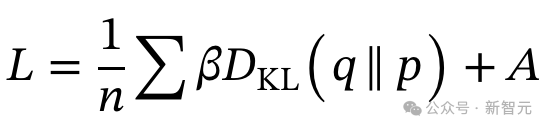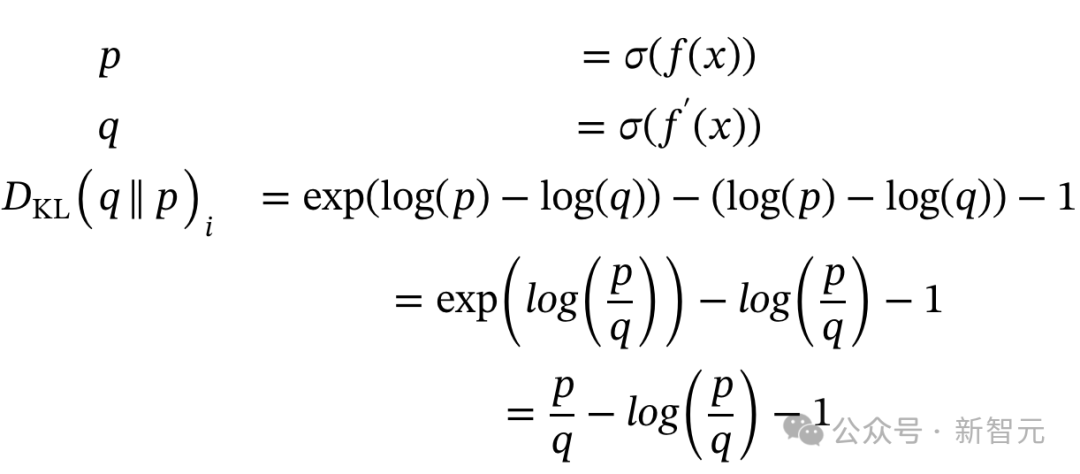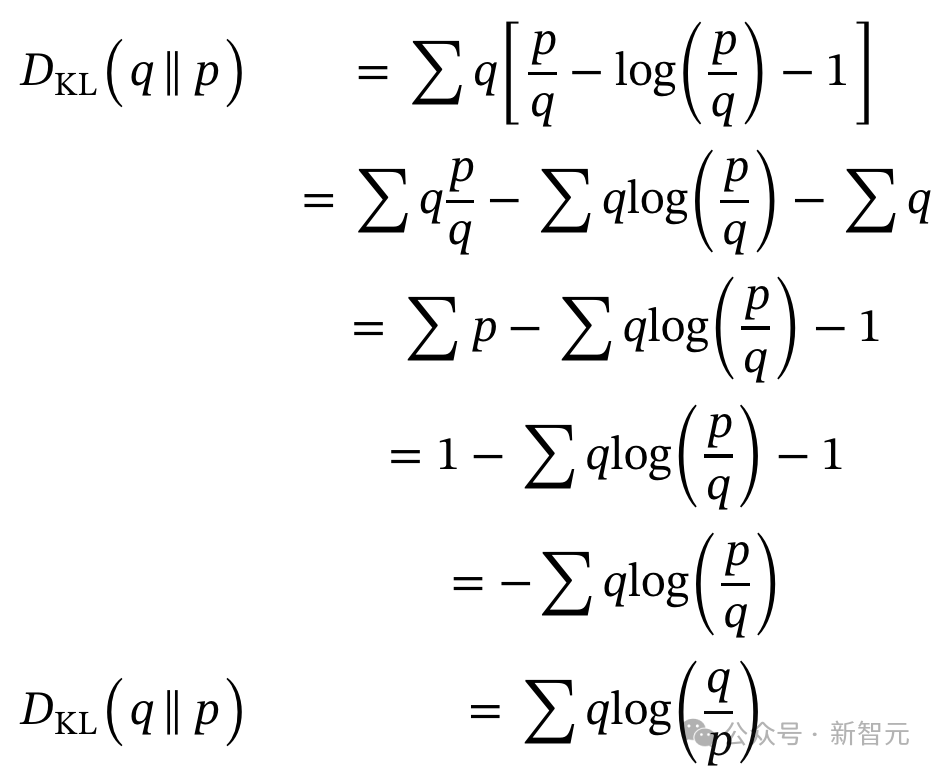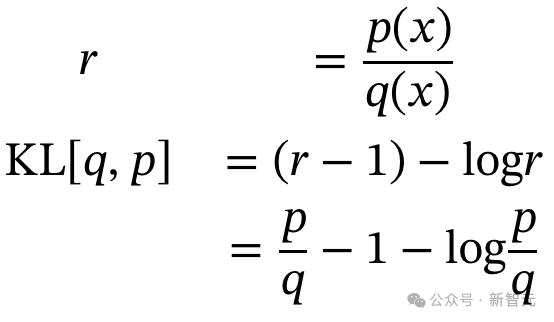index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
Unsloth再次带来突破性进展,将训练推理模型所需的显存大幅降低。现在,只需5GB的VRAM即可训练Qwen2.5(1.5B)推理模型,相比之前的7GB减少了2GB。新算法还将GRPO训练推理模型的上下文变长提升了10倍,同时显存占用减少了90%。这一成果得益于全新设计的内存高效线性算法、智能梯度checkpoint算法以及与底层推理引擎共享内存空间等技术突破。Unsloth的创新让低成本训练长上下文推理模型成为可能,即使是使用老旧显卡也能参与其中。
🚀 Unsloth最新高效GRPO算法,在长上下文处理上取得显著突破,上下文长度增加10倍的同时,VRAM使用量仅为标准实现的10%。例如,Llama 3.1(8B)在20K上下文长度下,训练VRAM从510.8GB降至54.3GB。
💡 Unsloth通过三项关键技术实现了VRAM的显著降低:全新设计的内存高效线性算法,将GRPO的内存使用量削减了8倍以上;智能梯度checkpoint算法,将中间激活值异步卸载到系统RAM中;与底层推理引擎(vLLM)共享相同的GPU/CUDA内存空间。
