


Personalizing LLMs is essential for applications such as virtual assistants and content recommendations, ensuring responses align with individual user preferences. Unlike traditional approaches that optimize models based on aggregated user feedback, personalization aims to capture the diversity of individual perspectives shaped by culture, experiences, and values. Current optimization methods, such as reinforcement learning from human feedback (RLHF), focus on a singular reward model, potentially overlooking minority viewpoints and introducing biases. A more effective approach would involve learning a distribution of reward functions rather than a single one, enabling LLMs to generate responses tailored to different user groups. This shift improves user satisfaction and fosters inclusivity by acknowledging diverse perspectives. However, implementing this effectively in open-ended question-answering and real-world applications remains challenging.
Research on preference learning has explored multiple strategies for personalization. Some methods, like distributional alignment, aim to match model outputs to broad statistical properties but lack direct adaptation to individual users. Others attempt to model reward distributions explicitly, yet they face challenges in sample efficiency and real-world evaluations. Many existing approaches, such as GPO and human-correction-based methods, work well in structured tasks but have not been thoroughly tested for open-ended personalization. Supervised fine-tuning, reinforcement learning techniques like PPO, and alternative methods like DPO and IPO have been explored for refining LLM outputs based on user preferences. FSPO, a black-box meta-learning approach, adapts to new user preferences with minimal examples, leveraging techniques from prior studies in language modeling, reinforcement learning, and meta-learning.
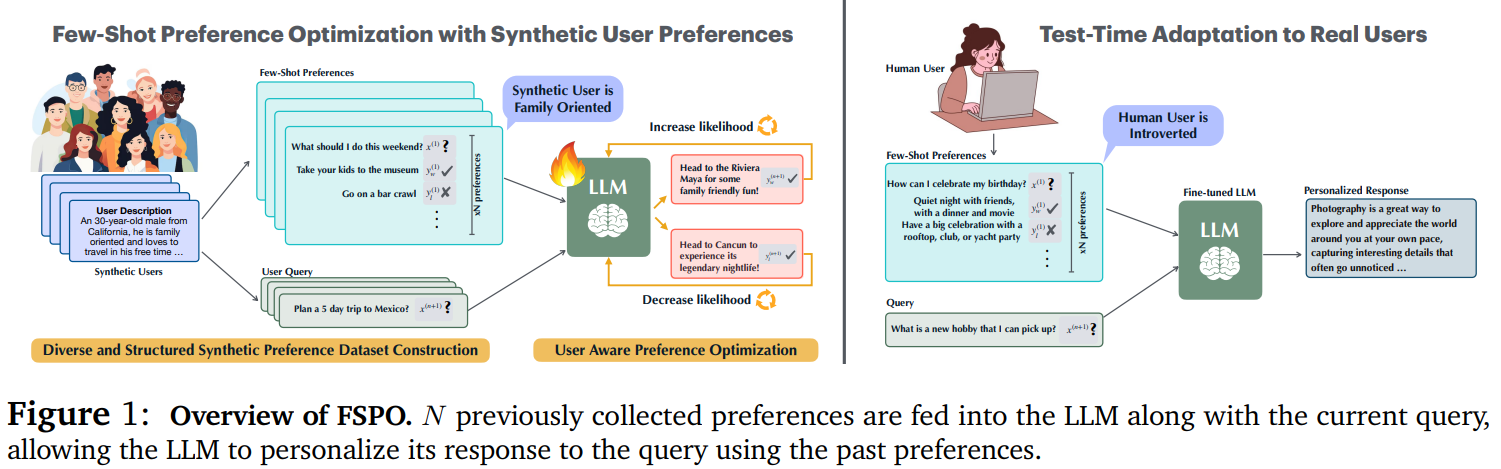
Researchers from Stanford University, Google DeepMind, and OpenAI propose Few-Shot Preference Optimization (FSPO), a framework that personalizes language models by adapting to user preferences with minimal labeled examples. Instead of relying on aggregated human feedback, FSPO reframes reward modeling as a meta-learning problem, enabling models to construct personalized reward functions. The approach generates over a million structured synthetic preferences to address data scarcity. Evaluated across three domains—reviews, educational adaptation, and roleplay—FSPO achieves an 87% win rate in synthetic user personalization and 72% with real users, enhancing LLMs’ ability to align with diverse user needs in open-ended interactions.
The FSPO framework treats personalization as a meta-learning problem. Traditional fine-tuning with RLHF aggregates user preferences across a population, often marginalizing individual differences. FSPO addresses this by associating preferences with user-specific identifiers and modeling each user as a task instance. Using a black-box meta-learning approach, it quickly adapts to new users with minimal data. FSPO constructs few-shot prompts to leverage pre-trained LLMs for effective personalization. Additionally, user representation is framed as an (N)-bit preference encoding, allowing structured generalization. FSPO is evaluated across three domains: reviews, educational explanations, and roleplay-based question answering.
FSPO is evaluated against four baselines: (1) a generic instruct model, (2) few-shot prompting, (3) few-shot fine-tuning (Pref-FT), and (4) prompting with an oracle user description. FSPO consistently outperforms these baselines across various tasks. Synthetic win rates, assessed via a modified AlpacaEval, show FSPO excelling in ELIX, Review, and Roleplay tasks, achieving an 82.6% win rate on real users. A human study with 25 participants confirms FSPO’s effectiveness, with a 72% win rate over both the base and SFT models. FSPO demonstrates strong personalization, narrowing the gap to oracle performance through chain-of-thought reasoning.
In conclusion, FSPO is a framework for personalizing language models in open-ended question answering by modeling diverse human preferences through meta-learning. Unlike traditional reward modeling, FSPO rapidly adapts to individual users using a few labeled preferences. Over 1M synthetic personalized preferences are generated to address data scarcity, ensuring diversity and consistency for effective real-world transfer. Evaluated across three domains and 1,500 synthetic users, FSPO achieves an 87% AlpacaEval win rate and a 72% win rate with real users. This approach enhances personalization in virtual assistants and content curation applications, contributing to more inclusive and user-centric language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Few-Shot Preference Optimization (FSPO): A Novel Machine Learning Framework Designed to Model Diverse Sub-Populations in Preference Datasets to Elicit Personalization in Language Models for Open-Ended Question Answering appeared first on MarkTechPost.
