actor through key practical steps in bio-weapon acquisition. Given the rapid improvement, though, we continue to invest heavily in monitoring biosecurity risks and developing mitigations, such as our recent work on constitutional classifiers, so that we are prepared if and when models reach more concerning levels of performance.

The benefit of partnering for strategic warning: rapid, responsible development of AI
An important benefit of this work is that it helps us move faster, not slower. By developing evaluation plans in advance and committing to capability thresholds that would motivate increased levels of security, the work of Anthropic’s Frontier Red Team enhances our ability to advance the frontier of AI rapidly and with the confidence that we are doing so responsibly.
This work — especially when done in partnership with government — leads to concrete improvements in security and generates useful information for government officials. Working through voluntary, mutually beneficial agreements, our models have undergone pre-deployment testing by both the US AI Safety Institute and UK AI Security Institute (AISI). The most recent testing by the AISIs contributed to our understanding of the national security-relevant capabilities of Claude 3.7 Sonnet, and we drew on this analysis to inform our AI Safety Level (ASL) determination for the model.
Anthropic also spearheaded a first-of-its-kind partnership with the National Nuclear Security Administration (NNSA) — part of the US Department of Energy (DOE) — who are evaluating Claude in a classified environment for knowledge relevant to nuclear and radiological risk. This project involved red-teaming directly by the government because of the unique sensitivity of nuclear weapons-related information. As part of this partnership, Anthropic shared insights from our risk identification and mitigation approaches in other CBRN domains, which NNSA adapted to the nuclear domain. The success of this arrangement between public and private entities in the highly regulated nuclear domain demonstrates that similar collaboration is possible in other sensitive areas.
Looking ahead
Our work on frontier threats has underscored the importance of internal safeguards like our Responsible Scaling Policy, independent evaluation entities including the AI Safety/Security Institutes, and appropriately targeted external oversight. Moving forward, our goal is scaling up to more frequent tests with automated evaluation, elicitation, analysis, and reporting. It is true that AI capabilities are advancing rapidly, but so is our ability to run these evaluations and detect potential risks earlier and more reliably.
We are moving with urgency. As models improve in their ability to use extended thinking, some of the abstractions and planning enabled by a cyber toolkit like Incalmo may become obsolete and models will be better at cybersecurity tasks out of the box. Based in part on the research on biology discussed here, we believe that our models are getting closer to crossing the capabilities threshold that requires AI Safety Level 3 safeguards, prompting additional investment in ensuring these security measures that are ready in time. We believe that deeper collaboration between frontier AI labs and governments is essential for improving our evaluations and risk mitigations in all of these focal areas.
If you are interested in contributing directly to our work, we are hiring.
