
Dear AI Engineers,
I’m sorry for all the MCP filling your timeline right now.
The Model Context Protocol launched in November 2024 and it was decently well received, but the initial flurry of excitement (with everyone from Copilot to Cognition to Cursor adding support) died down1 right until the 2025 NYC AI Engineer Summit, where a chance conversation with Barry Zhang led to us booking Mahesh Murag (who wrote the MCP servers). I simply thought it’d be a nice change from Anthropic’s 2023 and 2024 prompting workshops, but then we dropped this on March 1st:
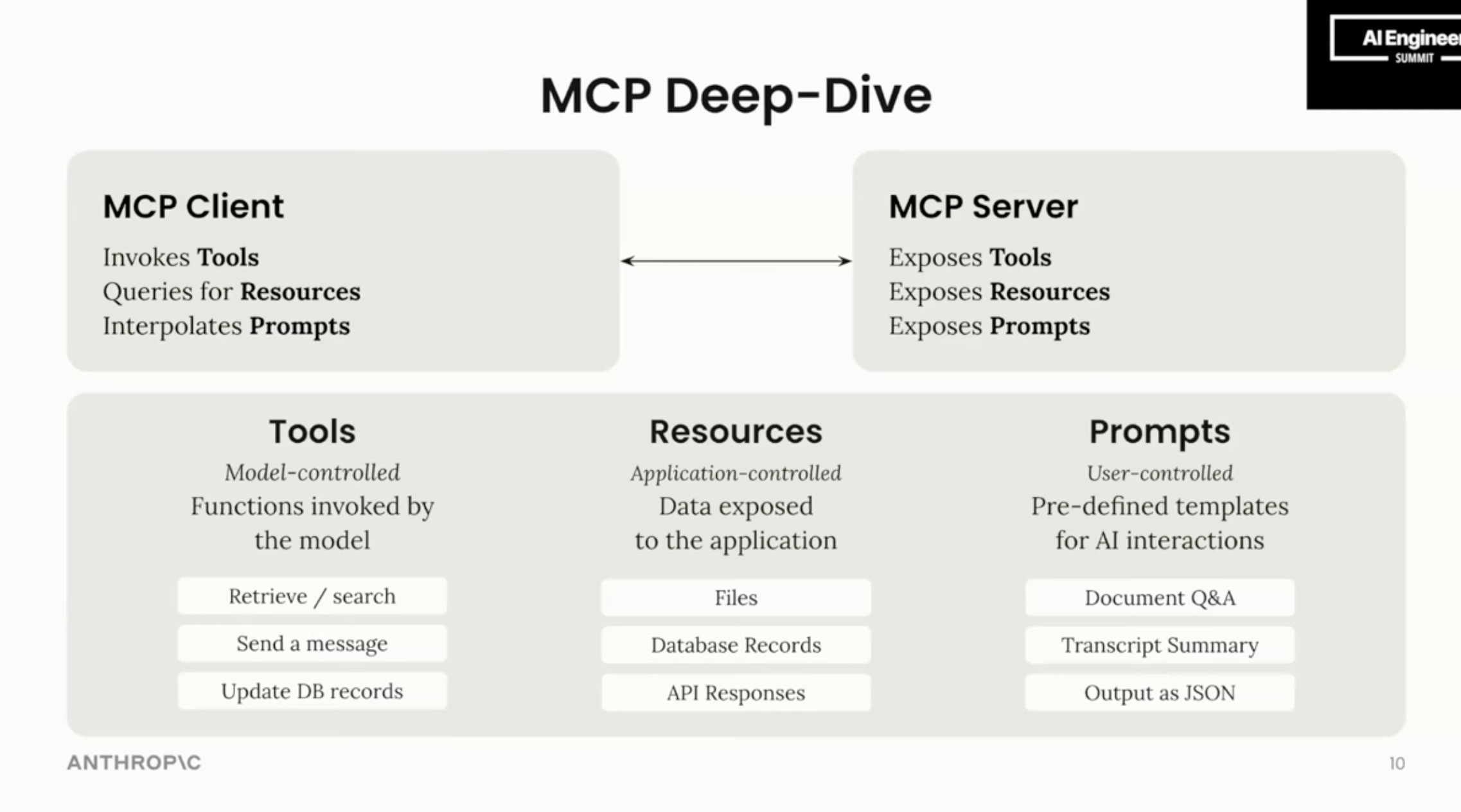
Normally workshops are great for live attendees but it’s rare for an online audience to keep the attention span for a full 2 hours. But then livetweets of the workshop started going viral, because for the first time the community was getting announcements of the highly anticipated official registry, and also comprehensive deep dives into every part of the protocol spec like this:
We then bumped up the editing2 process to release the workshop video, and, with almost 300k combined views in the past week, this happened:
One “reach” goal I have with Latent Space is to try to offer editorial opinions slightly ahead of the consensus. In November we said GPT Wrappers Are Good, Actually, and now a16z is excited about them. In December we told $200/month Pro haters that You’re all wrong, $2k/month “ChatGPT Max” is coming and now we have confirmation that $2-20k/month agents are planned. But I have to admit MCP’s popularity caught even me offguard, mostly because I have seen many attempted XKCD 927’s come and go, and MCP was initially presented as a way to write local, privacy-respecting integrations for Claude Desktop, which I’m willing to bet only a small % of the AI Engineer population have even downloaded (as opposed to say ChatGPT Desktop and even Raycast AI).
Even though we made the workshop happen, I still feel that I underestimated MCP.
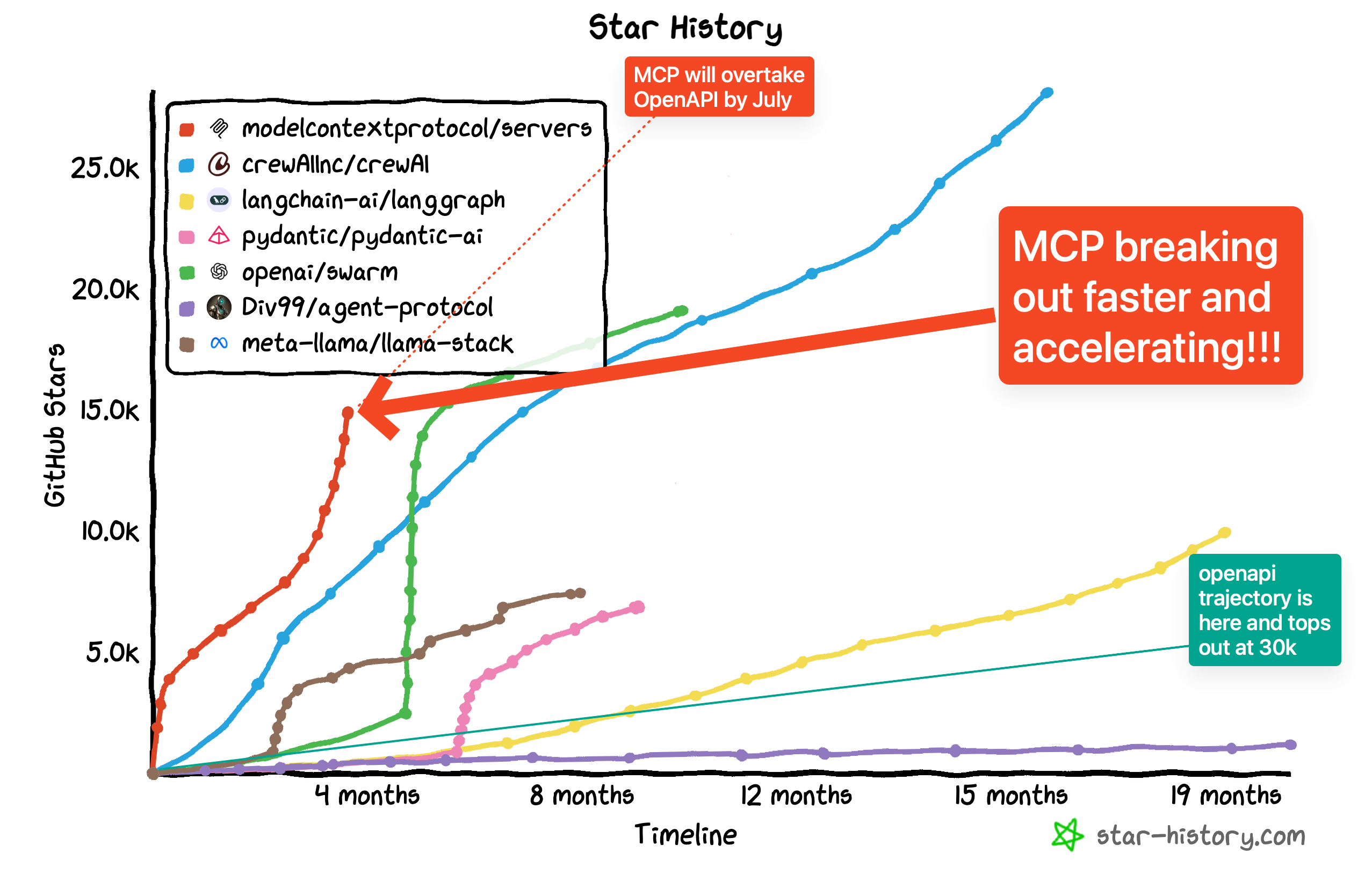
To paraphrase Ben Thompson, the #1 feature of any network is the people already on it. Accordingly, the power of any new protocol derives from its adoption (aka ecosystem), and it’s fair to say that MCP has captured enough critical mass and momentum right now that it is already the presumptive winner of the 2023-2025 “agent open standard” wars. At current pace, MCP will overtake OpenAPI in July:
Widely accepted standards, like Kubernetes and React and HTTP, accommodate the vast diversity of data emitters and consumers by converting MxN problems into tractable M+N ecosystem solutions, and are therefore immensely valuable IF they can get critical mass. Indeed even OpenAI had the previous AI standard3 with even Gemini, Anthropic and Ollama advertising OpenAI SDK compatibility.
I’m not arrogant enough to think the AIE Summit workshop caused this acceleration; we merely poured fuel on a fire we already saw spreading. But as a student of developer tooling startups, many of which try and fail to create momentum for open standards4, I feel I cannot miss the opportunity to study this closer while it is still fresh, so as to serve as a handbook for future standard creation. Besides, I get asked my MCP thoughts 2x a day so it’s time to write it down.
Why MCP Won (in short)
aka “won” status as de facto standard, over not-exactly-equivalent-but-alternative approaches like OpenAPI and LangChain/LangGraph. In rough descending order.
MCP is “AI-Native” version of old idea
MCP is an “open standard” with a big backer
Anthropic has the best developer AI brand
MCP based off LSP, an existing successful protocol
MCP dogfooded with complete set of 1st party client, servers, tooling, SDKs
MCP started with minimal base, but with frequent roadmap updates
Non-Factors: Things that we think surprisingly did not contribute to MCP’s success
Lining up launch partners like Zed, SourceGraph Cody, and Replit
Launching with great documentation
I will now elaborate with some screengrabs.
MCP is “AI-Native” version of old idea
A lot of the “old school developer” types, myself included, would initially be confused by MCP’s success because, at a technical level, MCP is mostly capable of the same5 kinds of capabilities enabled by existing standards like OpenAPI / OData / GraphQL / SOAP / etc. So the implicit assumption is that the older, Lindy, standard should win.
However, to dismiss ideas on a technical basis is to neglect the sociological context that human engineers operate in. In other words, saying that “the old thing does the same, you should prefer the old thing” falls prey to the same Lavers’ Law fallacy of fashion every developer comes to. The reflexive nature of the value of protocols - remember, they only have value because they can get adoption - mean that there is very little ex ante value to any of these ideas. MCP is valuable because the AI influencers deem it so, and therefore it does become valuable.