🔑 Unsloth团队在GRPO实现中发现了一些关键问题,包括参考实现使用的是反向KL散度而非正向KL散度,以及在float16混合精度上直接实现线性交叉熵可能导致崩溃等,并通过实验验证了这些发现。
🛠️ Unsloth新版本还增加了GRPO的完整日志记录功能,为所有奖励函数提供详细信息,并支持在vLLM中使用FP8 KV缓存,进一步减少KV缓存空间使用量,提升训练效率。
开源微调神器Unsloth带着黑科技又来了:上次更新把GRPO需要的内存见到了7GB,这次只需要5GB的VRAM,就能训练自己的推理模型Qwen2.5(1.5B),比上次要少2GB。
这次把GRPO训练推理模型的上下文变长10倍,同时需要的显存少了90%。使用最新的Unsloth,只要5GB显存就能训练自己的推理模型,而且Qwen2.5-1.5B不会损失准确率。16年开始发售的GPU比如GTX 1060的显存都有8GB。16年GTX 1060放到现在,堪称电子古董!目前,实现更长的上下文是GRPO面临的最大挑战之一。与其他GRPO LoRA/QLoRA实现相比,即使是基于Flash Attention 2(FA2)的实现,Unsloth新推出的高效GRPO算法上下文长度增加了10倍,同时使用的VRAM只要10%。在配备TRL+FA2的GRPO设置中,Llama 3.1(8B)在20K上下文长度下,训练需要510.8GB的VRAM。而Unsloth将VRAM减少了90%,降至仅54.3GB。和使用Flash Attention 2的标准实现相比,Unsloth使用多种技巧,巧妙地把GRPO的VRAM使用量减少了90%多!
