


Generative AI faces a critical challenge in balancing autonomy and controllability. While autonomy has advanced significantly through powerful generative models, controllability has become a focal point for machine learning researchers. Text-based control has become particularly important as natural language offers an intuitive interface between humans and machines. This approach has enabled remarkable applications across image editing, audio synthesis, and video generation. Recent text-to-data generative models, particularly those employing diffusion techniques, have shown impressive results by utilizing semantic insights from extensive data-text pair datasets. However, significant barriers arise in low-resource situations where obtaining sufficient text-paired data becomes prohibitively expensive or complicated due to complex data structures. Critical domains like molecular data, motion capture, and time series often lack adequate text labels, which restricts supervised learning capabilities and impedes the deployment of advanced generative models. These limitations predictably result in poor generation quality, model overfitting, bias, and limited output diversity—revealing a substantial gap in optimizing text representations for better alignment in data-limited contexts.
The low-resource scenario has prompted several mitigation approaches, each with inherent limitations. Data augmentation techniques often fail to accurately align synthetic data with original text descriptions and risk overfitting while increasing computational demands in diffusion models. Semi-supervised learning struggles with the inherent ambiguities in textual data, making correct interpretation challenging when processing unlabeled samples. Transfer learning, while promising for limited datasets, frequently suffers from catastrophic forgetting, where the model loses previously acquired knowledge as it adapts to new text descriptions. These methodological shortcomings highlight the need for more robust approaches specifically designed for text-to-data generation in low-resource environments.
In this paper, researchers from Salesforce AI Research present Text2Data which introduces a diffusion-based framework that enhances text-to-data controllability in low-resource scenarios through a two-stage approach. First, it masters data distribution using unlabeled data via an unsupervised diffusion model, avoiding the semantic ambiguity common in semi-supervised methods. Second, it implements controllable fine-tuning on text-labeled data without expanding the training dataset. Instead, Text2Data employs a constraint optimization-based learning objective that prevents catastrophic forgetting by keeping model parameters close to their pre-fine-tuning state. This unique framework effectively utilizes both labeled and unlabeled data to maintain fine-grained data distribution while achieving superior controllability. Theoretical validation supports the optimization constraint selection and generalization bounds, with comprehensive experiments across three modalities demonstrating Text2Data’s superior generation quality and controllability compared to baseline methods.
Text2Data addresses controllable data generation by learning the conditional distribution pθ(x|c) where limited paired data creates optimization challenges. The framework operates in two distinct phases as illustrated in the figure below. Initially, it utilizes more abundant unlabeled data to learn the marginal distribution pθ(x), obtaining optimal parameters θ̂ within set Θ. This approach exploits the mathematical relationship between marginal and conditional distributions, where pθ(x) approximates the expected value of pθ(x|c) over the text distribution. Subsequently, Text2Data fine-tunes these parameters using the available labeled data-text pairs while implementing constraint optimization to keep the updated parameters θ̂’ within the intersection of Θ and Θ’. This constraint ensures the model maintains knowledge of the overall data distribution while gaining text controllability, effectively preventing catastrophic forgetting that typically occurs during fine-tuning processes.