However it is ALSO too dismissive to say that MCP is exactly equivalent to OpenAPI and it is mere cynical faddish cycles that drive its success. This is why I choose to describe this success factor as “AI Native” - in this case, MCP was born from lessons felt in Claude Sonnet’s #1 SWE-Bench result and articulated in Building Effective Agents, primarily this slide:
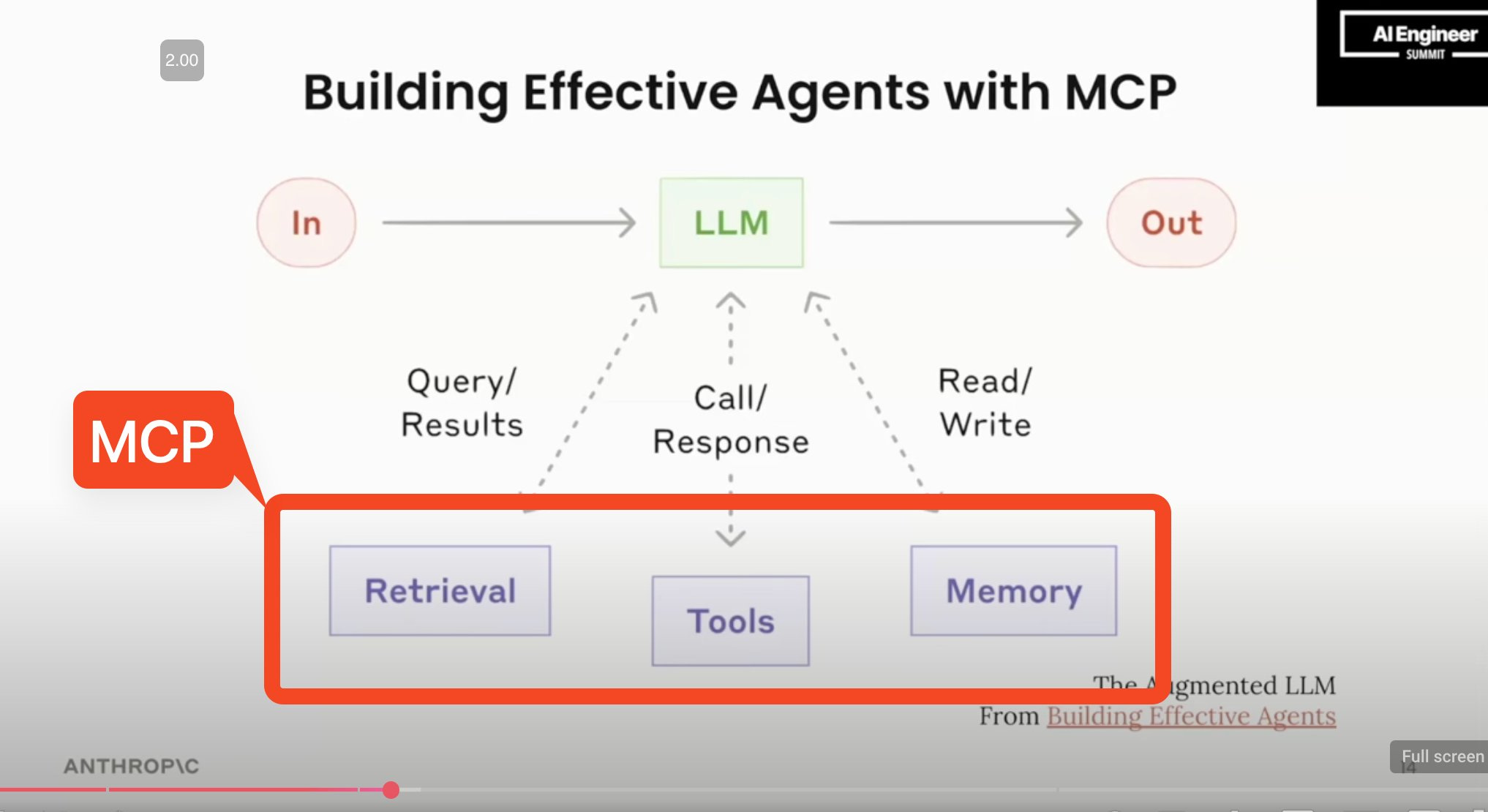
An “AI Native” standard that reifies patterns already independently reoccurring in every single Agent will always be more ergonomic to use and build tools for than an agnostic standard that was designed without those biases.
Hence MCP wins over OpenAPI.
Second, going back to this slide, focus on the differences articulated between Tools (Model-controlled), Resources (Application-controlled), and Prompts (User-controlled).
MCP’s “AI Native”ness being born after the initial wave of LLM frameworks, means that it has enough breathing room to resist doing the “obvious” thing of starting from LLM interoperability (now solved problems and likely owned by clients and gateways), and only focus on the annoying unsolved problems of putting dynamic context access at the center of its universe (very literally saying the motivation of MCP is that “Models are only as good as the context provided to them”).
Hence MCP wins over LangChain et al.
MCP is an “open standard” with a big backer
This one is perhaps the most depressing for idealists who want the best idea to win: a standard from a Big Lab is very simply more likely to succeed than a standard from anyone else. Even ones with tens of thousands of Github stars and tens of millions of dollars in top tier VC funding. There is nothing fair about this; if the financial future of your startup incentivizes you at all to lock me in to your standard, I’m not adopting it. If the standard backer seems too big to really care about locking you in to the standard, then I will adopt it6.
Hence MCP wins over Composio et al.
Any "open standard”7 should have a spec, and MCP has a VERY good spec. This spec alone defeats a lot of contenders, who do not provide such detailed specs.
Hence MCP wins over many open source frameworks, and arguably even OpenAI function calling, whose docs fall just short of a properly exhaustive spec.
Anthropic has the best developer AI brand
Perhaps as important as the fact that a big backer is behind it, is which big backer. If you’re going to build a developer standard, it helps to be beloved by developers. Sonnet has been king here for almost 9 months.
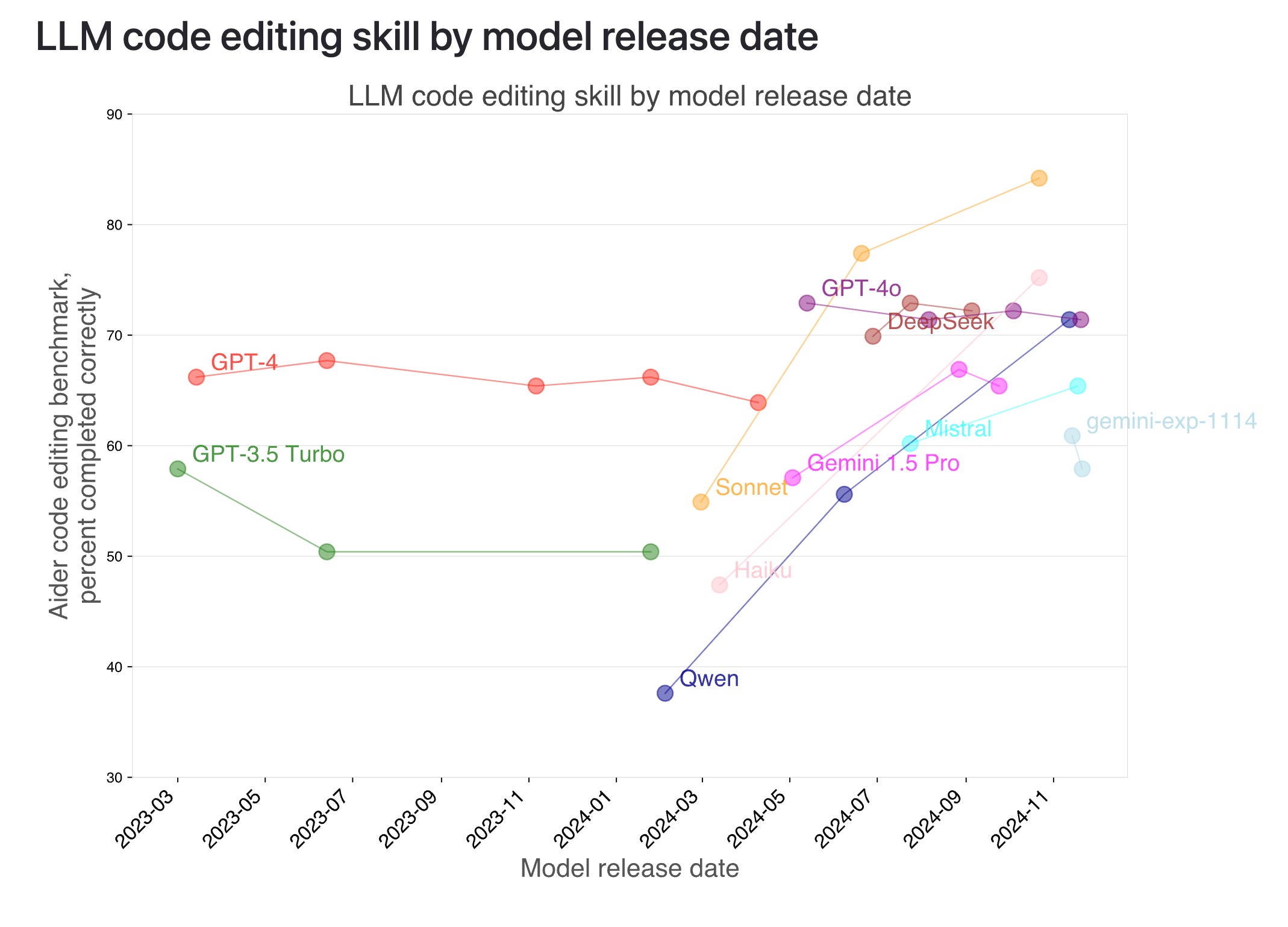
A bit of a more subtle point that might be missed by newer folks - Anthropic has always explicitly emphasized supporting more tools than OpenAI has - we don’t really have benchmarks/ablations for large tool counts, so we don’t know the differential capabilities between model labs, but intuitively MCP enables far more average tools in a single call than is “normal” in tools built without MCP (merely because of ease of inclusion, not due to any inherent technical limitation). So models that can handle higher tool counts better will do better.
Hence MCP wins over equivalent developer standards by, say, Cisco.
MCP based off LSP, an existing successful protocol
The other part of the ““open standard” with a big backer” statement requires that the standard not have any fatal flaws. Instead of inventing a standard on the fly, from scratch, and thus risking relitigating all the prior mistakes of the past, the Anthropic team smartly adapted Microsoft’s very successful Language Server Protocol.
