


Large Language Models (LLMs) are widely used in medicine, facilitating diagnostic decision-making, patient sorting, clinical reporting, and medical research workflows. Though they are exceedingly good in controlled medical testing, such as the United States Medical Licensing Examination (USMLE), their utility for real-world uses is still not well-tested. Most existing evaluations rely on synthetic benchmarks that fail to reflect the complexities of clinical practice. In a study last year, they found that a mere 5% of LLM analysis relies on actual world patient information, which reveals an enormous difference between testing real-world usability and indicates a profound problem with ascertaining how reliably they function in medical decision-making, therefore also questioning safety and effectiveness for use in actual-world clinical settings.
State-of-the-art evaluation methods mostly score language models with synthetic datasets, structured knowledge exams, and formal medical exams. Although these examinations test theoretical knowledge, they don’t reflect real patient scenarios with complex interactions. Most tests produce single metric results, without attention to critical details such as correctness of facts, clinical applicability, and likelihood of response bias. Furthermore, widely used public datasets are homogenous, compromising the generalization across different medical specialties and populations of patients. Another major setback is that most models trained against these benchmarks exhibit overfitting to test paradigms and therefore lose much of their performance in dynamic healthcare environments. A lack of whole-system frameworks embracing real-world patient interactions erodes confidence even further in employing them for practical medical use.
Researchers developed MedHELM, a thorough evaluation framework designed to test LLMs against real medical tasks, multi-metric assessment, and expert-revised benchmarks to address these gaps. It builds upon Stanford’s Holistic Evaluation of Language Models (HELM) and incorporates a systematic evaluation across five primary areas:
- Clinical Decision SupportClinical Note GenerationPatient Communication and EducationMedical Research AssistanceAdministration and Workflow
A total of 22 subcategories and 121 specific medical tasks ensure broad coverage of critical healthcare applications. In comparison with earlier standards, MedHELM employs actual clinical data, assesses models both by structured and open-ended tasks, and applies multi-aspect scoring paradigms. The holistic coverage makes it better capable of not only measuring the recall of knowledge but also of clinical applicability, reasoning precision, and general everyday practical utility.
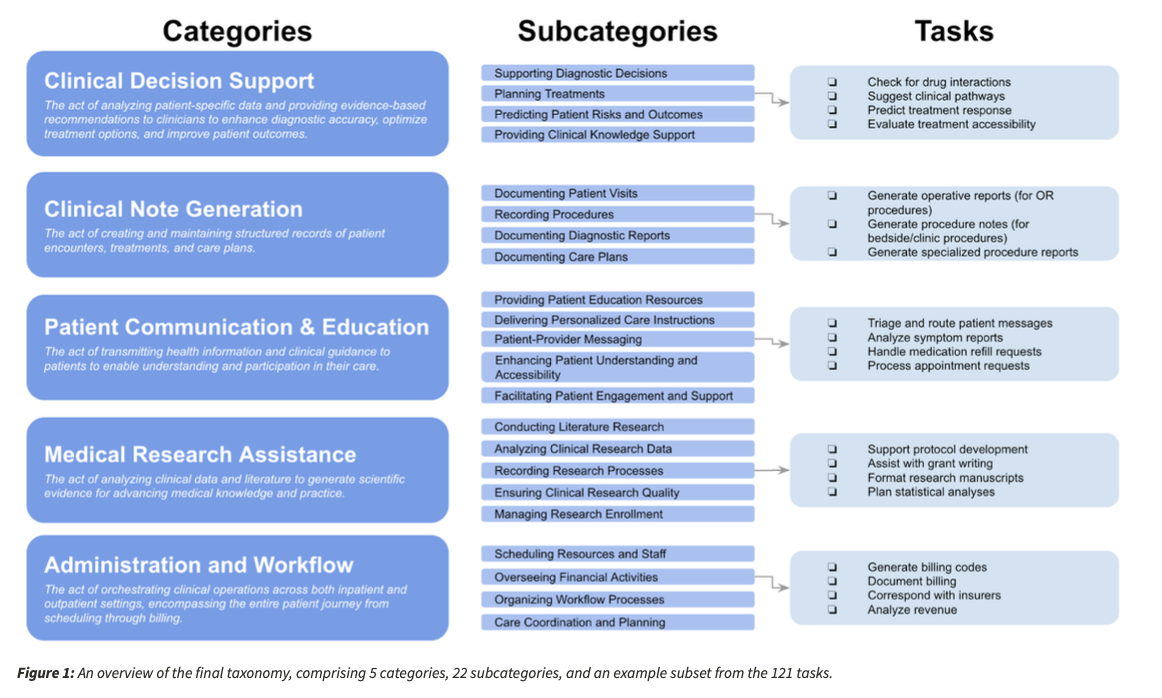
An extensive dataset infrastructure underpins the benchmarking process, comprising a total of 31 datasets. This collection includes 11 newly developed medical datasets alongside 20 that have been obtained from pre-existing clinical records. The datasets encompass various medical domains, thereby guaranteeing that assessments accurately represent real-world healthcare challenges rather than contrived testing scenarios.
