
号称地表最强的M3 Ultra,本地跑满血版DeepSeek R1,效果到底如何?
其实,有些DeepSeek玩家们已经提前拿到手做过实测了。
例如这位Alex老哥就是其中之一:

他提前拿到了两台搭载M3 Ultra的Mac Studio,配置是这样的:
M3 Ultra(32 核中央处理器、80 核图形处理器和 32 核神经网络引擎)
512G统一内存
1TB固态硬盘

具体来说,Alex老哥用配备Thunderbolt 5互连技术(传输速率为 80Gbps)的EXO Labs设备,来运行完整的DeepSeek R1模型(671B、8-bit)。
然后效果是这样的:
嗯,跑通了!
Alex老哥表示,两台Mac Studio本地跑满血版DeepSeek R1,实际速度是11 tokens/秒,理论上可以达到20 tokens/秒。
至于价格嘛,一台上述配置的Mac Studio是74249元,两台就是小15万元。
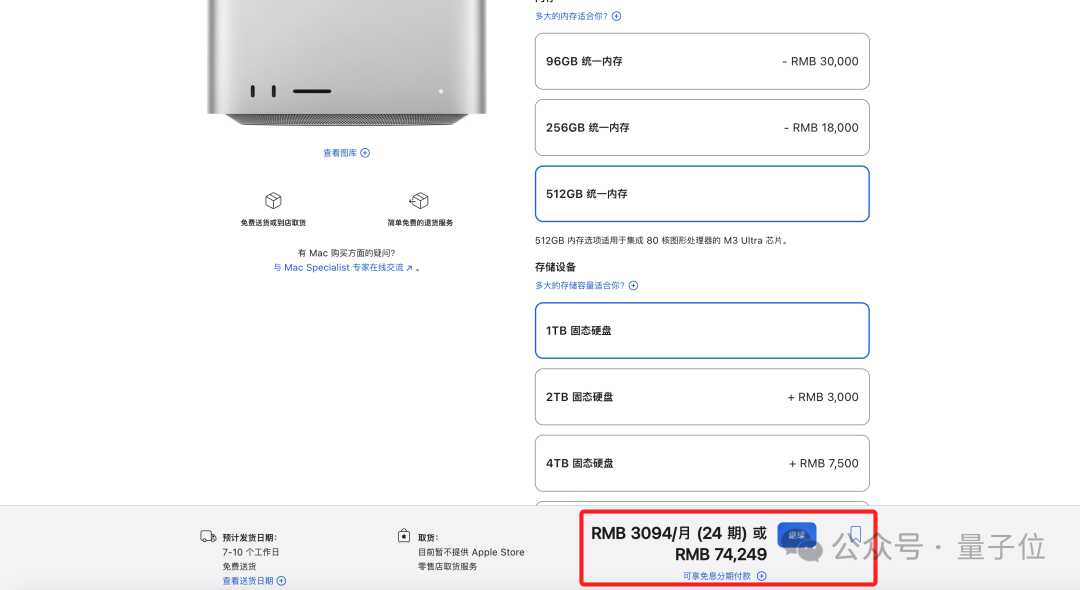
或许很多小伙伴觉得这个价格有点略贵。
但在M3 Ultra之前啊,如果你想在本地使用显卡来推理V3或R1,那么就得起码需要6、7张A100……大约小100万元 。
。
也正因如此,也有不少网友认为搭载M3 Ultra的Mac Studio,堪称是“性价比最高的大模型一体机”。