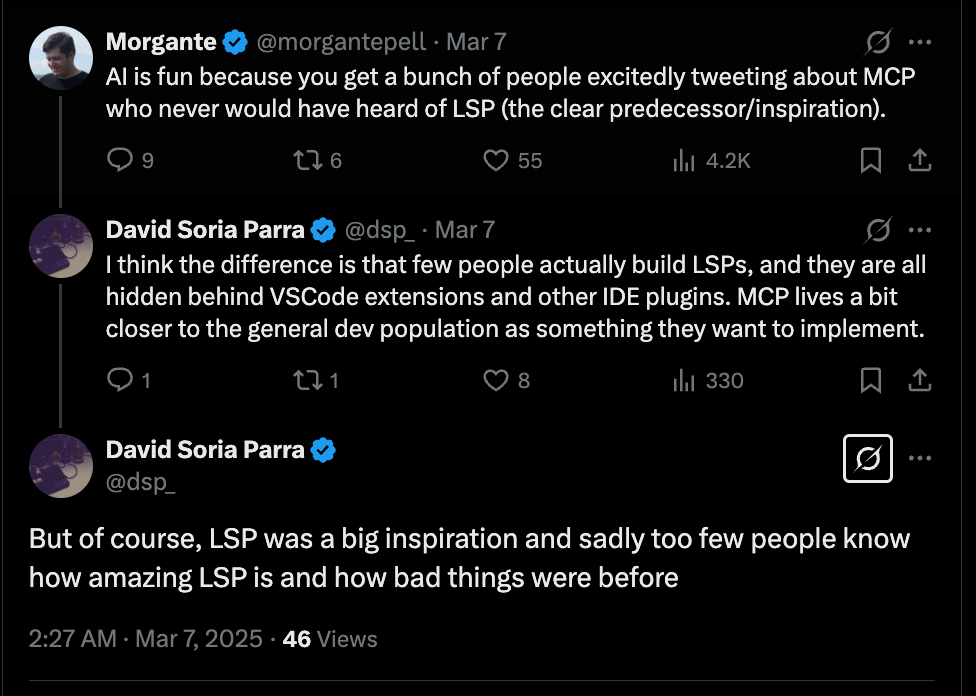
And again, from the workshop, a keen awareness of how MCP compares to LSP:
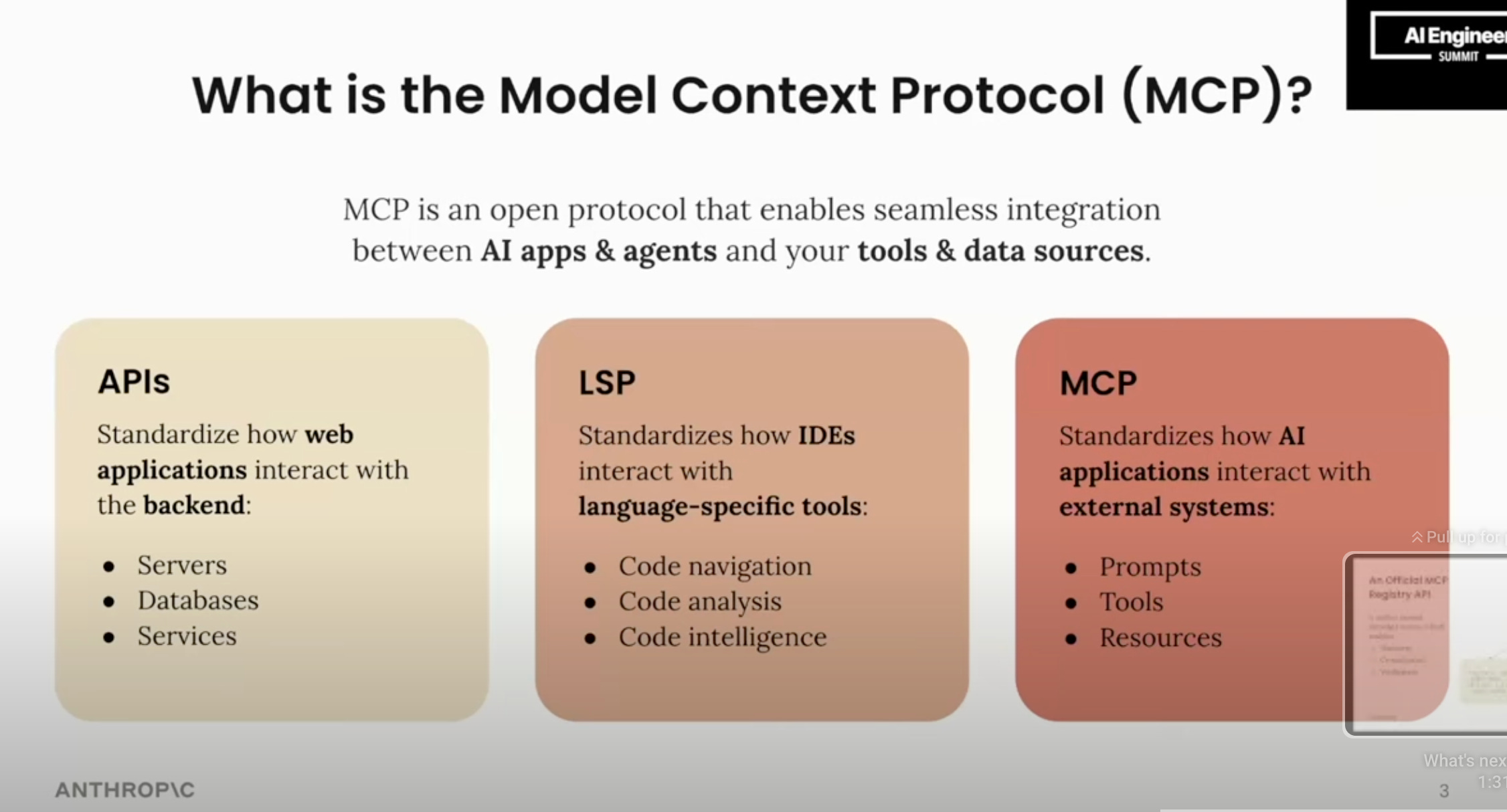
The best way to understand this point is to look at any other open source AI-native competitor that tried to get mass adoption, and then try to think about how easy it might be for you to add them to Cursor/Windsurf as easily as an MCP. The basic insight is fungibility between clients and servers: Often these competitors are designed to be consumed in one way — as open source packages in another codebase — rather than emitting messages that can be consumed by anyone8. Another good choice was sticking to JSON RPC for messages - again inheirited from LSP.
Hence MCP wins over other standard formats that are more “unproven”.
MCP dogfooded with complete set of 1st party client, servers, tooling, SDKs
MCP launched with:
Client: Claude Desktop
Servers: 19 reference implementations, including interesting ones for memory, filesystem (Magic!) and sequential thinking
Tooling: MCP Inspector, Claude Desktop DevTools
SDKs: Python and TS SDKs, but also a llms-full.txt documentation
Since then, the more recent Claude Code also sneaked in a SECOND official MCP client from Anthropic, this time in CLI form:
This all came from real life use cases from Anthropic developers.
Hence MCP wins over less dogfooded attempts from other BigCos like Meta’s llama-stack.
MCP started with a minimal base, but with frequent roadmap updates
One of the most important concepts in devtools is having a minimal surface area:
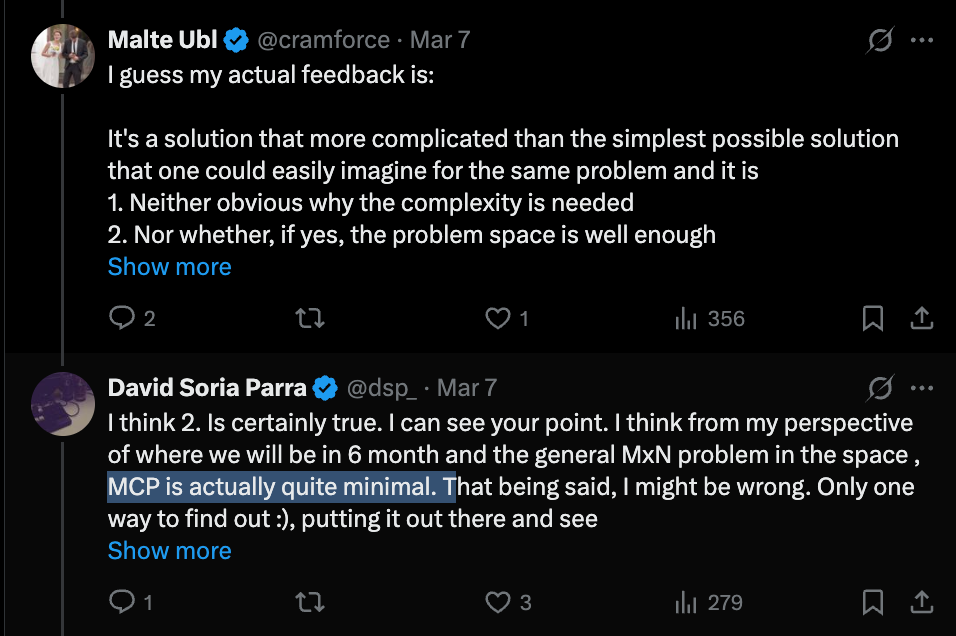
Reasonable people can disagree on how minimal MCP is:
But you can’t deny the consistent pace of the MCP roadmap updates:

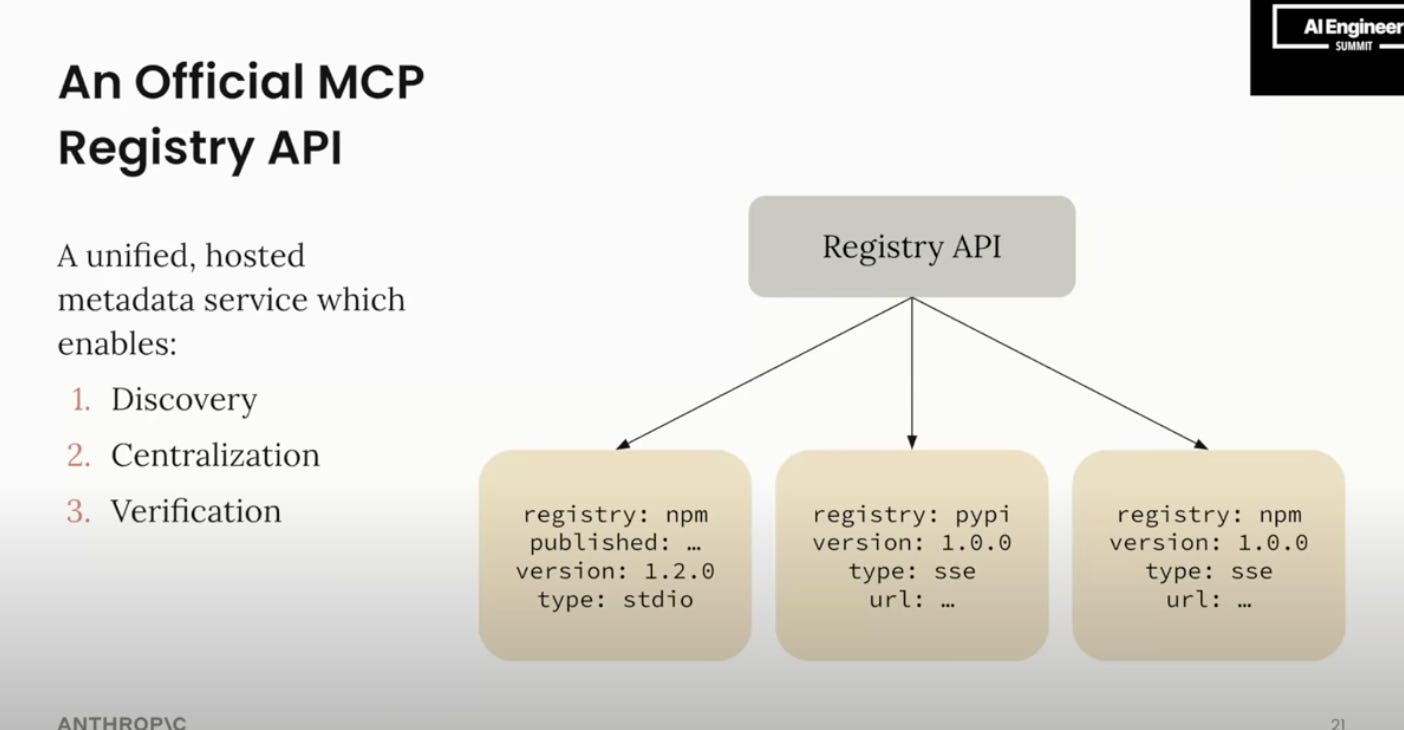
And of course the new updates dropped during the workshop: plans for an official MCP registry (which would of course immediately become the #1 registry, though people are excited about decentralized registries):
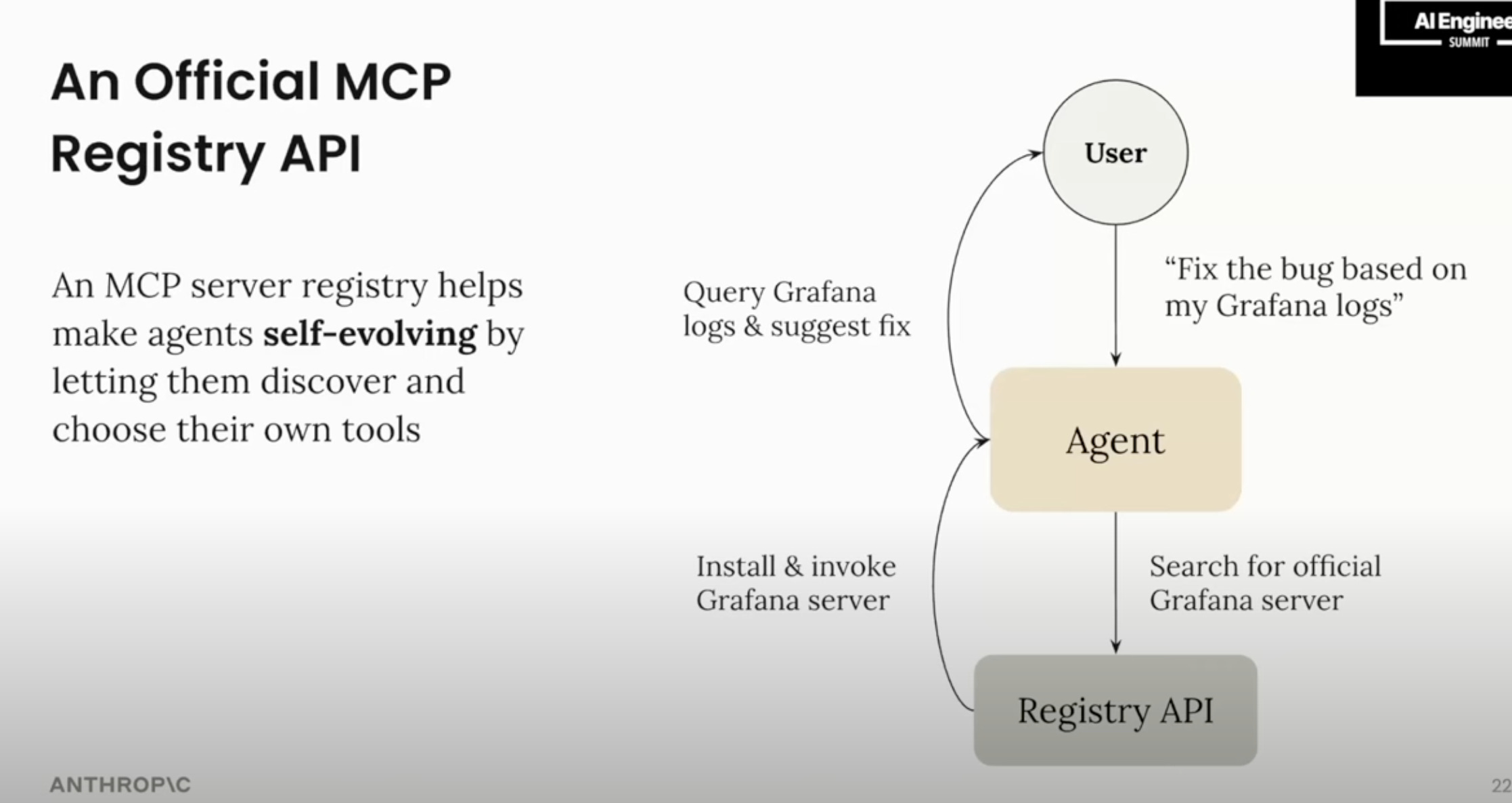
Remote server discovery:
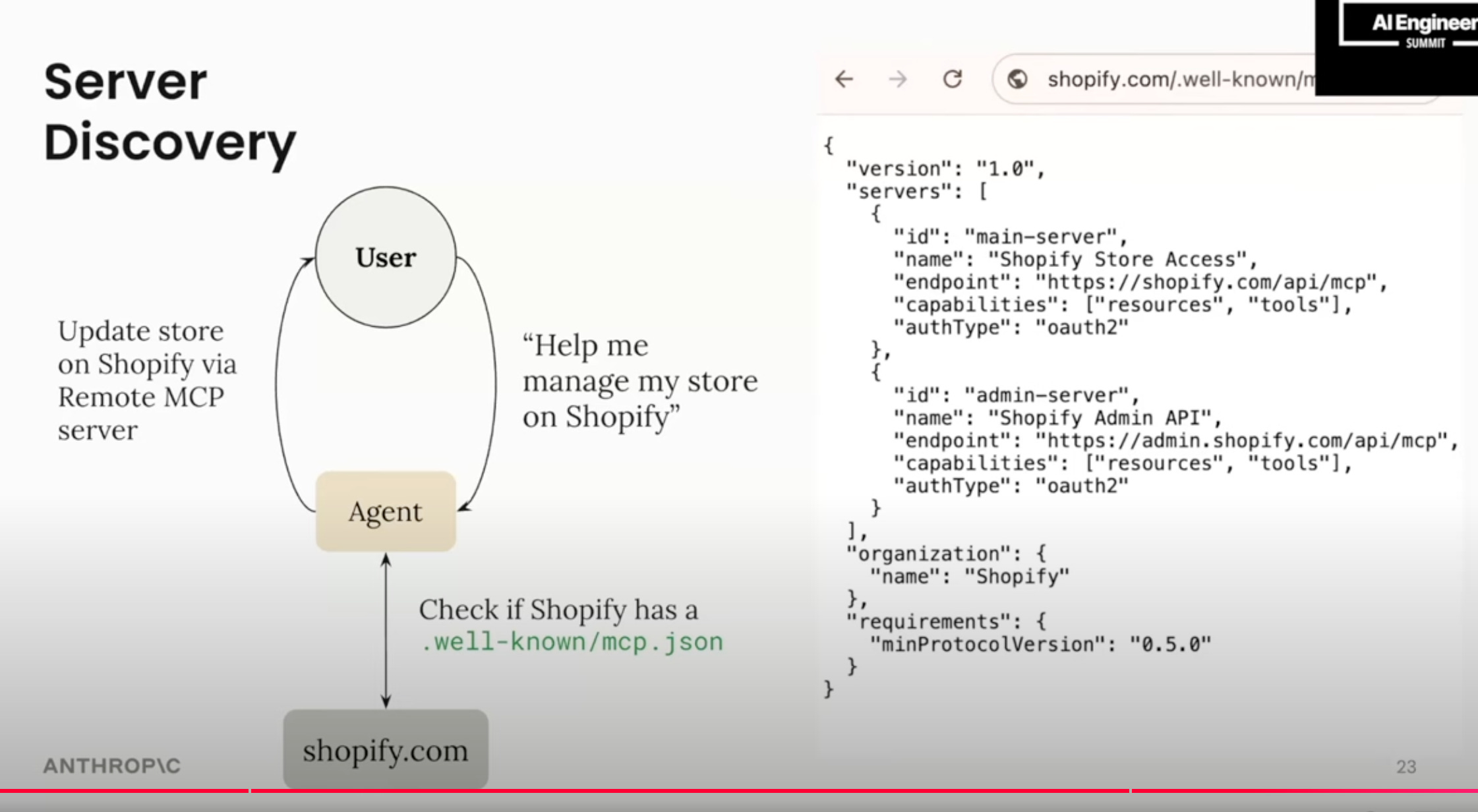
and more:

Hence MCP wins over other standards that launch and then don’t sustain momentum.
Your Turn
Did I miss any other reasons? Please feel free to write in below and I’ll ack the notable ones!
Bonus: MCP Workshop Transcript
For my research I transcribed the whole workshop with timestamps, so I’ll leave you with the transcript to browse and search, lightly cleaned up by Claude. Enjoy!
Today, we're going to talk about the philosophy behind MCP and why we at Anthropic thought that it was an important thing to launch and build. We're going to talk about some of the early traction of MCP in the last couple of months, and then some of the patterns that allow MCP to be adopted for AI applications, for agents, and then the roadmap and where we're going from here.
[00:01:14] Introduction to MCP and its Motivation
Cool. So our motivation behind MCP was the core concept that models are only as good as the context we provide to them. This is a pretty obvious thing to us now, but I think a year ago, when most AI assistants or applications were chatbots, you would bring in the context to these chatbots by copy pasting or by typing or kind of pasting context from other systems that you're using. But over the past few months, in the past year, we've seen these evolve into systems where the model actually has hooks into your data and your context, which makes it more powerful and more personalized. And so we saw the opportunity to launch MCP, which is an open protocol that enables seamless integration between AI apps and agents and your tools and data sources.