The conversion of data sets into standardized references is a systematic process, which involves:
- Context Definition: The specific data segment the model must analyze (e.g., clinical notes).Prompting Strategy: A predefined instruction directing model behavior (e.g., “Determine the patient’s HAS-BLED score”).Reference Response: A clinically validated output for comparison (e.g., classification labels, numerical values, or text-based diagnoses).Scoring Metrics: A combination of exact match, classification accuracy, BLEU, ROUGE, and BERTScore for text similarity evaluations.
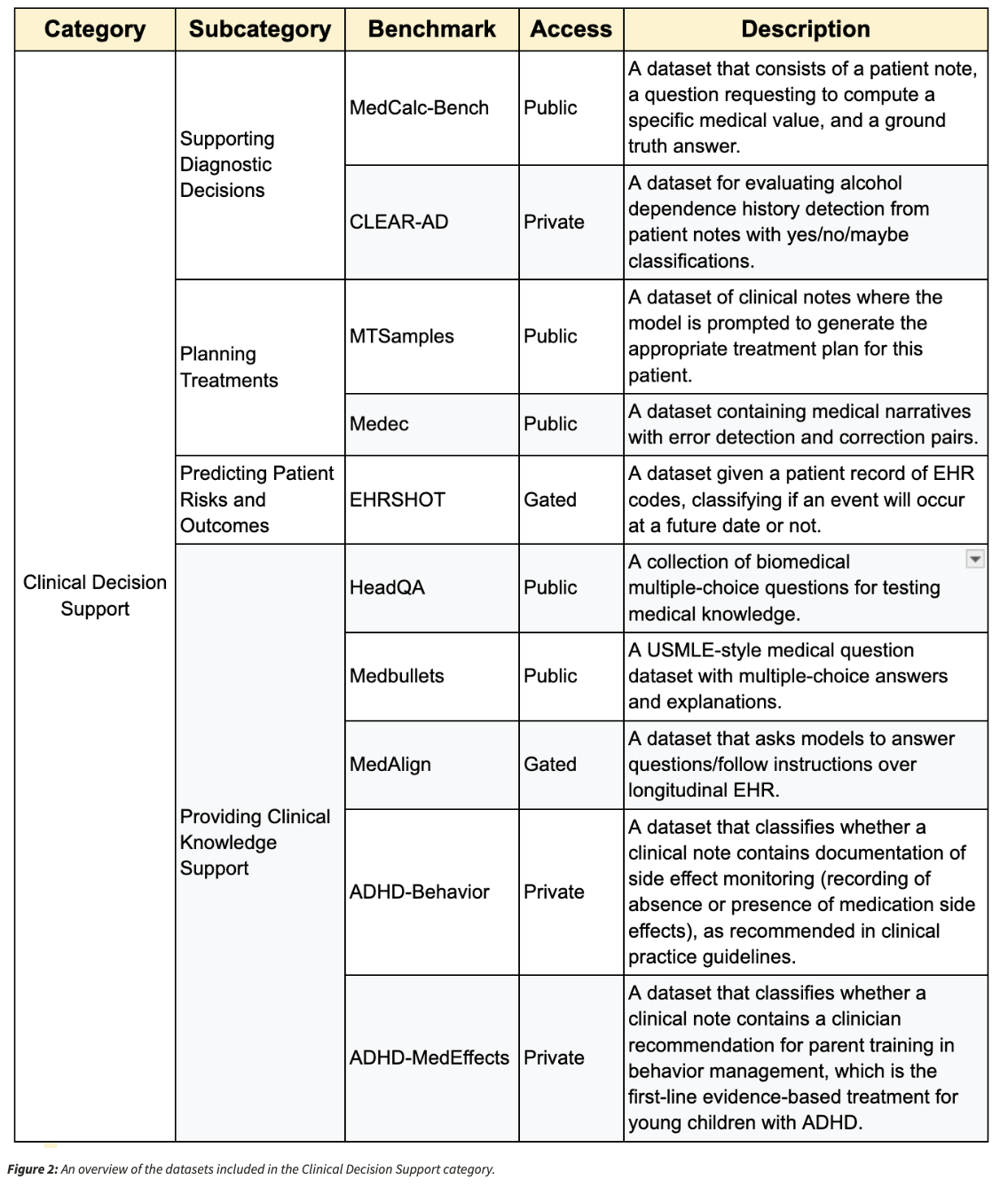
One example of this approach is in MedCalc-Bench, which tests how well a model can execute clinically significant numerical computations. Every data input contains a patient’s clinical history, a diagnostic question, and a solution verified by an expert, thus enabling a rigorous test of medical reasoning and precision.