值得注意的是,苹果这次似乎是主动给DeepSeek玩家们提前发货,有种让他们赶紧测一测的意味。
毕竟在发布之际,苹果就强调了可以在M3 Ultra版Mac Studio中跑超过6000亿参数的大模型。
掀起一波本地跑DeepSeek的风
其实在M3 Ultra版Mac Studio发布前后,已经有不少人做过类似的评测。
例如B站博主“虽然但是张黑黑”的测试结果是:
15.78 tokens/秒:采用Ollama的GGUF格式
19.17 tokens/秒:采用更适合苹果的MLX格式
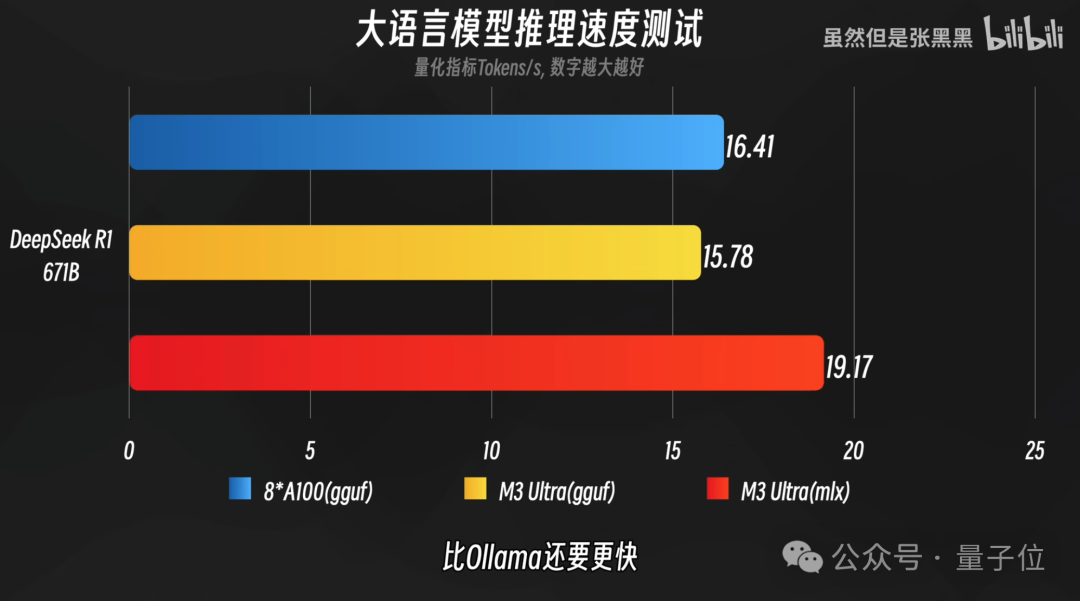
这个速度已经跟在线使用DeepSeek R1的速度相媲美了。
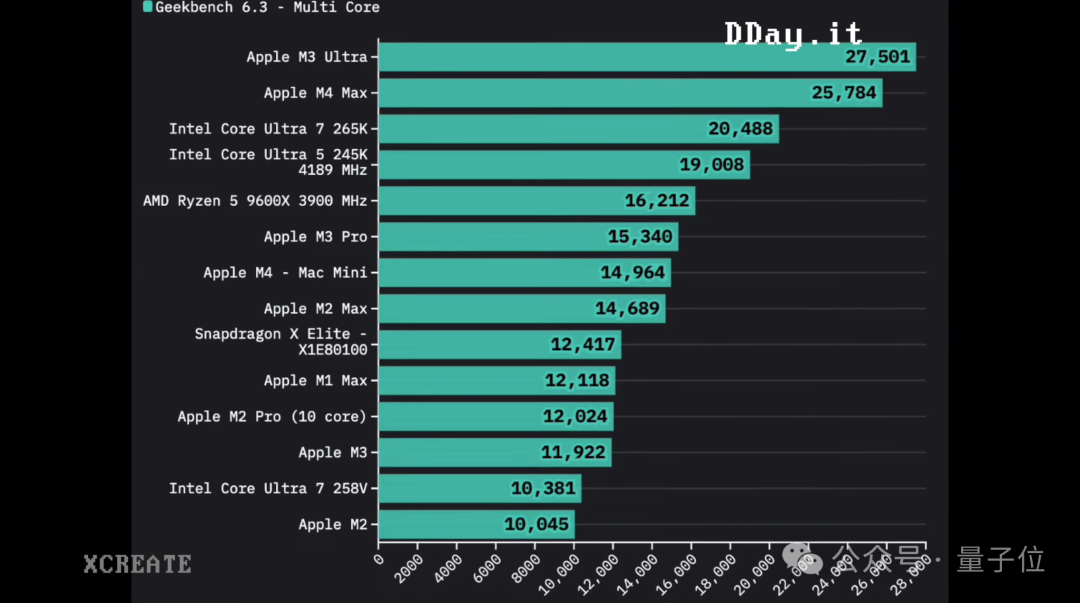
除此之外,像外网博主Xcreate还把M3 Ultra版Mac Studio和M4 Max版Macbook Pro的拉到一个“擂台”做了比较。
首先从性能上来看,Geekbench测试的结果显示,M3 Ultra在CPU性能方面与M4 Max非常接近,但M3 Ultra略胜一筹。
在本地运行大模型测试方面,博主在运行基于Llama的DeepSeek R1 70B模型时,M3 Ultra的速度为11.3 tokens/ 秒,而M4 Max测试结果为10.69 tokens/秒,差距并不是很大。
