


Large reasoning models (LRMs) employ a deliberate, step-by-step thought process before arriving at a solution, making them suitable for complex tasks requiring logical accuracy. Unlike earlier techniques that relied on brief chain-of-thought reasoning, LRMs integrate intermediate verification steps, ensuring each stage contributes meaningfully toward the final answer. This structured reasoning approach is increasingly vital as AI systems solve intricate problems across various domains.
A fundamental challenge in developing such models lies in training large language models (LLMs) to execute logical reasoning without incurring significant computational overhead. Reinforcement learning (RL) has emerged as a viable solution, allowing models to refine their reasoning abilities through iterative training. However, traditional RL approaches depend on human-annotated data to define reward signals, limiting their scalability. The reliance on manual annotation creates bottlenecks, restricting RL’s applicability across large datasets. Researchers have explored alternative reward strategies that circumvent this dependence, leveraging self-supervised methods to evaluate model responses against predefined problem sets.
Existing learning frameworks for training LLMs primarily focus on reinforcement learning from human feedback (RLHF), wherein models learn through human-generated reward signals. Despite its effectiveness, RLHF presents challenges related to annotation costs and dataset limitations. Researchers have incorporated verifiable datasets, such as mathematical problems and coding challenges, to address these concerns. These problem sets allow models to receive direct feedback based on the correctness of their solutions, eliminating the need for human intervention. This automated evaluation mechanism has enabled more efficient RL training, expanding its feasibility for large-scale AI development.
A research team from the Renmin University of China, in collaboration with the Beijing Academy of Artificial Intelligence (BAAI) and DataCanvas Alaya NeW, introduced an RL-based training framework to improve the structured reasoning abilities of LLMs. Their study systematically examined the effects of RL on reasoning performance, focusing on techniques that enhance model comprehension and accuracy. The researchers optimized model reasoning without relying on extensive human supervision by implementing structured reward mechanisms based on problem-solving verification. Their approach refined model outputs, ensuring logical coherence in generated responses.
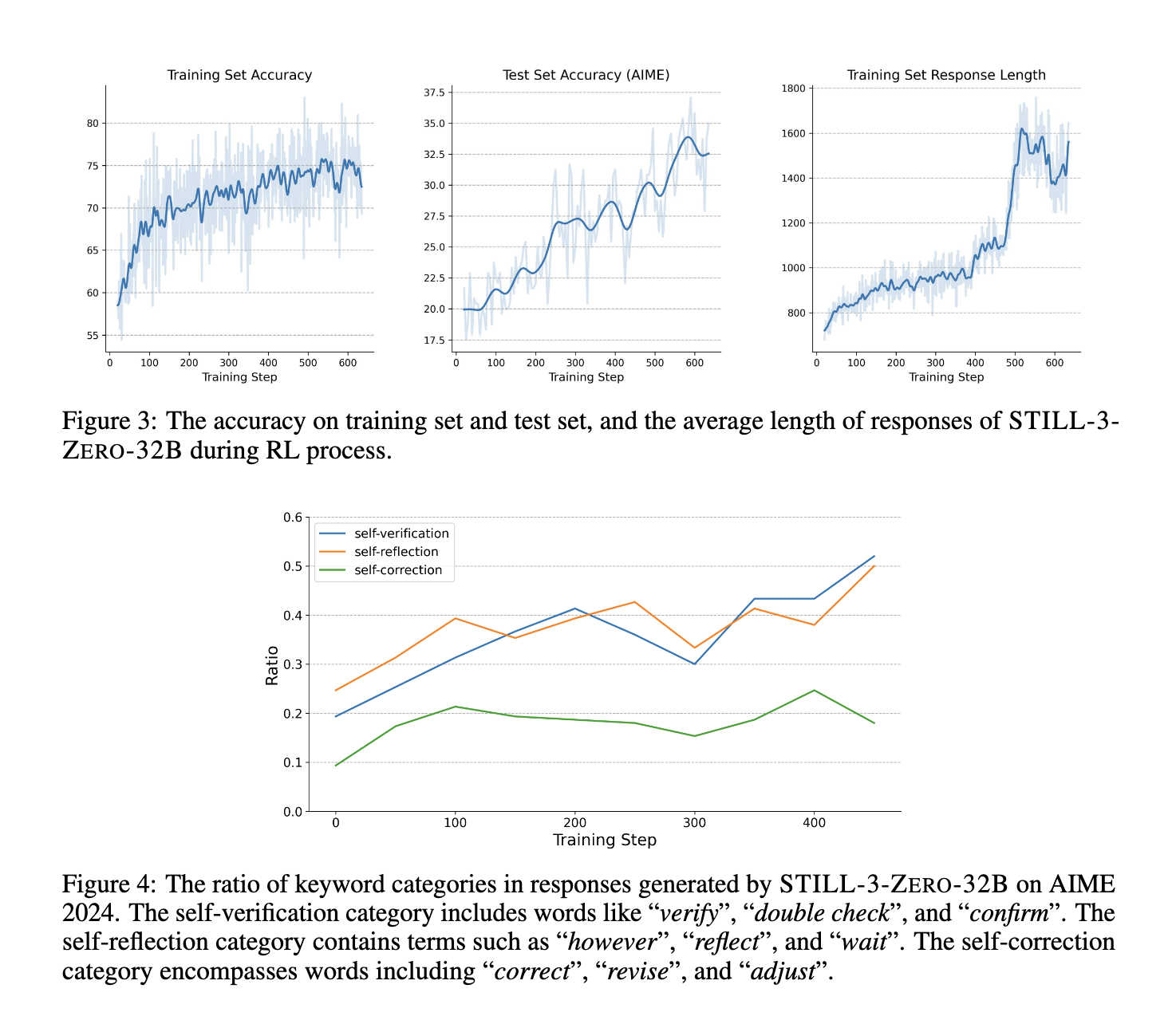
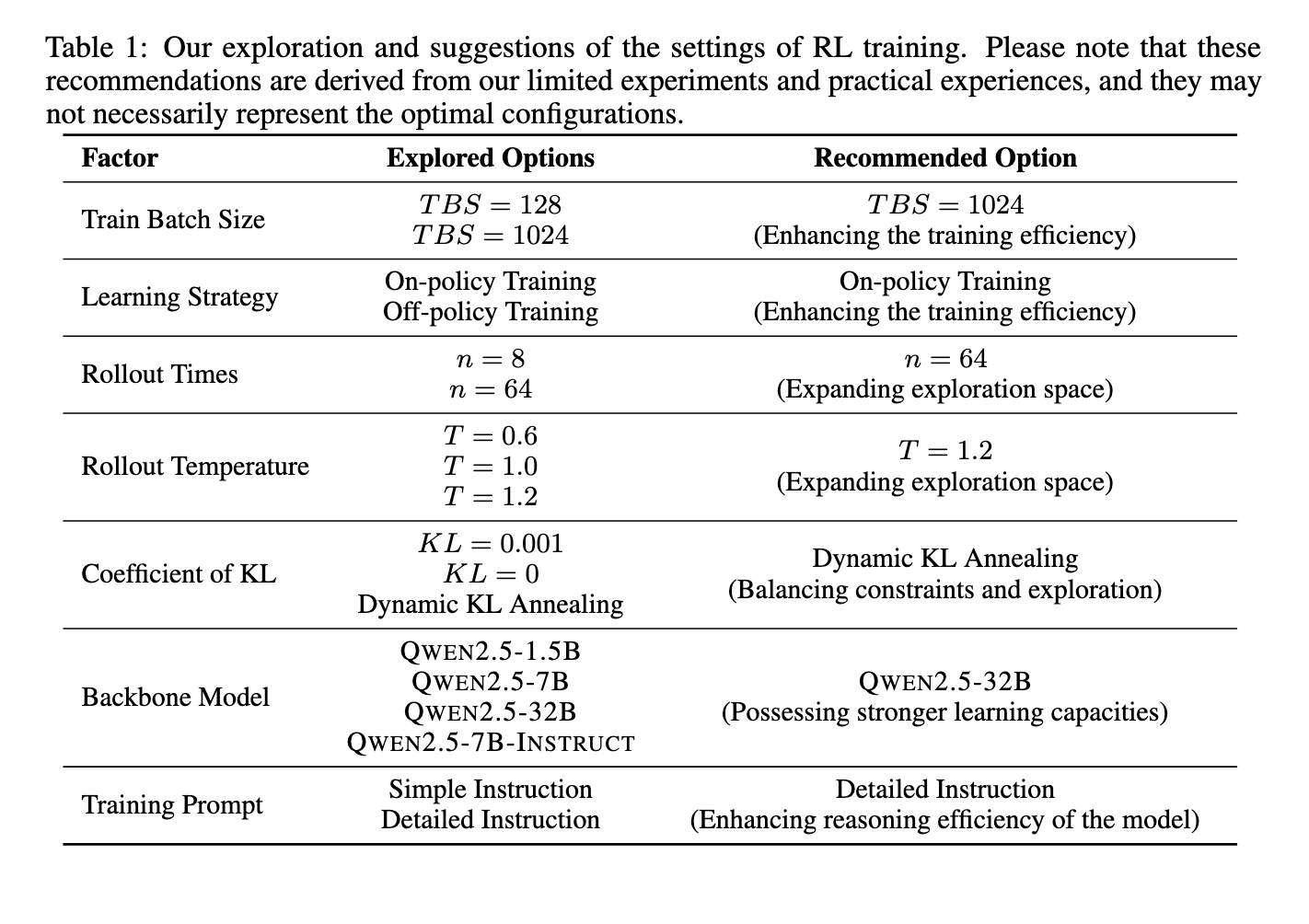