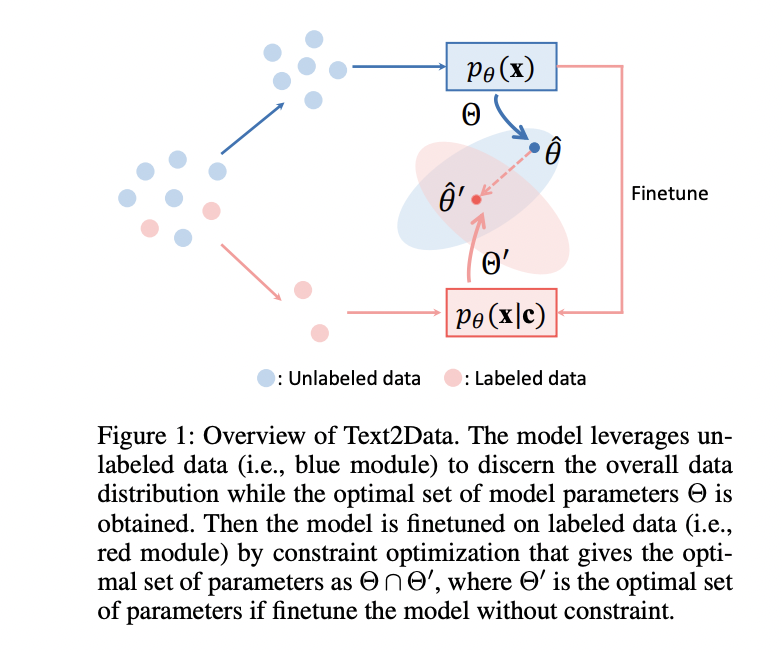
Text2Data implements its two-phase approach by first using all available data with NULL tokens as conditions to learn the general data distribution. This allows the model to optimize pθ(x|∅), which effectively equals pθ(x) since the NULL token is independent of x. The second phase introduces a constraint optimization framework that fine-tunes the model on text-labeled data while preventing parameter drift from the previously learned distribution. Mathematically, this is expressed as minimizing the negative log-likelihood of conditional probability pθ(x|c) subject to the constraint that the marginal distribution performance remains close to the optimal value ξ established during the first phase. This constraint-based approach directly addresses catastrophic forgetting by ensuring the model parameters remain within an optimal set where both general data representation and text-specific controllability can coexist—essentially solving a lexicographic optimization problem that balances these competing objectives.
It implements classifier-free diffusion guidance by transforming the theoretical objective into practical loss functions. The framework optimizes three key components: L1(θ) for general data distribution learning, L’1(θ) for distribution preservation on labeled data, and L2(θ) for text-conditioned generation. These are empirically estimated using available data samples. The lexicographic optimization process, detailed in Algorithm 1, balances these objectives by dynamically adjusting gradient updates with a parameter λ that enforces constraints while allowing effective learning. This approach uses a sophisticated update rule where θ is modified based on a weighted combination of gradients from both objectives. The constraint can be relaxed during training to improve convergence, recognizing that parameters need not be an exact subset of the original parameter space but should remain proximal to preserve distribution knowledge while gaining controllability.

Text2Data provides theoretical underpinnings for its constraint optimization approach through generalization bounds that validate parameter selection. The framework establishes that random variables derived from the diffusion process are sub-Gaussian, enabling the formulation of rigorous confidence bounds. Theorem 0.2 delivers three critical guarantees: first, the empirical parameter set within the confidence bound fully encompasses the true optimal set; second, the empirical solution competes effectively with the theoretical optimum on the primary objective; and third, the empirical solution maintains reasonable adherence to the theoretical constraint. The practical implementation introduces a relaxation parameter ρ that adjusts the strictness of the constraint while keeping it within the mathematically justified confidence interval. This relaxation acknowledges real-world conditions where obtaining numerous unlabeled samples is feasible, making the confidence bound reasonably tight even when handling models with millions of parameters. Experiments with motion generation involving 45,000 samples and 14 million parameters confirm the framework’s practical viability.

Text2Data demonstrates superior controllability across multiple domains compared to baseline methods. In molecular generation, it achieves lower Mean Absolute Error (MAE) for all properties compared to EDM-finetune and EDM, particularly excelling with properties like ϵLUMO and Cv. For motion generation, Text2Data surpasses MDM-finetune and MDM in R Precision and Multimodal Distance metrics. In time series generation, it consistently outperforms DiffTS-finetune and DiffTS across all evaluated properties. Beyond controllability, Text2Data maintains exceptional generation quality, showing improvements in molecular validity, stability, motion generation diversity, and distribution alignment in time series. These results validate Text2Data’s effectiveness in mitigating catastrophic forgetting while preserving generation quality.