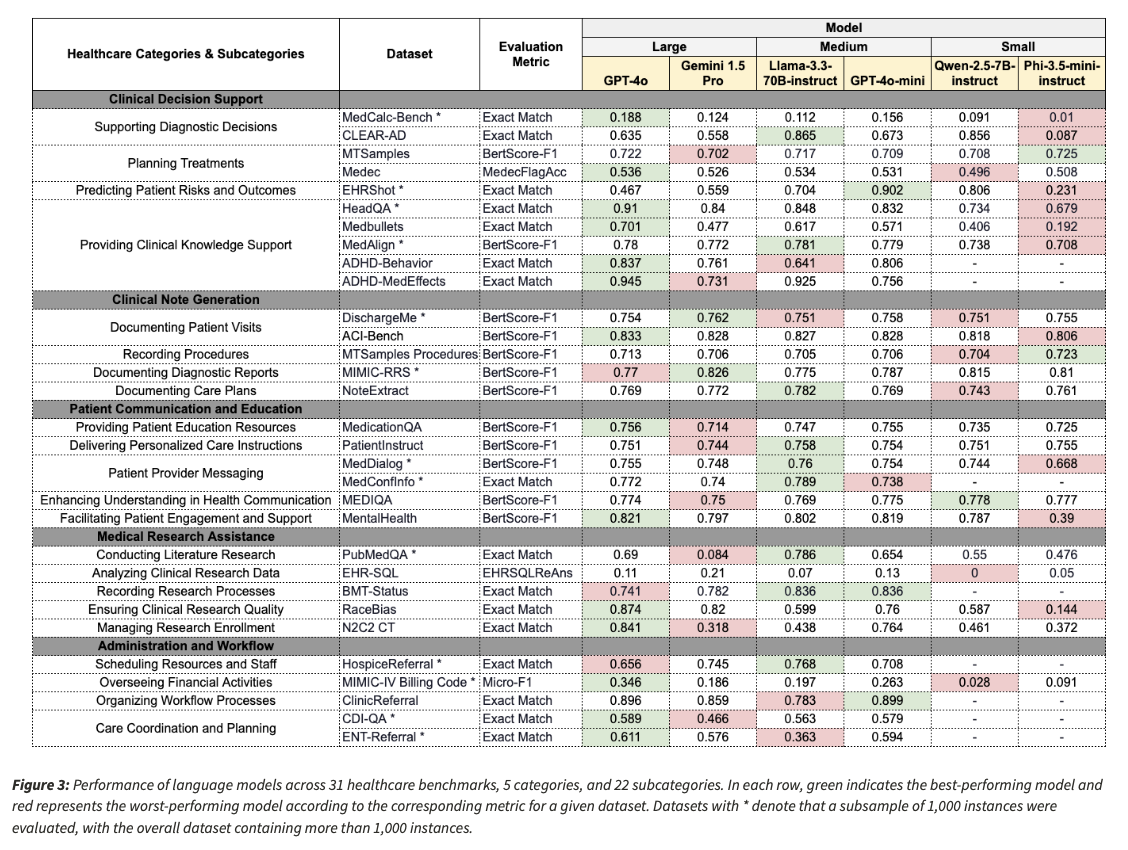
Assessments conducted on six LLMs of varying sizes revealed distinct strengths and weaknesses based on task complexity. Large models like GPT-4o and Gemini 1.5 Pro performed well in medical reasoning and computational tasks and showed enhanced accuracy in tasks like clinical risk estimation and bias identification. Mid-size models like Llama-3.3-70B-instruct performed competitively in predictive healthcare tasks like hospital readmission risk prediction. Small models like Phi-3.5-mini-instruct and Qwen-2.5-7B-instruct fared poorly in domain-intensive knowledge tests, especially in mental health counseling and advanced medical diagnosis.
Aside from accuracy, response adherence to structured questions was also varied. Some models would not answer medically sensitive questions or would not answer in the desired format, at the expense of their overall performance. The test also discovered shortcomings in current automated metrics as conventional NLP scoring mechanisms tended to ignore real clinical accuracy. In the majority of benchmarks, the performance disparity between models remained negligible when employing BERTScore-F1 as the metric, which indicates that current automated evaluation procedures might not fully capture clinical usability. The results emphasize the necessity of stricter evaluation procedures incorporating fact-based scoring and unambiguous clinician feedback to ensure more reliability in evaluation.
With the advent of a clinically guided, multi-metric assessment framework, MedHELM offers a holistic and trustworthy method of assessing language models in the healthcare domain. Its methodology guarantees that LLMs will be assessed on actual clinical tasks, organized reasoning tests, and varied datasets, instead of artificial tests or truncated benchmarks. Its main contributions are:
- A structured taxonomy of 121 real-world medical tasks, improving the scope of AI evaluation in clinical settings.The use of real patient data to enhance model assessments beyond theoretical knowledge testing.Rigorous evaluation of six state-of-the-art LLMs, identifying strengths and areas requiring improvement.A call for improved evaluation methodologies, emphasizing fact-based scoring, steerability adjustments, and direct clinician validation.
Subsequent research efforts will concentrate on the improvement of MedHELM by introducing more specialized datasets, streamlining evaluation processes, and implementing direct feedback from healthcare professionals. Overcoming significant limitations in artificial intelligence evaluation, this framework establishes a solid foundation for the secure, effective, and clinically relevant integration of large language models into contemporary healthcare systems.
Check out the Full Leaderboard, Details and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post MedHELM: A Comprehensive Healthcare Benchmark to Evaluate Language Models on Real-World Clinical Tasks Using Real Electronic Health Records appeared first on MarkTechPost.