The way to think about MCP is by first thinking about the protocols and systems that preceded it. APIs became a thing a while ago to standardize how web apps interact between the front end and the back end. It's a very complex process. It's a kind of protocol or layer in between them that allows them to translate requests from the back end to the front end and vice versa. And this allows the front end to get access to things like servers and databases and services.
LSP came later, and that standardizes how IDEs interact with language specific tools. LSP is a big part of our inspiration, and it's called Language Server Protocol, and allows an IDE that's LSP compatible to go through the same process as a server protocol. So you can go and talk to and figure out the right ways to interact with different features of coding languages. You could build a Go LSP server once, and any IDE that is LSP compatible can hook into all the things about Go when you're coding in Go.
So that's where MCP was born. MCP standardizes how AI applications interact with external systems and does so in three primary ways and three interfaces that are part of the protocol, which are:
Prompts
Tools
Resources
[00:03:26] The Problem MCP Solves: Fragmentation
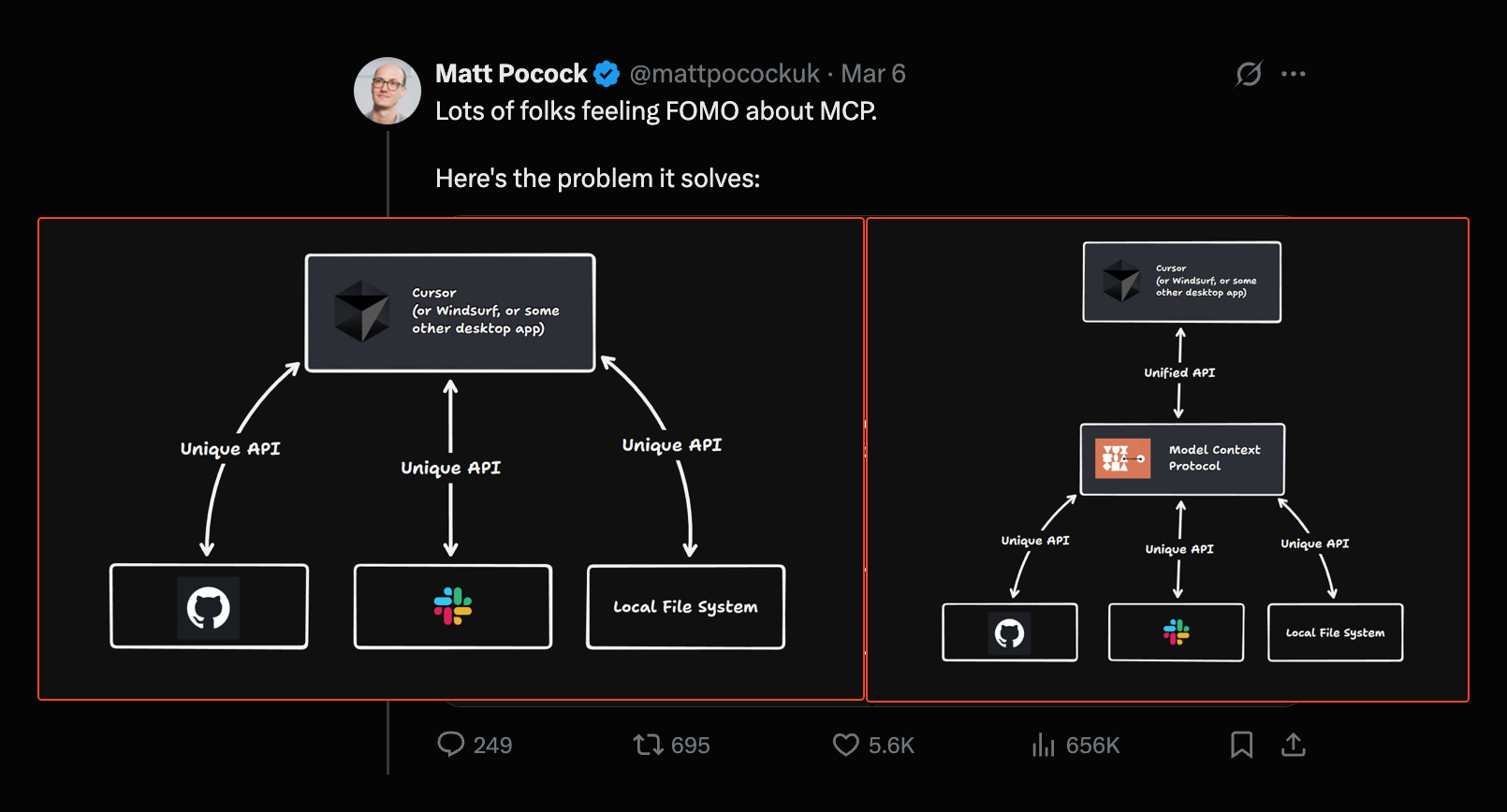
So here is the lay of the land before MCP that Anthropic was seeing. We spend a lot of time with customers and people trying to use our API to build these agents and AI applications. And what we were seeing is across the industry, but also even inside of the companies that we were speaking to, there was a ton of fragmentation about how to build AI systems in the right way. One team would kind of create this AI app that hooks into the system. And then the other team would create this AI app that hooks into their context with this custom implementation that has its own custom prompt logic with different ways of bringing in tools and data, and then different ways of federating access to those tools and data to the agents. And if different teams inside of a company are doing this, you can imagine that the entire industry is probably doing this as well.
The world with MCP is a world of standardized AI development. You can see in the left box, which is the world of an MCP client, and there's some client examples here, like our own first party applications. Recently applications like Cursor and Windsurf, agents like Goose, which was launched by Block, all of those are MCP clients. And there's now a standard interface for any of those client applications to connect to any MCP server with zero additional work.
An MCP server on the right side is any, it's a wrapper or a way of federating access to various systems and tools that are relevant to the AI application. So it could be a database to query and fetch data and to give the LLM access to databases and records. It could be a CRM like Salesforce where you want to read and write to something that is hosted on a remote server, but you want the LLM to have access to it. It could even be things on your local laptop or your local system, like version control and git, where you want the LLM to be able to connect to a server and access it.
[00:05:29] Value Proposition of MCP
We can talk about the value that we've seen for different parts of the ecosystem over the past few months. The value for application developers is once your client is MCP compatible, you can connect it to any server with zero additional work. If you're a tool or API provider or someone that wants to give LLMs access to the data that matters, you can build your MCP server once and see adoption of it everywhere across all of these different AI applications.
And just a quick aside, the way I like to frame this is before MCP, we saw a lot of the N times M problem, where there are a ton of different permutations for how these folks interact with each other, how client applications talk to servers, and MCP aims to flatten that. And be the layer in between the application developers and the tool and API developers that want to give LLMs access to these data.
