


At NVIDIA GTC25, Gnani.ai experts unveiled groundbreaking advancements in voice AI, focusing on the development and deployment of Speech-to-Speech Foundation Models. This innovative approach promises to overcome the limitations of traditional cascaded voice AI architectures, ushering in an era of seamless, multilingual, and emotionally aware voice interactions.
The Limitations of Cascaded Architectures
Current state-of-the-art architecture powering voice agents involves a three-stage pipeline: Speech-to-Text (STT), Large Language Models (LLMs), and Text-to-Speech (TTS). While effective, this cascaded architecture suffers from significant drawbacks, primarily latency and error propagation. A cascaded architecture has multiple blocks in the pipeline, and each block will add its own latency. The cumulative latency across these stages can range from 2.5 to 3 seconds, leading to a poor user experience. Moreover, errors introduced in the STT stage propagate through the pipeline, compounding inaccuracies. This traditional architecture also loses critical paralinguistic features such as sentiment, emotion, and tone, resulting in monotonous and emotionally flat responses.
Introducing Speech-to-Speech Foundation Models
To address these limitations, Gnani.ai presents a novel Speech-to-Speech Foundation Model. This model directly processes and generates audio, eliminating the need for intermediate text representations. The key innovation lies in training a massive audio encoder with 1.5 million hours of labeled data across 14 languages, capturing nuances of emotion, empathy, and tonality. This model employs a nested XL encoder, retrained with comprehensive data, and an input audio projector layer to map audio features into textual embeddings. For real-time streaming, audio and text features are interleaved, while non-streaming use cases utilize an embedding merge layer. The LLM layer, initially based on Llama 8B, was expanded to include 14 languages, necessitating the rebuilding of tokenizers. An output projector model generates mel spectrograms, enabling the creation of hyper-personalized voices.
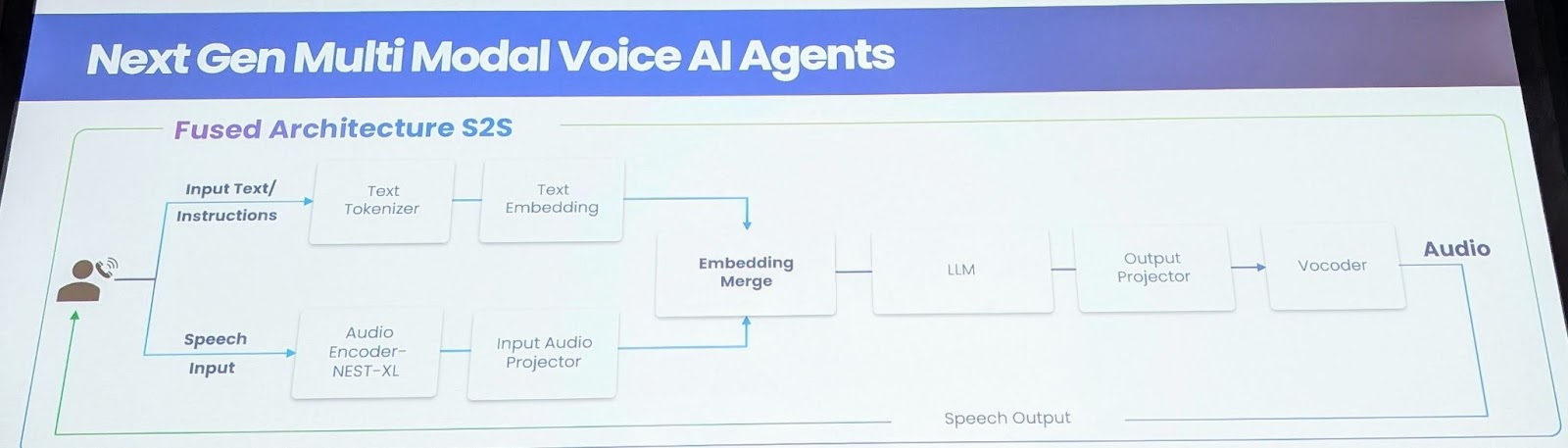
Key Benefits and Technical Hurdles
The Speech-to-Speech model offers several significant benefits. Firstly, it significantly reduces latency, moving from 2 seconds to approximately 850-900 milliseconds for the first token output. Secondly, it enhances accuracy by fusing ASR with the LLM layer, improving performance, especially for short and long speeches. Thirdly, the model achieves emotional awareness by capturing and modeling tonality, stress, and rate of speech. Fourthly, it enables improved interruption handling through contextual awareness, facilitating more natural interactions. Finally, the model is designed to handle low bandwidth audio effectively, which is crucial for telephony networks. Building this model presented several challenges, notably the massive data requirements. The team created a crowd-sourced system with 4 million users to generate emotionally rich conversational data. They also leveraged foundation models for synthetic data generation and trained on 13.5 million hours of publicly available data. The final model comprises a 9 billion parameter model, with 636 million for the audio input, 8 billion for the LLM, and 300 million for the TTS system.
NVIDIA’s Role in Development
The development of this model was heavily reliant on the NVIDIA stack. NVIDIA Nemo was used for training encoder-decoder models, and NeMo Curator facilitated synthetic text data generation. NVIDIA EVA was employed to generate audio pairs, combining proprietary information with synthetic data.
Use Cases
Gnani.ai showcased two primary use cases: real-time language translation and customer support. The real-time language translation demo featured an AI engine facilitating a conversation between an English-speaking agent and a French-speaking customer. The customer support demo highlighted the model’s ability to handle cross-lingual conversations, interruptions, and emotional nuances.
Speech-to-Speech Foundation Model
The Speech-to-Speech Foundation Model represents a significant leap forward in voice AI. By eliminating the limitations of traditional architectures, this model enables more natural, efficient, and emotionally aware voice interactions. As the technology continues to evolve, it promises to transform various industries, from customer service to global communication.
The post Speech-to-Speech Foundation Models Pave the Way for Seamless Multilingual Interactions appeared first on MarkTechPost.