但更重要的是测试满血版DeepSeek R1的结果。
对此,博主认为在本地完整运行671B的DeepSeek是有点困难的,因为已经有人宣告失败。
但也有成功的例子。
他举例另一位评测人员的结果,显示是运行8bit量化版本的DeepSeek R1,得到了9-21 tokens/秒的速度。
而在4bit量化版情况下,速度为16-18 tokens/秒。

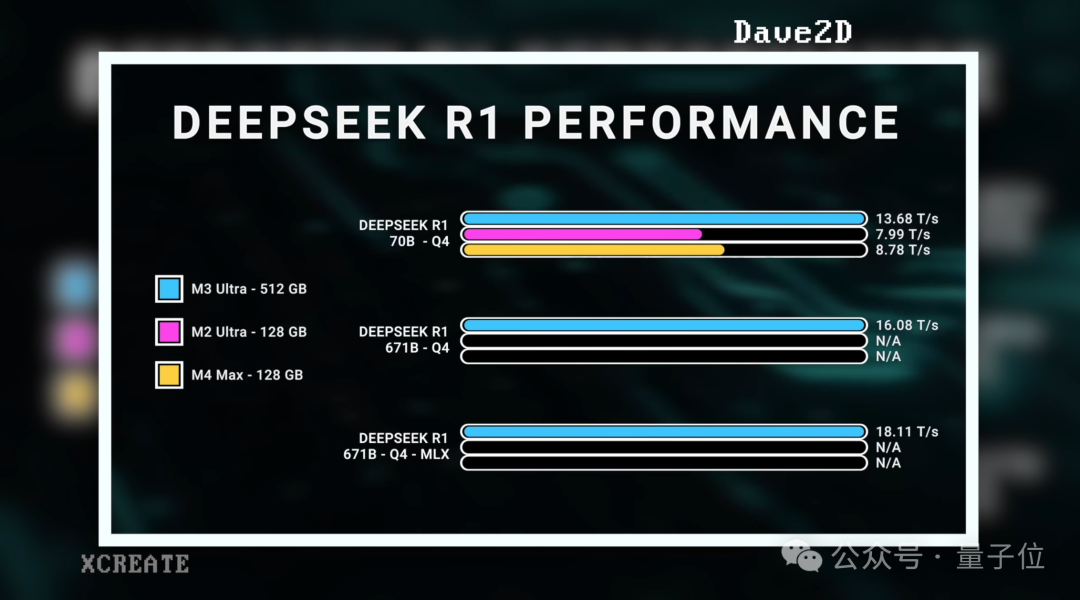
至于为什么体量更大的671B的DeepSeek,会比70B运行速度更快,是因为DeepSeek将671B模型分片为 “专家混合体”,实际运行时根据问题切换,类似运行30B的模型。
最后,博主也提醒想要在本地运行大模型的友友们,网传苹果将在今年WWDC上发布M4 Ultra,所以可以再观望一下。
参考链接:
[1]https://x.com/alexocheema/status/1899604613135028716
[2]https://www.bilibili.com/video/BV1nkRnYTEWx/
— 完 —
评选报名|2025年值得关注的AIGC企业&产品
下一个AI“国产之光”将会是谁?
本次评选结果将于4月中国AIGC产业峰会上公布,欢迎参与!

一键关注 ? 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