For end users, obviously, this leads to more powerful and context rich AI applications. If you've seen any of the demos on Twitter with Cursor and Windsurf, even our own first party applications, you've seen that these systems are kind of context rich, and they actually know things about you and can go and take action in the real world.
And for enterprises, there's now a clear way to separate concerns between different teams that are building different things on the roadmap. You might imagine that one team that owns the data infrastructure layer has a vector DB or a RAG system that they want to give access to to other teams building AIOps. In a pre-MCP world, what we saw was every single individual team would build their own different way of accessing that vector database and deal with the prompting and the actual chunking while you're there. And that's the logic that goes behind all of this. But with MCP, an enterprise can have a team that actually owns the vector DB interface and turns it into an MCP server. They can own and maintain and improve that, publish a set of APIs. They can document it. And then all of the other teams inside their company can now build these AI apps in a centralized way where they're moving a lot faster without needing to go and talk to that team every time that they need access to it or need a way to get that data. And so you can kind of imagine this is like a world with microservices as well, where different people, different teams can own their specific service, and the entire company and the roadmap can move a lot faster.
[00:08:02] MCP Adoption and Usage
Cool. So let's talk about adoption. This is something that's been really exciting over the past couple of months. It kind of comes up in almost every Anthropic conversation with people that we work with and a lot of our customers. This slide covers a few different personas. But we can start with the first one. This is the AI applications and the IDEs. This has been really exciting recently, and it provides this really nice way for people that are coding in an IDE to provide context to the IDE while they're working. And the agents inside those IDEs go and talk to these external systems like GitHub, like documentation sites, etc.
We've also seen a lot of development on the server side. I think, to date, there are something like 1,100 community-built servers that folks have built and published open source. There are also a bunch of servers built by companies themselves. just built one as an example. There are folks like Cloudflare and Stripe and a bunch of others that have published official integrations for ways to hook into their systems. There's also a ton of adoption on the open source side as well. So people that are actually contributing to the core protocol and the infrastructure layer around it. So those are some of the things about what it actually means to build with MCP. And some of the core concepts that are part of the protocol itself.
[00:09:49] Building with MCP: Tools, Resources, and Prompts
Here's kind of the view of the the world of how to actually build with MCP. So on the the left side you have the MCP clients that invokes tools that queries for resources and interpolates prompts and and kind of fills prompts with useful context for for the model on the server side. The server builder exposes each of these things. They expose the tools. The tools, the resources, and the prompts in a way that's consumable by any client that connects to it. So let's talk about each of these components.
A tool is maybe the most intuitive and and the thing that's developed the most over the past few months. A tool is model controlled. And what that means is the server will expose tools to the client application, and the model within the client application. The LLM can actually choose when the best time to invoke those tools are. It's so if you use cloud for desktop or any of these agent systems that are MCP compatible. Usually the way this works is you'll interpolate various tools into the prompt. You'll give descriptions about how those tools are used as part of the server definition, and the model inside the application will choose when the best time to invoke those tools are. And these tools are kind of the possibilities are kind of endless. I mean it's read tools to retrieve data. It's right tools to go and send data to applications. Or kind of take actions in various systems. It's tools to update databases to write files on your local file system. It's kind of anything.
Now we get to resources. Resources are data exposed to the application, and their application controls. What that means is the server could define or create images. It could create text files json. Maybe it's keeping track of you know the actions that you've taken with the server within a json. File, and it exposes that to the application, and then it's up to the application how to actually use that resource. Resources provide this rich interface for applications and servers to interact that go just beyond you talking to a chatbot using text. So some of some of the use cases we've seen for this are files where the server either surfaces a static resource or static file, or a dynamic resource where the client application can send the server. Some information about the user about the file system that they're working in, and the server can interpolate that into this more complex data structure and send that back to the client application. Inside cloud for desktop resources manifest as attachments. So we let people when they're interacting with the server go and click into our Ui. And then select a resource, and it gets attached to the chat and optionally sent to the model for whatever the user is working on. But resources could also be automatically attached. You could have the model decide. Hey, I see that there's this list of resources. This one is super relevant to the task we're working on right now. Let me automatically attach this to the chatter or send it to the model, and then proceed from there.
And finally, prompts. Prompts are user controlled. We like to think of them as the tools that the user invokes as opposed to something that the model invokes. These are predefined templates for common interactions that you might have with the specific server. A really good manifestation of this i've seen is in the Ide called Zed, where you have the concept of slash commands where you're talking to the Lom to the agent, and you say, Hey, i'm working on this Pr. Can you go and summarize the the work that i've done so far? And you just type slash ghpr you give it the Pr. Id, and it actually will interpolate this longer prompt that's predefined by Zed inside of the the Mtp server, and it gets sent to the Lm. And you generate this really nice full data structure or full prompt that you can then send to the LM itself. A few other common use cases that we've seen are different teams have these standardized ways of let's say, doing document Q. And a maybe they have formatting rules they have, you know, inside of a transcript. They'll have a different speakers and different ways they want the data to be presented. They can service that or surface that inside the server as a prompt. And then the user can choose what they want. When it makes the most sense to invoke.
[00:14:14] Q&A: Tools vs. Resources, Agent Frameworks, and More
Well, i'll pause there any questions so far about these various things, and how they they all fit together. Yeah, in the back. Yeah, I think we a big part of Mcp. Sorry. The question is, Why aren't resources modeled in the same way as tools? Why couldn't they have just been tools? A big part of the thinking behind Mcp. Broadly is it's not just about making the model better. It's about actually defining the ways that the application itself can kind of interact. With the the server in these richer ways. And so tools are typically model controlled, and we want to create a clean separation between what's model controlled and application controlled. So you could actually imagine an application that's Mcp. Compatible decides when it wants to put a resource into context. Maybe that's based on predefined rules maybe that's based on it makes an llm call and makes that decision. But we wanted to create a clean separation for the client builder and the server builder. So therefore, what should be invoked by the the model, and what should be invoked by the application? I saw you go first. Yeah, the question is, are tools the right way to expose, let's say, a vector database to to model the answer. It's kind of up to you. We think that these are really good to use when it's kind of ambiguous. When a tool should be invoked. So maybe the lm sometimes should go and call a vector db. Maybe sometimes it already has the information in context, and sometimes it needs to go talk to maybe you need to go ask the user for more information before it does a search. So that's probably how we think about it if it's predetermined, then you probably don't need to use a tool. You just always call that vector db. Sorry. this right now. You just inject them as
[00:16:45] I'm gonna get to that one later, because it's very relevant, and we have a lot to say.
[00:16:51] So I may have missed this on that. So if you've gone down the route of using the agenda framework, which did school calling. If you progress, would you just wrap the mcp with a tool that you had a system solution.
[00:17:11] Yeah, I think that it sounds like the broader question is how does mcp fit in with agent frameworks? Cool. Yeah, I mean, the answer is they kind of complement each other actually land graph just this week, released a bunch of connectors for I think they're called adapters for land graph agents to connect to MCP. So, if you already have a system built inside land graph or another agent framework. If it has this connector to MCP servers. You can expose those servers to the agent without having to change your system itself as long as that adapter is installed. So we don't think mcp is going to replace agent frameworks. We just think it makes it a lot easier to hook into servers to all problems and resources in a standardized way. Okay, so if I can have some piece of it, or will this would just be a rapper.
[00:18:04] Yeah, the, the framework could call it tool and that tool could be exposed to that framework from an MCP server. If the adopter exists. Does that make sense.
[00:18:17] I'll take one more if there are. Yeah.
[00:18:35] So, the question is kind of does mcp release replace an agent framework and why still use one. I don't think it replaces them. I think parts of it, it might replace the parts related to bringing context into the agent and calling tools and invoking these things but a lot of the agent frameworks value I think is in the knowledge management. And the agent take a loop. And how the agent actually responds to the data that's brought in by tools. And so, I would think that there's still a lot of value in something where the agent framework defines how the LM is running in the loop, and how it actually decides when to invoke the tools and reach out to other other systems but I don't think mcp as a protocol itself fully replaces it mcp is more focused on being the standard layer to bring that context. To the agent or to the agent framework. Yeah, I don't know if that's the most clear answer but that that's the one that we've at least seen so far, that might change as mcp involves.
[00:19:41] Sorry I saw one more which I'll take and then I will move on if that exists. Yeah.
[00:20:30] Yeah, so the question is, why do resources and prompts exist and why isn't this all baked into tools because you can serve a lot of the same context via tools themselves. So I think we touched on this a little bit, but there's actually a lot more. Protocol capabilities built around resources and prompts than what I'm talking about here. So, part of your question was aren't resources and prompts static, can't they just be served as static data as part of a tool. In reality, resources and prompts and mcp can also be dynamic, they can be interpolated with context that's coming in from, from the user or from the application, and then the server can return a dynamic or kind of customized resource or customized prompt based on the task at hand. Another kind of really valuable thing we've seen is resource notifications, where the client can actually subscribe to a resource. And anytime that resource gets updated by the server with new information with new context, the server can actually notify the client and tell the client, hey, you need to go update the state of your system or surface new information to the user. But the broader answer to your question is, yes, you can do a lot of things with just tools. But mcp isn't just about giving the model. More context it's about giving the application, richer ways to interact with that the various capabilities the server wants to provide. So it's not just, you want to give a standard way to invoke tools it's also if I'm server builder, and I want there to be a standard way for people to talk to my application. Maybe that's a prompt maybe I, you know, I have a, a prompt that's like a five step plan for how someone should invoke my server, and I want the. The client applications of the users to have access to that. That's a different paradigm because it's me giving the user access to something, as opposed to me giving the tool access to something. And so I kind of tried to write this out as model control application controlled and user controlled. The point of mcp is to give more control to each of these different parts of the system as opposed to only just the model itself. Yeah, I hope that that kind of makes sense.
[00:22:46] Demo: Cloud for Desktop and GitHub/Asana Integration
All right. Okay. Let's see what this actually looks like the Wi Fi is a bit weird. This works cool. So what we're looking at is cloud for desktop, which is an mtp client. Let me try to pause as this goes through so cloud for desktop, which is on the left side and a TV client, and on the right side I'm working inside of a GitHub application. Let's say I'm a repo maintainer for the anthropic Python SDK need to get some work done. What I'm doing here is I give the cloud for desktop app. The URL of the, the repo I'm working in, and I say, Can you go and pull in the issues from this GitHub repo, and help me triage them or help suggest the ones that that sound most important to you. The model Claude automatically decides to invoke the list issues tool, which it thinks is the most relevant here, and actually pulls calls that and pulls these into context and sort of summarizing it for me. You'll also notice that I told it to triage them so it's automatically using what it knows about me. From my previous interactions with Claude, maybe other things in this chat or in this project to kind of intelligently decide. Here are the top 5 that sound most important to you, based on what I know about you. And so that's where they interplay between just giving models tools, and actually the application itself, having other context about who I am, what I'm working on, the types of ways I like to interact with it. And then those things interplay with each other. The next thing I do is, can you I ask it? Can you triage the top 5? The top 3 highest priority issues and add them to my Asana project. I don't give it the name of the Asana project. But Claude knows that it needs to go and find that information autonomously. So i've also installed an Asana server and has that has like 30 tools. It first decides to use list workspaces, then search projects. It finds the project, and then it starts invoking tools to start adding these as as tasks inside Asana. So this might be a pretty common application. But the the things I want to call out are one. I didn't build the Asana server or the Github server. These were built by the community. Each of them are just a couple hundred lines of code. Primarily it's a way of surfacing tools to the server and so it's not a ton of additional logic to build. I would expect they could be built in an hour. And they're all kind of playing together with Claude for desktop being the central interface. It's really powerful to have these various tools that someone else built for systems. But I care about all interplaying on this application that I like to use every single day. Claude clock for desktop kind of becomes the central dashboard for how I bring in context from my life, and I actually like run my day to day. And so inside Anthropic we've been using things like this a ton to go and reach out to you know our architect repos to even make prs or to bring in context from prs. And Mtp is the standard layer across all of us. Cool. And so just to close that out here's windsurf and it's an example with using different servers. But it's windsurf's own application layer for connecting to Mcp. They have their own kind of Ui inside of their agent. It's their own way of talking to the Mcp tools. Other applications don't even call them Mcp tools, for example, boost calls them extensions. It's really up to the application builder how to actually bring this context into the application. The point is that there's a standard way to do this. Across all of these applications.
[00:26:23] MCP as the Foundational Protocol for Agents
Awesome. So so far we've talked about how to bring context in a how Mcp brings context into a lot of Ai applications that you might already be familiar with. But the thing that we are most excited about and starting to see signs of is that Mtp will be the foundational protocol for agents broadly. And there's a few reasons for this one is the the actual protocol features and the capabilities that we're going to talk about in just a second. But it's also the the fact that these agent systems are becoming better, that the models themselves are becoming better, and they use the data you can bring to them in increasingly effective ways. And so we think that there's some really nice tailwinds here. And and let's talk about how or why we think that this is going to be the case.
