


The processing requirements of LLMs pose considerable challenges, particularly for real-time uses where fast response time is vital. Processing each question afresh is time-consuming and inefficient, necessitating huge resources. AI service providers overcome the low performance by using a cache system that stores repeated queries so that these can be answered instantly without waiting, optimizing efficiency while saving latency. While speeding up response time, however, security risks also arise. Scientists have studied how LLM API caching habits could unwittingly reveal confidential information. They found that user queries and trade-secret model information could leak through timing-based side-channel attacks based on commercial AI services’ caching policies.
One of the key risks of prompt caching is its potential to reveal information about previous user queries. If cached prompts are shared among multiple users, an attacker could determine whether someone else recently submitted a similar prompt based on response time differences. The risk becomes even greater with global caching, where one user’s prompt can lead to a faster response time for another user submitting a related query. By analyzing response time variations, researchers demonstrated how this vulnerability could allow attackers to uncover confidential business data, personal information, and proprietary queries.
Various AI service providers cache differently, but their caching policies are not necessarily transparent to users. Some restrict caching to single users so that cached prompts are available to only the individual who posted them, thus not allowing data to be shared among accounts. Others implement per-organization caching so that several users in a firm or organization can share cached prompts. While more efficient, this also risks leaking sensitive information if some users possess special access privileges. The most threatening security risk results from global caching, wherein all API services can access the cached prompts. As a result, an attacker can manipulate response time inconsistencies to determine previous prompts submitted. Researchers discovered that most AI providers are not transparent with their caching policies, so users remain ignorant of the security threats accompanying their queries.
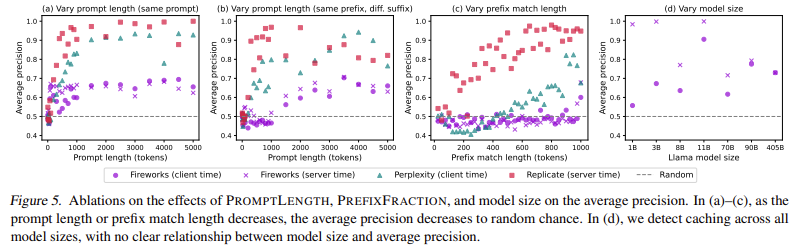
To investigate these issues, the research team from Stanford University developed an auditing framework capable of detecting prompt caching at different access levels. Their method involved sending controlled sequences of prompts to various AI APIs and measuring response time variations. If a prompt were cached, the response time would be noticeably faster when resubmitted. They formulated statistical hypothesis tests to confirm whether caching was occurring and to determine whether cache sharing extended beyond individual users. The researchers identified patterns indicating caching by systematically adjusting prompt lengths, prefix similarities, and repetition frequencies. The auditing process involved testing 17 commercial AI APIs, including those provided by OpenAI, Anthropic, DeepSeek, Fireworks AI, and others. Their tests focused on detecting whether caching was implemented and whether it was limited to a single user or shared across a broader group.
The auditing procedure consisted of two primary tests: one to measure response times for cache hits and another for cache misses. In the cache-hit test, the same prompt was submitted multiple times to observe if response speed improved after the first request. In the cache-miss test, randomly generated prompts were used to establish a baseline for uncached response times. The statistical analysis of these response times provided clear evidence of caching in several APIs. The researchers identified caching behavior in 8 out of 17 API providers. More critically, they discovered that 7 of these providers shared caches globally, meaning that any user could infer the usage patterns of another user based on response speed. Their findings also revealed a previously unknown architectural detail about OpenAI’s text-embedding-3-small model—prompt caching behavior indicated that it follows a decoder-only transformer structure, a piece of information that had not been publicly disclosed.
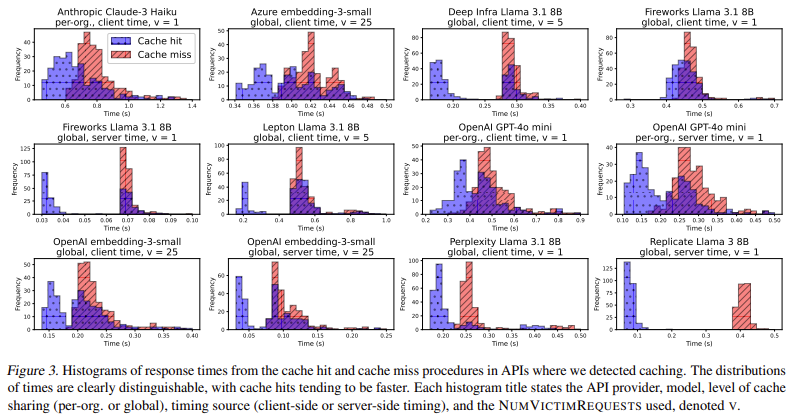
The performance evaluation of cached versus non-cached prompts highlighted striking differences in response times. For example, in OpenAI’s text-embedding-3-small API, the average response time for a cache hit was approximately 0.1 seconds, whereas cache misses resulted in delays of up to 0.5 seconds. The researchers determined that cache-sharing vulnerabilities could allow attackers to achieve near-perfect precision in distinguishing between cached and non-cached prompts. Their statistical tests produced highly significant p-values, often below 10⁻⁸, indicating a strong likelihood of caching behavior. Moreover, they found that in many cases, a single repeated request was sufficient to trigger caching, with OpenAI and Azure requiring up to 25 consecutive requests before caching behavior became apparent. These findings suggest that API providers might use distributed caching systems where prompts are not stored immediately across all servers but become cached after repeated use.
Key Takeaways from the Research include the following:
- Prompt caching speeds up responses by storing previously processed queries, but it can expose sensitive information when caches are shared across multiple users. Global caching was detected in 7 of 17 API providers, allowing attackers to infer prompts used by other users through timing variations. Some API providers do not publicly disclose caching policies, meaning users may be unaware that others are storing and accessing their inputs. The study identified response time discrepancies, with cache hits averaging 0.1 seconds and cache misses reaching 0.5 seconds, providing measurable proof of caching. The statistical audit framework detected caching with high precision, with p-values often falling below 10⁻⁸, confirming the presence of systematic caching across multiple providers. OpenAI’s text-embedding-3-small model was revealed to be a decoder-only transformer, a previously undisclosed detail inferred from caching behavior. Some API providers patched vulnerabilities after disclosure, but others have yet to address the issue, indicating a need for stricter industry standards. Mitigation strategies include restricting caching to individual users, randomizing response delays to prevent timing inference, and providing greater transparency on caching policies.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Stanford Researchers Uncover Prompt Caching Risks in AI APIs: Revealing Security Flaws and Data Vulnerabilities appeared first on MarkTechPost.