在20K的上下文长度下,每个提示生成8次,Unsloth在Llama-3.1-8B模型上仅使用54.3GB的VRAM,而标准实现需要510.8GB(Unsloth减少了90%)。这一切得益于下列3项突破:全新设计的内存高效线性算法:将GRPO的内存使用量削减了8倍以上,节省了68.5GB的内存。借助torch.compile,在num_generations=8和20K上下文长度下,实际上还更快。利用了Unsloth已发布的智能梯度checkpoint算法:将中间激活值异步卸载到系统RAM中,速度仅慢了1%。由于需要num_generations=8,这节省了高达372GB的VRAM。通过中间梯度累积,甚至可以进一步减少内存使用。与底层推理引擎(vLLM)共享相同的GPU/CUDA内存空间,不像其他包中的实现那样。这又节省了16GB的VRAM。
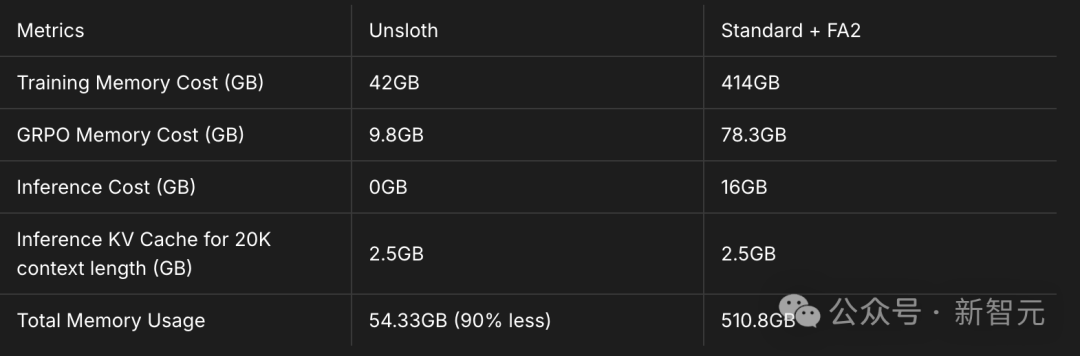
Unsloth和基于Flash Attention 2(FA2)的标准实现内存比较在典型的GRPO标准实现中,需要创建两个大小为(8,20K)的logits来计算GRPO损失。这需要2*2字节*8(生成次数)*20K(上下文长度)*128256(词汇表大小)=78.3GB的VRAM。Unsloth将长上下文GRPO的内存使用量削减了8倍,因此对于20K的上下文长度,只需要额外的9.8GBVRAM!还需要以16位格式存储KV缓存。Llama3.18B有32层,K和V的大小均为1024。因此,对于20K的上下文长度,内存使用量=2*2字节*32层*20K上下文长度*1024=每个批次2.5GB。可以将vLLM的批次大小设置为8,但为了节省VRAM,在计算中将其保持为1。否则,需要20GB来存储KV缓存。分组相对策略优化(Group Relative Policy Optimization,GRPO),出自DeepSeek去年发表的论文。
如果一生只能读一篇DeepSeek的论文,网友建议选择首次提出GRPO的DeepSeekMath论文。
论文链接:https://arxiv.org/abs/2402.03300随后在DeepSeek的论文中,利用GRPO算法创建了DeepSeek-R1。发现的问题
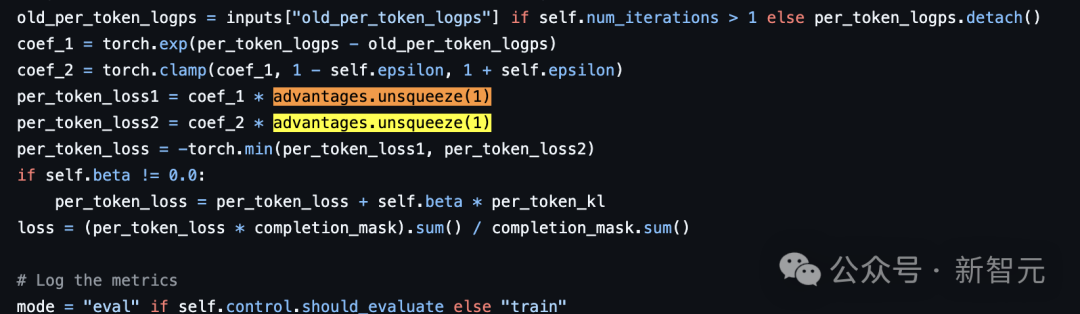
在这里利用了Hugging Face的TRL GRPO实现。其中使用的是反向KL散度(而不是正向KL散度)。β是一个设为0.04的缩放因子,A是考虑所有奖励函数后得到的优势值。q是新训练的模型,P是原始参考模型。这意味着什么?实现中可能缺少一个与q(新分布项)的乘法吗?但这似乎是正确的,和DeepSeek-Math论文第14页首次引入GRPO时一样。
DeepSeek-Math论文第14页:在损失函数中添加KL散度,正则化GRPO算法同样,John Schulman的博客也提到,反向KL项的无偏估计,实际上并不需要额外的q项。
链接地址:http://joschu.net/blog/kl-approx.htmltorch.exp(q-q.detach()) * advantages.unsqueeze(1)
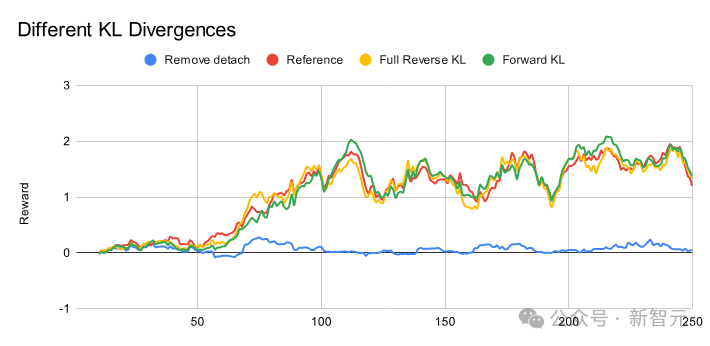
实际上,发现这是必要的——似乎自动梯度autograd引擎可能无法正确传播梯度。使用参考实现的常规GRPO(红线)
移除detach代码(蓝线)
按照之前讨论的完整反向KL,添加额外项(黄线)
总体来说,移除detach显然会破坏训练,所以必须保留它——这很可能需要进一步调查。其他实现似乎也类似?可能需要运行模型更长时间,以观察不同的效果。但没想到华人工程师Horace He的线性交叉熵实现,带给unsloth灵感并成功应用于GRPO!