[00:27:13] MCP and Augmented LLMs
So you might be familiar with the the blog that we put out. My friends, Barry and Eric put out a couple months ago called Building Effective Agents. And one of the core things in the blog that one of the first ideas that was introduced is this idea of an augmented LLM. It's an LLM in the the traditional way that it takes inputs. It takes outputs, and it it kind of uses its intelligence to decide on some actions. But the augmentation piece are those arrows that you see going to things like retrieval systems to tools and to memory. So those are the things that allow the LLM to. Query and write data to various systems. It allows the LLM to go and invoke tools and respond to the results of those tools in intelligent ways. And it allows the the LLM to actually have some kind of state such that every interaction with it isn't a brand new fresh start. It actually kind of keeps track of the progress that's made as it goes on. And so MCP fits in as basically that entire bottom layer. MCP can federate and make it easier for these LLMs. To talk to retrieval systems to invoke tools to bring in memory, and it does so in a standardized way. It means that you don't need to pre-build all of these capabilities into the agent when you're actually building it. It means that agents can expand after they've been programmed even after they've been initialized, and they're starting to run to start discovering different capabilities and different interactions with the world. Even if they weren't programmed or built in. And the core thing in the blog or one of the simpler ideas in the blog is agent systems at its core aren't that complicated. They are this augmented LLM concept running in a loop where the augmented LLM goes and does a task. It kind of works towards some kind of goal. It invokes a tool, looks at the response, and then does that again and again and again until it's done with the task. And so where MCP fits in is, it gives the LLM the augmented LLM these capabilities in an open way. What that means is, even if you as an agent builder don't know everything that the agent needs to do from the time at the time that you're building it. That's okay. The agent can go and discover these things as it's interacting with the system, and as it's interacting with the real world. You can let the users of the agent go and customize this and bring in their own context in their own ways that they want the agent to talk to you about. Their data, and you as the agent builder can focus on the core loop. You can focus on context management. You can focus on how it actually uses the memory, what kind of model it uses. The agent can be very focused on the actual interaction with the LLM at its core. So I want to talk about a little bit about what this actually looks like in practice. Let me switch over to screen sharing my screen.
[00:30:15] Demo: MCP Agent Framework
Cool. So to talk about this. We're going to be talking about this framework, this open source framework called MCP agent that was built by our friends at Last Mile AI. I'm just using it as a really clean and simple example of how we've seen some of these agent systems kind of play in with MCP. So I'm switching over to my code editor. Make this bigger. And what you see here is a pretty simple application. The entire thing is maybe 80 lines of code. And I'm defining a set of agents inside of this Python file. The overall task that I want this agent to achieve is defined in this task.md. And basically I wanted to go and do research about quantum computing. I want it to give me a research report about quantum computing's impact on cybersecurity. And I tell it a few things I want. I want to go look at the Internet, synthesize that information, and then give that back to me in this nicely formatted file. And so what MCP agent, the framework, lets us do is define these different sub-agents. The first one I'm defining is what's called a research agent, where I give it the task that it's an expert web researcher. Its role is to go look on the Internet, to go visit some nice URLs, and to give that data back in a nice and structured way in my file system. And you'll see on the bottom is I've given it access to a few different MCP servers. I've gave it access to Brave for searching the web. I've given it a fetch tool to actually go and pull in data from the Internet, and I've given access to my file system. I did not build any of those MCP servers, and I'm just telling it the name, and it's going to go and invoke them and install them and make sure that the agent actually has access to them. The next one, similarly, is a fact-checker agent. It's going to go and verify the information that's coming in from the research agent. It's using the same tools. Brave, Fetch, and File System. And these are just MCP servers that I'm giving it access to. And finally, there's the research report writer agent, and that actually synthesizes all the data, looks at all the references and the fact checking, and then produces a report for me in this nice format. This time I'm only giving it the file system and fetch tools or servers. I don't need it to go look at the Internet. I just need it to process all the data that it has here.
[00:32:55] MCP Agent Framework Continued
And it knows what servers each of them have access to. And then once I kick it off, the first thing it's going to do is go and form a plan. A plan is just a series of steps for how it should go and interact with all these systems and the various steps you should take until it can call the task done. So, as an example, the first step it's going to go and look at authoritative sources on quantum computing, and it's going to invoke the searcher agent in various different ways. It knows. It creates this plan based on the context about the agent's task about the servers that has access to. And so on. The next step is maybe it goes and verifies that information by focusing on the fact checker agent specifically. And then finally, it intends to use the writer agent to go and synthesize all of this. The kind of core piece of this is MCP becomes this abstraction layer where the agent builder can really just focus on the task specifically. And the way that the agent should interact with the systems around it, as opposed to the agent builder having to focus on the actual servers themselves, or the tools or the data. It just gives it kind of declares this in this really nice declarative way of this is what your task is supposed to be. And here the servers are tools that you have available to you to go and accomplish that task. And so just to close out that part of demo i'm just going to kick this off. And what's going to be going on in the background? Is it? It's going to start doing some research. It's invoking the search tool. The search agent, and it's going to invoke the fact checking agent, and you'll start to see these outputs appear on the left side of the screen. And so this is a pretty simple demo but I think it's a very powerful thing for agent builders, because you can now focus specifically on the agent loop, and on the actual core capabilities of the agent itself and the tasks that the sub agents are working on, as opposed to on the server capabilities. And the ways to provide context to those agents. The other really nice piece of this which is obvious is we didn't write those servers. Someone else in the community built them. Maybe the the most authoritative, you know, source of research papers on quantum computing wrote them. But all we're doing is telling our agents to go and interface with them in a specific way. And so you start to see the the outputs form the it looks like the searcher agent put a bunch of sources in here. It's already started to draft the the actual final report, and it's going to continue to iterate in the background.
[00:35:37] Q&A: Agent Systems for Proprietary Data, Agent Logic Separation, and More
Definitely. Yeah. So the question is, have we seen agent systems also working for proprietary data? The really nice thing about Ncp again is that it's open, and so you can actually run Ncp servers on inside your own Vpc. You can run it on top of on your your employees. Individual systems and laptops themselves. So the answer is definitely yeah.
[00:36:31] Yeah. So the question is, what does it mean to separate the agent itself? And now the capabilities that other folks kind of give to it. I I think the answer kind of varies some of the ways that we've seen to improve agent systems are you know what kind of model do you use? Is it actually the right model for the specific task? If you're building a coding agent, or probably you should use use cloud. And there's also things like context management or knowledge management. How do you store the the context and summarize it, or compress that context as the context window gets larger? There's orchestration systems like if you're using multi-agent. Are they in series? Are they in parallel? And so there's a lot more that you can focus on based on your task in that sense, as well as the interface itself. Like, how is the surface to the user? and the separation? Is then maybe you build a bunch of your own Mcp. Servers for your agents that are really really customized to what you want to do. But when you want to expand the context to what the rest of the world is also working on, or the systems that exist in the rest of the world. That's where Mcp. fits in like you don't need to go and figure out how to hook into those systems. That's all pre-built for you let's do. Yeah, that anyway. What we call tools here?
[00:38:19] Yes, there is a slide that we'll get to which is exactly that. No, you're good. No, that's great really good questions. Let's i'm gonna do this side of the room because I didn't. Yeah. Yeah, not a ton of this is specific to last mile. I think it's a really great framework it's called Mcp. Dash agent, and specifically what they worked on is they saw these things come out. One one was the agent's framework there's really simple ways to think about agents, and they saw Mcp. Which is there are really simple ways to think about bringing context to agents. And so they built this framework which allows you to implement the various workflows that were defined in the agents. Blog post using Mcp. and using these really nice declarative frameworks. So what's specific to Mcp. agent. The the framework is these these different components or building blocks for building agents. So one is the concept of an agent an agent as we've talked about is an augmented Lm. Running in a loop. So when you invoke an agent you give it a task. You give it tools that it has access to, and the framework takes care of running that in a loop. It takes care of the Lm. that's under the hood and all of those interactions. And then, using these building blocks, you go a layer above, and you hook those agents together in different ways that are more agentic, and those are described in the paper. But one of the things in the in the blog post was this orchestrator workflow example. So that's what i've implemented here, which is i've initialized an orchestrator agent, which is the one in charge of planning and keeping track of everything. And then I give it to give it access to these various subagents. Using all these nice things that are part of that being said it's open source like it's not that i'm blessing. This is the right way to do it necessarily, but it's a really simple and elegant way of doing it. Sorry there a lot. Yeah, yeah. So the question is, how do resources and prompts fit in in this case? The answer is, they don't. This example was more focused on the agentic loop and giving tools to them. I would say resources and prompts come in more where the user is within the loop. So you might imagine instead of me just kicking this off as a python script. I have this nice Ui where i'm talking to the agent, and then it goes and does some asynchronous work in the <\ctrl75>background, and it's a chat interface like what you might see with Claude in that case. The chat interface. The application could you know, take this plan that I just showed you and surface this to me as a resource. The application could have this nice Ui on the side that says, Here's the the first step, the second step, the third step. And it's getting that as the server surfaces it to surface is the plan to it as as this kind of format. Prompts could come in if there's a few examples. But you could say a slash command to summarize all of the steps that have occurred already. You could say slash summarize and there's a predefined prompt inside of the server that says, Here's the right way to give the user a summary. Here's what you should provide to the Lm. When you go and invoke the summarization. So the answer to your question is, it doesn't fit in here. But there are ways it could. Yeah, i'll take like 2 more. That's good with you. this introduce any like news? It relates to like evaluations. you're it's choosing the right tool.
[00:42:39] Q&A: MCP and Evaluations, Logic Placement, and More
I think the answer to the question is, How did this fit into evaluations? In particular evals related to assessing tool calls. And that's being done the right way. I think largely it should be the same as it is right now. There is potential to have Mcp. Be even a standard layer inside evals themselves. I probably need to think this through but you can imagine that there's an Mcp. Server that surfaces you know the same 5 tools, and you give that server to one set of evals. You also let's say you have one eval system running somewhere. To eval like these 5 different use cases. They have a different eval system. The Mcp. Server could be the standard way to surface the tools that are relevant to your company to both of them. But largely I think it's similar to how it's been done already.
[00:43:46] get to that. Yeah, I can address part of this. So the question is, where what is the separation between a lot of the the logic that you need to implement in these systems? Where should it sit? Should it sit with the client or the server? And the specific examples are things like retry logic authentication. I'll get to often a bit, but on things like retry logic. I think my personal opinion, and I think this remains to see be seen. How it shakes out is a lot of that should happen on the server side. The server is closer to the end application and to the end system that's actually running somewhere, and therefore the server should have more control over the interactions with that system. A big part of the design principle is ideally Mcp. Supports clients that have never seen a server before. They don't know anything about that server before the first time it's connected, and therefore they shouldn't have to know the right ways to do retries. They shouldn't have to know you know how to do logging in the exact way that the server wants and things like that. So the server is ideally closer to the end application, and it's the one that's the end service, and it's the one that's implementing a lot of that business logic.
[00:45:54] It depends. I don't have a really strong opinion to take on on where the agent frameworks themselves go. I could see one counter argument being that you don't always want the server builders to have to deal with that logic either. Like maybe the server builders want to just focus on exposing their Apis and like letting all the agents do the work.
[00:46:18] And yeah, I want to say I don't have a really strong take on that. that's a really good question. But you asked that. So a lot of the questions that we get sorry. The question here is, is there a best practice or a limit to the number of servers that you expose to an LM? In practice, the models of today, I think, are good up to like 50 or 100 tools like Claude is good up to a couple hundred in my experience. But beyond that, I think the the question becomes, how do you search through or expose tools in the right way without overwhelming the context with those, especially if you have thousands? And I think there are a few different ways. Like one of the ones that's exciting is a tool to search tools. And so you can imagine a tool abstraction that implements rag over tools. It implements fuzzy search or keyword search based on you know the entire library of tools that's available. That's one way we've also seen like hierarchical systems of tools. So maybe you have a group of tools that's you know finance tools. You have like read data. Then you have a group of tools that's for writing data. And you can progressively expose those groups of tools based on the current task at hand, as opposed to putting them all in the system, for example. So there are a few ways to do it. I don't think everyone's landed on one way. But the answer is, there's technically no limit if you implement it the right way.
[00:47:50] or best practice life. I haven't seen the steps like you take like first to find the server.
[00:47:58] Promises and resources like. Are you going to kind of walk with you?