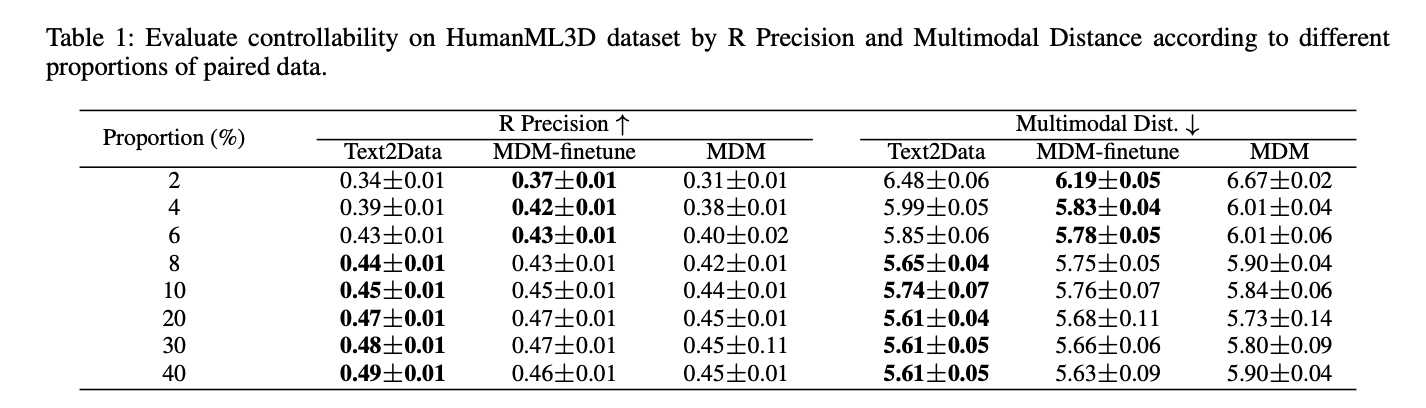
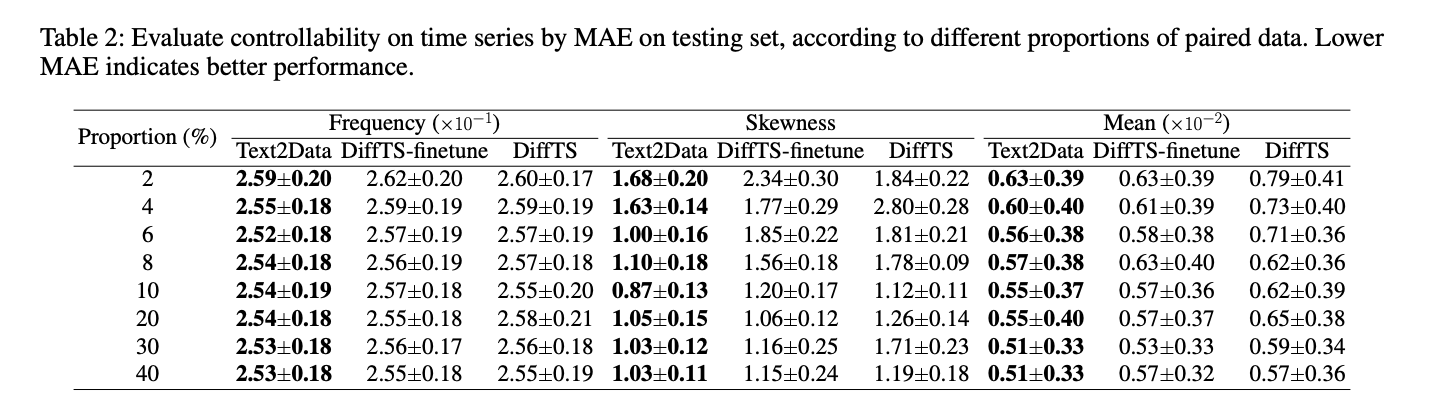
Text2Data effectively addresses the challenges of text-to-data generation in low-resource scenarios across multiple modalities. By initially utilizing unlabeled data to grasp the overall data distribution and then implementing constraint optimization during fine-tuning on labeled data, the framework successfully balances controllability with distribution preservation. This approach prevents catastrophic forgetting while maintaining generation quality. Experimental results consistently demonstrate Text2Data’s superiority over baseline methods in both controllability and generation quality. Though implemented with diffusion models, Text2Data’s principles can be readily adapted to other generative architectures.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post Salesforce AI Releases Text2Data: A Training Framework for Low-Resource Data Generation appeared first on MarkTechPost.