The methodology involved reinforcement learning techniques applied to both base and fine-tuned models. The researchers trained models using policy optimization techniques and structured reward functions. Refining response generation through RL enabled models to develop complex reasoning abilities, including verification and self-reflection. The researchers integrated tool manipulation techniques to enhance performance further, allowing models to interact dynamically with external systems for problem-solving. Their experiments demonstrated that RL effectively guided models toward more structured responses, improving overall accuracy and decision-making efficiency. The training process leveraged the QWEN 2.5-32B model, fine-tuned using a combination of reward signals to optimize reasoning depth and response quality. The researchers also explored various RL hyperparameter configurations, testing the impact of batch sizes, rollout times, and policy learning strategies on model performance. Adjusting these parameters ensured optimal training efficiency while preventing reward exploitation, a common challenge in RL-based model development.
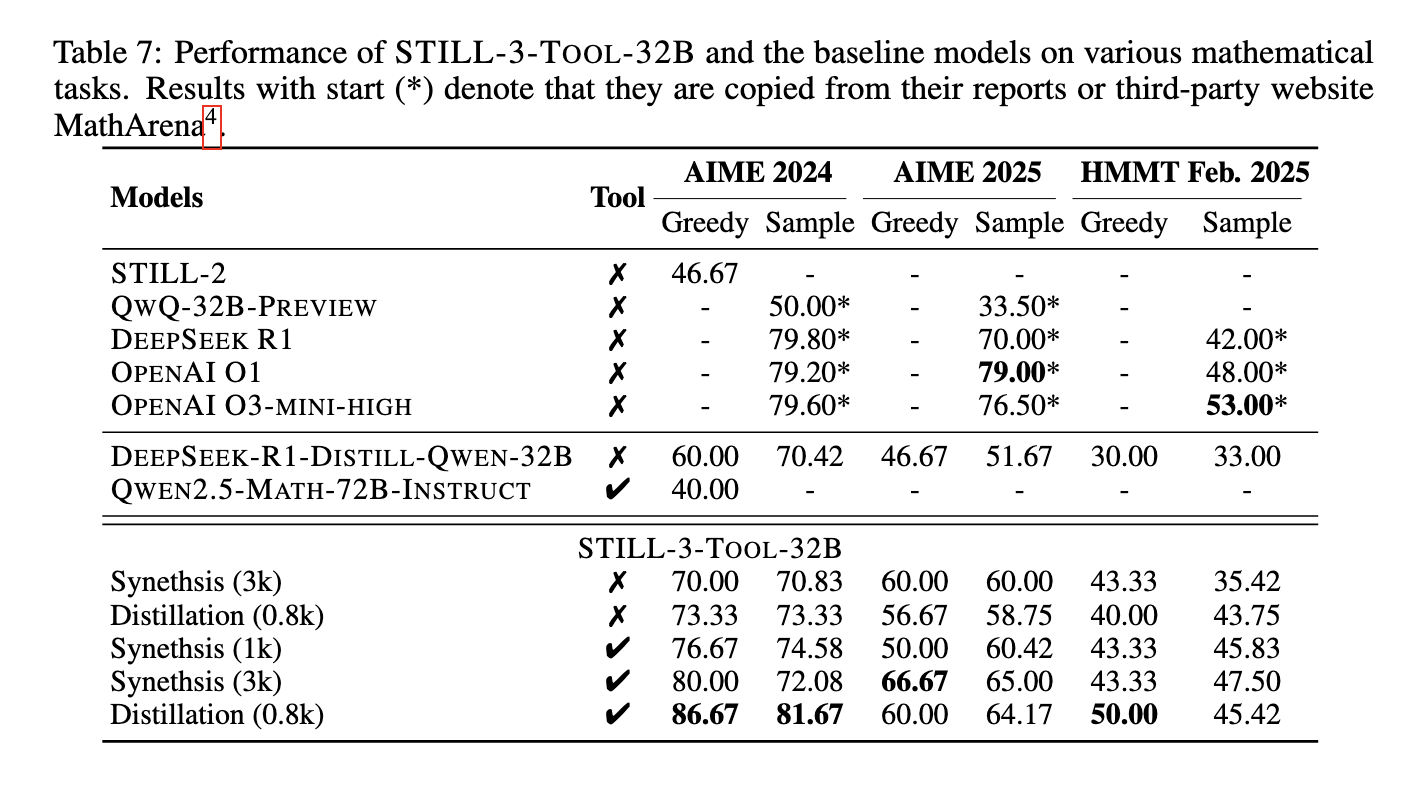
Performance evaluations highlighted significant improvements achieved through RL-based training. After undergoing reinforcement learning, the QWEN 2.5-32B model demonstrated enhanced reasoning abilities with increased response lengths and higher test accuracy. Specifically, the model achieved an accuracy rate of 39.33% on the AIME 2024 dataset, substantially improving its baseline performance. In further experiments, tool manipulation techniques were incorporated, leading to an even higher accuracy of 86.67% when employing a greedy search strategy. These results underscore RL’s effectiveness in refining LLM reasoning capabilities, highlighting its potential for application in complex problem-solving tasks. The model’s ability to process extensive reasoning steps before arriving at a final answer proved instrumental in achieving these performance gains. Moreover, researchers observed that increasing response length alone did not necessarily translate to better reasoning performance. Instead, structuring intermediate reasoning steps within RL training led to meaningful improvements in logical accuracy.

This research demonstrates the significant role of reinforcement learning in advancing structured reasoning models. Researchers successfully enhanced LLMs’ ability to engage in deep, logical reasoning by integrating RL training techniques. The study addresses key challenges in computational efficiency and training scalability, laying the groundwork for further advancements in AI-driven problem-solving. Refining RL methodologies and exploring additional reward mechanisms will be critical for further optimizing the reasoning capabilities of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post This AI Paper Introduces RL-Enhanced QWEN 2.5-32B: A Reinforcement Learning Framework for Structured LLM Reasoning and Tool Manipulation appeared first on MarkTechPost.