[00:48:06] Yeah, I'm not going to go through it yet, but we do have that documented. So the question is like, what are the right steps to approach building an MCP server? What's the order of operations? We actually have this entire docs page that's like, How do you build an MCP server using Claude or using Lms? All the servers that we launched with in November. I think there were like 15 of them. I wrote all of those in like 45 min. Each with Claude. And so it's like really easy to approach it. And I think tools are typically the best way for people to start rocking what a server is, and then going to prompts and resources from there. Yeah, definitely. I'll share links later. Yeah, in the red.
[00:48:49] generic? What?
[00:48:56] Hmm.
[00:49:21] So the question is, if a lot of these servers are simple, can lms just generate them automatically? The answer is yes. If you guys have heard of Klein, which is one of the most popular ids that's open source, it has like 30 K stars on Github. They actually have an MCP auto generator tool inside the app. You can just say, Hey, I want to start talking to Gitlab. Can you make me a server and just auto generates on the fly?
[00:49:51] That being said, I think that that works for like the simpler servers, like the ones that are closer to just exposing an API. But there are more complex things that you want to do. You want to have logging or logic or data transformations. But the answer is, yeah, for the more simple ones. I think that's a pretty normal workflow.
[00:50:20] Yeah. So question is, are we talking to the actual owners of the services and the data? Answer is yes. A lot of them, a lot of the servers actually are official and public already. So if I just scroll through official integrations, these are like real companies like Cloudflare and Stripe that have already built official versions of these. We're also talking to bigger folks, but I can't speak to that yet.
[00:50:49] They might also host the servers remotely. Yes. they'll build it and then they also maybe provide the infrastructure to expose it. Yeah. In the back.
[00:51:08] You're asking about versioning as it relates to the protocol or to servers? Yeah. So the question is, how do we do best practices for versioning? All these servers are so far, a lot of them are TypeScript packages on npm or on pip. Therefore, they also have version package versions associated with them. And so there shouldn't generally be code breaking changes. There should be a pretty clear upgrade path. But yeah. I don't think we actually have best practices just yet for what to do when a server itself changes. For something like, I mean, generally, I think it might break the workflow, but I don't think it breaks the application if the server changes. Since as long as the client and server are both following the MCP protocol, the tools that are available might change over time, or they might evolve. But the model can still invoke those in intelligent ways for resources and prompts. They might break users' workflows if those resources and prompt changes, but they'll still work as long as they're being exposed as part of the MCP protocol with the right list tools, call tools, list resources, etc. I don't know if that answers your question, though.
[00:52:25] Right. I think using versioning of the packages themselves makes sense for that. And then I'm going to talk a little bit about a registry and having a MCP registry layer on top of all of this will also help. Yeah. Okay, I'll take one more and then continue. Yeah.
[00:53:02] Question is, how are we thinking about distribution and extension system? I'll get there too. Cool. Let's keep going.
[00:53:13] Protocol Capabilities for Agents: Sampling and Composability
So we've talked about one way to build effective agents, and I showed how to do that using the MCP agent framework. Now I want to talk about the actual protocol capabilities that relate to agents and building agentic systems. With the caveat that these are capabilities in the protocol. But it's still early days for how people are using these. And so I think a lot of this is going to evolve. But these are some early ideas. So one of the most powerful things that's underutilized about MCP is this paradigm called sampling. Sampling allows an MCP server to request completions, aka LLM inference calls from the client, instead of the server itself having to go and implement interaction with an LLM or to go host an LLM or call cloud. So what this actually means is, you know, in typical applications, the one that we've talked about so far, it's a client where you talk to it, and then it goes and invokes server to have some kind of capability to get user inputs, and then decide, hey, I actually don't have enough input from the user, let me go ask it for more information, or let me go formulate a question that I need to ask the user to give me more information. And so there's a lot of use cases where you actually want the server to have access to intelligence. And so sampling. Sampling allows you to federate these requests by letting the client own all interactions with the LLM, they can, the client can own hosting the LLM if it's open source they can own. You know what kind of models it's actually using under the hood, and the server can request inference, using a whole bunch of different parameters so things like model preferences, maybe the server says hey I actually really want, you know, specifically, this version of Claude, or I want a big model or small model. Do your best to get me one of those. The server obviously will pass through a system prompt and a task prompt to the client, and then things like temperature max tokens it can request. The client doesn't have to listen to any of this, the client can say, hey, this looks like a malicious call like I'm just not going to do it, and the client has full control over things like privacy over the cost parameters maybe it wants to limit the server to, you know, a certain number of requests. But the point is that. This is a really nice interaction because one of the design principles, as we talked about is oftentimes these servers are going to be something where the client has never seen them before. It knows nothing about them yet it still needs to have some way for that server to request intelligence. And so we're going to talk about how this builds up a little bit to agents but just putting this out there as something you should definitely explore, because I think it's a bit underutilized thus far.
[00:56:17] Protocol Capabilities for Agents: Composability
Cool. One of the other kind of building blocks of this is the idea of composability. So I think someone over there asked about composability which is a client in a server is a logical separation. It's not a physical separation. And so what that means is any application or API or agent can be both an MCP client and an MCP server. So if you look at this this very simple diagram, let's say I'm the user talking to cloud for desktop on the very left side and that's where the LLM lives. And then I go and make a call to an agent I say hey can you go. You know, find me this information I asked the research agent to go through that work, and that research agent is an MCP server, but it's also an MCP client that research agent can go and invoke other servers. Maybe it decides it wants to call you know the file system server the fetch server the web search server. And it goes and makes those calls, and then brings the data back, does something with that data and then brings it back to the user. So there's this idea of chaining and of these interactions kind of. Hopping from the user to a client server combination to the next client server combination, and so on. And so this allows you to build these really nice complicated or complex architectures of different layers of LLM systems where each of them specializes in a particular task that's particularly relevant as well. Any questions about composability I'll touch on agents as well. Yeah. So the question is, how do you deal with compounding errors. If the system itself is as complex and multi layered. I think the answer is the same as it is for complex hierarchical like agent systems as well. I don't think MCP necessarily makes that more or less difficult. But in particular, in particular, I think it's up to each successive layer of the agent system to deal with information or controlling data as it's structured so like to be more specific. You know the third node there the kind of the middle client server node should collect data and fan in data from all of the other ones that just reached out to, and it should make sure it's up to par meets whatever data structure dates on spec. It needs to before passing that data to the system right before it. I don't think that's special to MCP I think that is true for all these like multi node systems. It's just this provides like a nice interface between each of them. Does that answer your question. Sorry I saw other hands.
[00:59:44] Q&A: Composability, Observability, and Debugging
Yeah, the question is, why are these and why do they have to be MCP servers as opposed to just a regular HTTP server. The answer in this case for composability and like the layered approach is that each of these can basically be agents, like in the system that you're kind of talking about here. It's, I think that there's, there are there are reasons for a bunch of protocol capabilities like resource notifications like server data. And then there's the server to client communication, the server requesting more information from the client that are built into the MCP protocol itself, so that each of these interactions are more powerful than just data passing between different nodes. Like let's say each of these are agents, like the first agent can ask the next agent for, you know, a specific set of data, it goes and does a bunch of asynchronous work talks to the real world, brings it back and then sends that back to the first client, which that might be multi step it might multiple interactions between each of those two nodes. And that's a more complex interaction that's captured within the MCP protocol that not might not be captured if it were just regular HTTP servers.
[01:00:59] I think that the point I'm trying to make is that each of these, so you're asking like if the Google API or the file system things were just API is like regular non MCP servers but MC making it an MCP server in this, at least in this case, allows you to capture those as agents as in like, they're more intelligent than just an agent. So it's not just, you know, exposing data to the LM, it's like the each of them has autonomy, you can give a task to the second server and it can go and make a bunch of decisions for how to pull in richer data. You could in theory just make them regular APIs but you lose out on like these being independent autonomous agents each node in that system, and the way it interacts with the task it's working on. In terms of controlling the web sorry. Great. Is that just kind of why.
[01:01:52] Yeah, I'm kind of depends on on the builders but I do think it's federated, because the LM is at the application layer. And so that has control over how random rate limits work or how it should actually interact with the LM. It doesn't have to be that way like in theory if the server builder, first node wanted to own the interaction with a specific LM. Maybe it's running open source on that specific node. It could be the one that controls the LM interaction, but in the example I'm giving here, the LM lives at the very base layer, and at the application there and it's the one that's controlling rate limits and control flow and things like that. follow this. If it wants user input it does have to go all the way back. Yeah, and MCP does allow you to pass those interactions all the way back and then all the way back forward. Yeah. I'm going to go on this side first.
[01:03:06] Yeah, the question is how do you elect a primary how you make decisions and network. The answer is it's kind of up to you I'm not a planning on like network systems themselves or how you know these these like logic. It's not a requirement it's not part of the protocol itself it's just that MCP enables this architecture to exist.
[01:03:42] So, I think the idea. So the question is how do you do observability How do you know the the other systems that are being invoked from a technical perspective, there's no specific reason that the application or the user layer would know about those servers. In theory, for example, like the first client application, or the first MCP server you see there is kind of a black box, it makes the decisions about if it wants to go invoke other sub agents or other services. And I think that's just how, like the internet layer like API's work today like you don't exactly know always. What's going on behind the hood. The protocol doesn't apply on how observability should work on enforcing that you need to know the interactions. That's really up to the builders and the ecosystem itself.
[01:04:30] that best practice on this for now, you don't even know like pulling a server that's created by somebody else. Yeah, you're right. I don't know exactly what that is. Based
[01:05:07] tell how can you debug.
[01:05:16] Q&A: MCP Server Debugging
Yes, the question is how do you actually make MCP servers debug both, especially if it's more than just a wrapper and an API and it's actually doing more complex things. The answer is that the protocol itself doesn't enforce like specific observability and interactions, it's kind of like incentive alignment for the server builder to expose useful data to the client. It does of course have ways for you to pass metadata between the client and the server. And so, if you build a good server that has good debugging and actually provides that data back to the client, you're more likely to be useful and actually like have a good UX. But the protocol itself doesn't kind of enforce that if that's kind of where you're asking, which I think is the same answer for API is like people will use your API if it's ergonomic and it's good and it makes sense and provide that. So we think servers should do that. I think we do have best practices. I don't know off the top of my head, but I can follow up with that.
[01:06:46] Yeah, I think the answer is, we will get there like other anthropic or MCP builders themselves or the community will start to converge on best practices but I agree with you that there needs to be best practices on how to debug and stuff.
[01:07:17] And I think there are patterns that are analogous to what we're doing here. It's just like when we're bringing in, hey, we also want this service to now increase. That's exactly right. Yeah, just comment on like, this is very similar to microservices, except this time we're bringing in intelligence, but there are patterns that exist that we should be drawing from. Yeah.
[01:07:44] Yeah.
[01:07:52] Yeah, I think the answer is, if the client wants to do like web search, and the server, and the alarm says, yeah, maybe you turn the other, okay, go to Google and web search and you want to limit the number of expect that to happen in natural language or by front of the server?
[01:08:15] Q&A: Client Control over Servers
Yeah, the question is, let's say that the client wants some amount of control or influence over the server itself or the tool call. Like, Yeah, the question is, let's say that the client wants some amount of control or influence over the server itself or the tool call.
[01:08:28] So, yeah, one suggestion is by doing that via the prompt like that's an obvious one that you can do. One thing we're thinking about is something called like tool annotations. These extra parameters or metadata that you can surface. In addition to the regular tool call or specifying the tool name to influence something like, can you limit the number of tools or limit equals five. That's something that the server builder and the tool builder inside that server would have to expose to be invoked by the client, but we're thinking about, at least in the protocol is standard. A couple of standard fields that could could help with this so one example that comes to mind is maybe the server builder exposes a tool annotation that's read versus right, and so the client actually can now know is this tool going to take action or is it only just like read only. And I think the opposite vice versa of that is what you're talking about. Where is there a way for the server to expose more parameters for how to control its behavior. Yeah. Hold on.
[01:09:30] Realistically get local traces. Has tool to help diagnose.