Horace He,在Meta从事PyTorch相关工作1 GRPO参考实现使用的是反向KL散度,而不是正向KL散度。2 如果不正确处理,在float16混合精度(以及float8)上直接实现线性交叉熵,并使用自动混合精度缩放机制,会导致崩溃。3 发现了GRPO损失实现中的其他一些奇怪之处,主要是在反向KL散度的公式表述方面。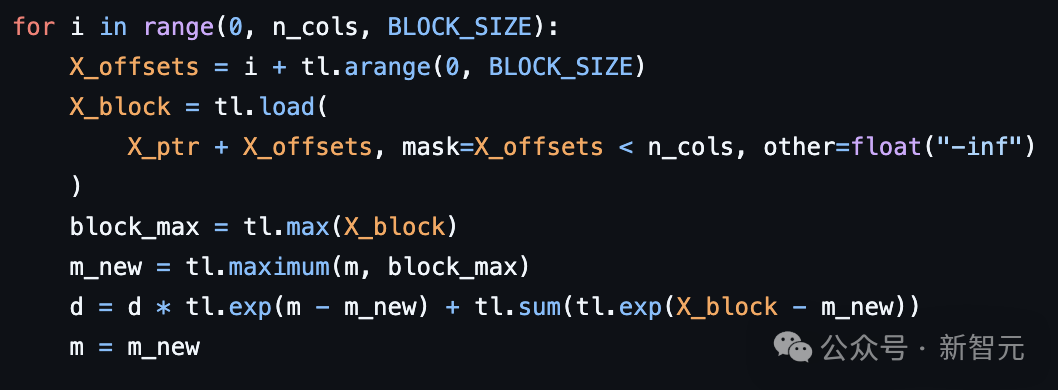
线性交叉商链接:https://gist.github.com/Chillee/22cd93e11b887db1f596ab754d60a899GRPO的完整日志记录
之前,unsloth只显示总聚合奖励函数本身,新版本为所有奖励函数提供完整的日志记录详情!也不再需要调用函数来给GRPO打补丁了!也就是说,新版本会自动处理,可以删除下列代码:from unsloth import PatchFastRLPatchFastRL("GRPO", FastLanguageModel)
现在在vLLM中还能使用FP8 KV缓存,这可以在较新的GPU(RTX 3090、A100及更新型号)上将KV缓存空间使用量减少2倍。 tokenizer = FastLanguageModel.from_pretrained( model_name = "meta-llama/meta-Llama-3.1-8B-Instruct", max_seq_length = max_seq_length, load_in_4bit = True, fast_inference = True, max_lora_rank = lora_rank, gpu_memory_utilization = 0.6, float8_kv_cache = True, )
如果想在vLLM中使用min_p=0.1或其他采样参数,也支持传递vLLM的SamplingParams参数中的任何内容!
max_prompt_length = 256from trl import GRPOConfig, GRPOTrainerfrom unsloth import vLLMSamplingParamsvllm_sampling_params = vLLMSamplingParams( min_p = 0.1, seed = 3407, ...)training_args = GRPOConfig( ... vllm_sampling_params = vllm_sampling_params, temperature = 1.5,)
https://unsloth.ai/blog/grpo内容中包含的图片若涉及版权问题,请及时与我们联系删除