[01:09:41] Q&A: MCP DevEx Tools
Yeah, so question on like on dev x and how to actually, you know, look at the logs and actually respond to them so one. Shout out. One of the ways we have something called inspector in our repo and inspector lets you go look at logs and actually make sure that the connections to servers are making sense of definitely check that out. I think your question is, could you build a server that debug servers. Pretty sure that exists, and I've seen it where it goes and looks at the standard IO logs and goes and make changes to make that work. I've seen servers that go and set up the desktop config to make this work so yeah the answer is definitely you can have loops here. I'll take the last one, and then I'll come back to these at the end. Yeah, the question is around governance and security and who makes the decisions about what a client gets access to. I think a lot of that should be controlled by the server builder. We're going to talk about off very shortly but that's a really big part of it like there should be a default way in the protocol to there is there is a default way in the protocol to do authorization authentication. And that should be a control layer to the end application that the server is connecting to. And, yeah, I think that's the design principle is like, you could have not malicious clients but clients that want to ask you for all the information and it's the server builders responsibility to control that flow. I'm going to keep going and then I'll make sure to get back to questions in just a second. So I think we basically have covered this but the combination of sampling and composability. I think it's really exciting for a world with agents, specifically where if I'm an end user talking to my application. And chat bot. I can just go talk to that, and it's a orchestrator agent that orchestrator agent is a server, and I can reach out to it from my cloud for desktop, but it's also an MCP client, and it goes and talks to an analysis agent that's an MCP server, a coding agent, another server and a research agent as well. And the, this is composability and sampling comes in where I am talking to Claude from Claude for desktop. And the each of these agents and servers here are federated. So I'm operating those sampling requests through the layers to get back to my application which actually controls the interaction with Claude. So you get these really nice heart. Well, they will exist they don't exist yet but you will get these really nice hierarchical systems of agents, and sometimes these agents are going to live, you know, on the public web or they won't be built by you, but you'll have this way to connect with them, while still getting the privacy and security and control that you actually want when you're building these systems. So in a second we're about to talk about what's next and registry and discovery. But this is kind of the vision that I personally really want to see and I think we're going to get there, of this like connectivity layer, while they're still being guarantees about who has control over the specific interactions in each of these. I'll get to questions in a second. I'm just gonna keep going. So, we've talked about a few things we've talked about how people are using MCP today. We've talked about how it fits in with agents. There's a lot of really exciting things that a lot of you have already asked about that are on the roadmap and coming very soon. So, one is remote servers and off. So, let me pause this to say what's going on so first. This is inspector. This is the application I was just talking about where it lets you, you know, install a server and then see all the kinds of various interactions inspector already actually has support. So we added off to the protocol. So we added off to the protocol. A few weeks ago, we then added to inspector, it's about to land in all the SDK is, so you should go and check for that as soon as it's available but basically what we're doing here is we provide a URL to an MCP server for slack. This is happening over SSC, which, as opposed to standard IO SSC is the best way to do remote servers. And so I just give it the link, which is on the left side of the screen there and then I hit connect.
[01:14:20] MCP Roadmap: Remote Servers and Auth
And what happens now is that the server is orchestrating the handoff between. The server and slack, it's doing the actual authentication flow. And the way it's doing that is the protocol now supports off 2.0, and the server deals with the handshake, where it's going out to the slack server getting a callback URL, giving it to the client. The client opens that in Chrome, the user goes through the flow and clicks Yeah, this sounds good allow. And then the server holds the actual OAuth token itself. And then the server. The server federates the interactions between the user and the slack application by giving the client a session token for all future interactions. So the highlight here and I think this is the number one thing we've heard since day one of launch is this will enable remotely hosted servers. This means servers that live on a public URL, and can be discoverable by people through mechanisms I'll talk about in a sec. But you don't have to mess with standard IO. You can have the server fully control those interactions. Those requests, and they're all happening remotely. The agent and the LLM can live on a completely different system than wherever the server is running. Maybe the server is an agent. If you bring in that composability piece we just talked about. But this, I think, is going to be a big like explosion in the number of servers that you see, because it removes the DevEx friction. It removes the fact that you as a user even need to know what MCP is. You don't even need to know how to host it or how to build it. It's just there. It exists like a website exists, and you just go visit that website. any questions on remote server, actually, because I know a lot of people are interested in this. You're using the protocol. Are you also controlling the scope? People do an adaptation of it. So I like to increase the level of access that they have sometimes. So is there textual elements here to control? Yeah, I think the question is, does our support of OAuth also allow for? It sounds like scope change or like again, starting off with basic permissions. But allowing people to request elevated permissions, and for those to respect it through the survey protocol. Yeah, like elevating from basic to advanced permissions. I think in the first version of it does not support it out of the box. But we are definitely interested in evolving our support for off.
[01:16:48] Q&A: OAuth, Token Handling, and More
the question is, isn't it a bad thing that the server holds the actual token? I think. If you think about the design principle of the server being the one that actually is closest to the end application of slack or wherever you want the data to exist like let's say slack itself builds a public mcp server and decide decides the way that people should opt into it. I think slack will want to control the actual interaction between that server and the slack application. And then the the way that I think the fundamental reason for this is. Clients and servers don't know anything about each other before they start interacting. And so, giving the server more control over how the interaction with the final application exists. I think, is what allows there to be a separation. Does that kind of make sense.
[01:18:06] Yes, you should be judicious about what servers you connect to I think that's true for all web apps today as well.
[01:18:25] For what servers they have access to bs trust of servers is going to be increasingly important. Which we'll talk about with the registry in just a second.
[01:18:59] Yeah, the question is how does this fit in with restful api's and does it interact, I think, mtp is particularly good when there's a data transformations or some kind of logic that you want to have on top of just the interaction over rest. Maybe that means there are certain things that are better for lms than they would be for just a regular old client application that's talking to a server. Maybe that's the way that the data is formatted. Maybe that's the amount of context you give back to the model. You get a request, you get something back from a server and you say, hey Claude like these are the five things you need to pay attention to. This is how you handle this interaction after this, the servers, controlling all that logic and servicing your restful is going to still exist forever and that's going to be more for those stateless interactions we're just going back and forth you just want the data itself.
[01:20:08] The question is how do we think about regressions. As servers change as tool description change. How do we do evals.
[01:20:31] So a couple of things. One is we're going to talk about the registry in just a sec but I was probably something we talked about with versioning, where you can pin a registry and as it changes you should test that new behavior. I think that this doesn't change too much about the evals evals ecosystem around tools. You might imagine like a lot of the customers that we work with we help them go and build these frameworks around how their agent talks to them. And that's, you know, what's the right way what when should you be triggering a tool call, how do you handle the response. These are pre existing evals that exist or should exist. I think MCP makes it easier for people to build these systems around to close but that doesn't change anything about how robust these evals need to be. But it does make it easier right because you could at least the way I think about it is like I have my MCP server 1.0. My builder my developer publishes 1.1. And then I just run 1.1 against the exact same evals framework and provides this really nice like diff, I guess. Yeah, I don't think it changes too much about the needs of building evals themselves. Just the ergonomics.
[01:21:41] It's in the draft spec, it's in, there's an open PR in the SDKs, so it's like, I would say days away. Yeah, it is an inspector though it's fully implemented in there. So check it out. Cool. I want to go to registry because a lot of questions about registry. So, a huge huge thing that we've seen over the past two months is, there's no centralized way to discover and pull in MCP servers, you've probably seen that the servers repo that we launched. It's kind of a mess. There, there are like a bunch that we launched there a bunch that our partners launched, and then like 1000 that the community launch and then a whole bunch of different ecosystems have spun up around this, which is pretty fragmented and part of the reason is like, you know, we're not we didn't think it would grow this fast meant that we weren't quite ready to do that but what we are working on is an official MCP registry API. This is a unified and hosted metadata service, owned by the MCP team itself but built in the open. That means the schemas in the open the actual development of this is completely in the open, but it lives on an API that we're owning just for the sake of there being something posted. And what it allows you to do is have this layer. And what it allows you to do is have this layer. And what it allows you to do is have this layer. Above the various package systems that already exists where MCP servers already exist and are deployed. These are things like NPM Pi Pi. We started to see other ones develop as well around Java and Rust and go, but the point is, a lot of the problems that we've been talking today, talking about today like, you know, how do you discover what the protocol for an MCP server is it standard I oh, is it SSC. Does it live locally on a file that I need to go and build and install or doesn't live at a URL. Who built it? Are they trusted? Was this verified by, you know, if Shopify has an official MCP server, did Shopify bless this server? And so a lot of these problems I think are going to be solved with a registry, and we're going to work to make it as easy as possible for folks to port over the entire ecosystem that already exists for MCP servers. But the point is, this is coming. It's going to be great. And we're very excited about it because I think a huge problem right now is discoverability, and people don't know how to find MCP servers and people don't know how to publish them and where to put them. So we're very, very excited about this. And the last thing I'll touch on is versioning, which a lot of people are asking about. But you can imagine that this has its own versioning where there's this log of, hey, what's changed between this and this? Like maybe the APIs themselves didn't change, but I added a new tool or I added a new resource or I change the description of the tool. And so this is going to be a really nice way to version the entire ecosystem. And then the last thing is, we're going to put a lot of emphasis on DevEx and documentation. And so this is going to be a place to go and find the right ways to build the servers, the right ways to build the clients, the right ways to implement off, the right ways to do all of these things. And so we're going to make this as easy as possible. So that's kind of the roadmap. I'm going to pause there and take the rest of the questions. Yeah, I think this is a really good question. So the question is, how do you think about security? And how does this relate to the registry? I think the registry should have a few different things. So one is, there should be a way to have official integrations. So if you're talking to a Stripe server, Stripe should be able to say, this is the official Stripe server. And so you know that the thing that you're talking to is actually the Stripe server. Another thing is, you can have a server that's built by a third party, and that's totally fine. But there should be a way for the registry to have a verification process. Maybe it's like a check mark, or maybe it's a way for people to vote or to say, hey, this is a good server, or this is a bad server, and there should be a way for the community to kind of surface that to the top. And then, as we talked about with off, the server itself should control the actual access to the end application. So even if you connect to a server that is malicious, it shouldn't be able to just go and have access to all of your data, the server should be the one that's controlling the actual end interaction with that application. And so there's a few different ways to think about it. But I think the registry is going to be a big part of that. Yeah, yeah, I'll take a couple more.
[01:25:34] Q&A: Registry Security and More
Yeah, the question is, how do we think about the long tail of servers? I think there are a few different ways that people can build servers. One is, you can build them locally, and you can just have them on your local machine. And that's totally fine. You don't need to publish that anywhere. You can have a server that's published on the registry, and you can say, this is an unverified server, and that's totally fine. You're just putting it out there for people to use, and you're saying, hey, I built this, it's not verified, use it at your own risk. And then there are verified servers, which are the ones that are owned by the actual company itself, or they've gone through some kind of verification process. And so there's a few different ways, but I think the registry should support all of them. Yeah, yeah.
[01:26:11] Yeah, I think it's a good question. So the question is, how do we think about the difference between a server that's a wrapper around an API versus a server that's doing something more complex? I think the registry should have a way for people to specify that. So maybe there's a field that says, this is a wrapper server, or this is a complex server, or this is a server that's doing something more than just wrapping an API. And then, there should be a way for people to filter by that. So if you only want to see servers that are wrappers, you can filter by that. And if you only want to see servers that are doing something more complex, you can filter by that. Yeah, yeah, I'll take one more, and then I'll wrap it up.
[01:26:47] Yeah, I think the question is, how do we think about the difference between a server that's built by a company versus a server that's built by a third party? I think the registry should have a way for people to specify that. So maybe there's a field that says, this is a company-built server, or this is a third-party-built server. And then, there should be a way for people to filter by that. So if you only want to see servers that are built by companies, you can filter by that. And if you only want to see servers that are built by third parties, you can filter by that. Yeah, yeah, I'll wrap it up there. Thank you all for coming.
Alex Albert did say “I wouldn't be surprised if MCP turns out to be one of the biggest things to happen to LLM app development in 2025” on Feb 7, but then again there’s a difference between a conditional “wouldn’t be surprised if” and “has basically definitely become” on today, March 10, which reflects the shift in sentiment.
Despite some unfortunate technical difficulties reducing the recording quality, which are entirely my fault for underestimating the task of coordinating this many workshops on a small volunteer staff.
Including one I was personally involved in but didn’t, if I’m being fully honest with myself, believe in.
People often argue, for example, that MCP can do two way communication with SSE, for example enabling Sampling, however this misses the fact that most servers don’t implement this today and two way communication is barely used, so this is more people clutching at straws than actually looking at what made MCP successful.

Kubernetes beat Mesos and Docker Swarm in the Container Orchestration Wars and I will give you one guess on why. One can, of course, have a standard spawn at a BigCorp, and then subsequently have it migrate to a startup once it has achieved escape velocity, as happened to React.
This is also NOT a deterministic nor commutative relationship, many standard launches by BigCorp fail, and some smol-origin standards do succeed (OpenTracing/LightStep, Prometheus/SoundCloud?).
I emphasize the quote marks in “open standard”, because Anthropic says “The future of MCP is truly going to be community-led and not controlled by any single entity”, while I’m pretty sure the GitHub org and the commit rights are 90% Anthropic. It is important to stress that this isn’t criticism of Anthropic, because this doesn’t really hurt MCP adoption at all at this early stage of life.
