


Large language models (LLMs) have progressed beyond basic natural language processing to tackle complex problem-solving tasks. While scaling model size, data, and compute has enabled the development of richer internal representations and emergent capabilities in larger models, significant challenges remain in their reasoning abilities. Current methodologies struggle to maintain coherence throughout complex problem-solving processes, particularly in domains requiring structured thinking. The difficulty lies in optimising the chain-of-thought reasoning and ensuring consistent performance across varied tasks, especially on challenging mathematical problems. Though recent advancements have shown promise, researchers face the ongoing challenge of effectively utilizing computational resources to improve reasoning capabilities without sacrificing efficiency. Developing methods that can systematically enhance problem-solving while maintaining scalability remains a central problem in advancing LLM capabilities.
Researchers have explored various approaches to enhance reasoning in LLMs. Test-time compute scaling coupled with reinforcement learning has emerged as a promising direction, with models using reasoning tokens to guide chain-of-thought processes. Studies have investigated whether models tend to overthink or underthink, examining reasoning step length, input length, and common failure modes. Previous work has focused on optimising mathematical reasoning through explicit chain-of-thought training during the learning phase and iterative refinement at inference time. While these approaches have shown improvements on benchmarks, questions remain about the efficiency of token usage across different model capabilities and the relationship between reasoning length and performance. These questions are crucial for understanding how to design more effective reasoning systems.
This study uses the Omni-MATH dataset to benchmark reasoning abilities across different model variants. This dataset provides a rigorous evaluation framework at the Olympiad level, addressing limitations of existing benchmarks like GSM8K and MATH where current LLMs achieve high accuracy rates. Omni-MATH’s comprehensive organization into 33 sub-domains across 10 difficulty levels enables nuanced assessment of mathematical reasoning capabilities. The availability of Omni-Judge facilitates automated evaluation of model-generated answers. While other benchmarks like MMLU, AI2 Reasoning, and GPQA cover diverse reasoning domains, and coding benchmarks highlight the importance of clear reward models, Omni-MATH’s structure makes it particularly suitable for analyzing the relationship between reasoning length and performance across model capabilities.
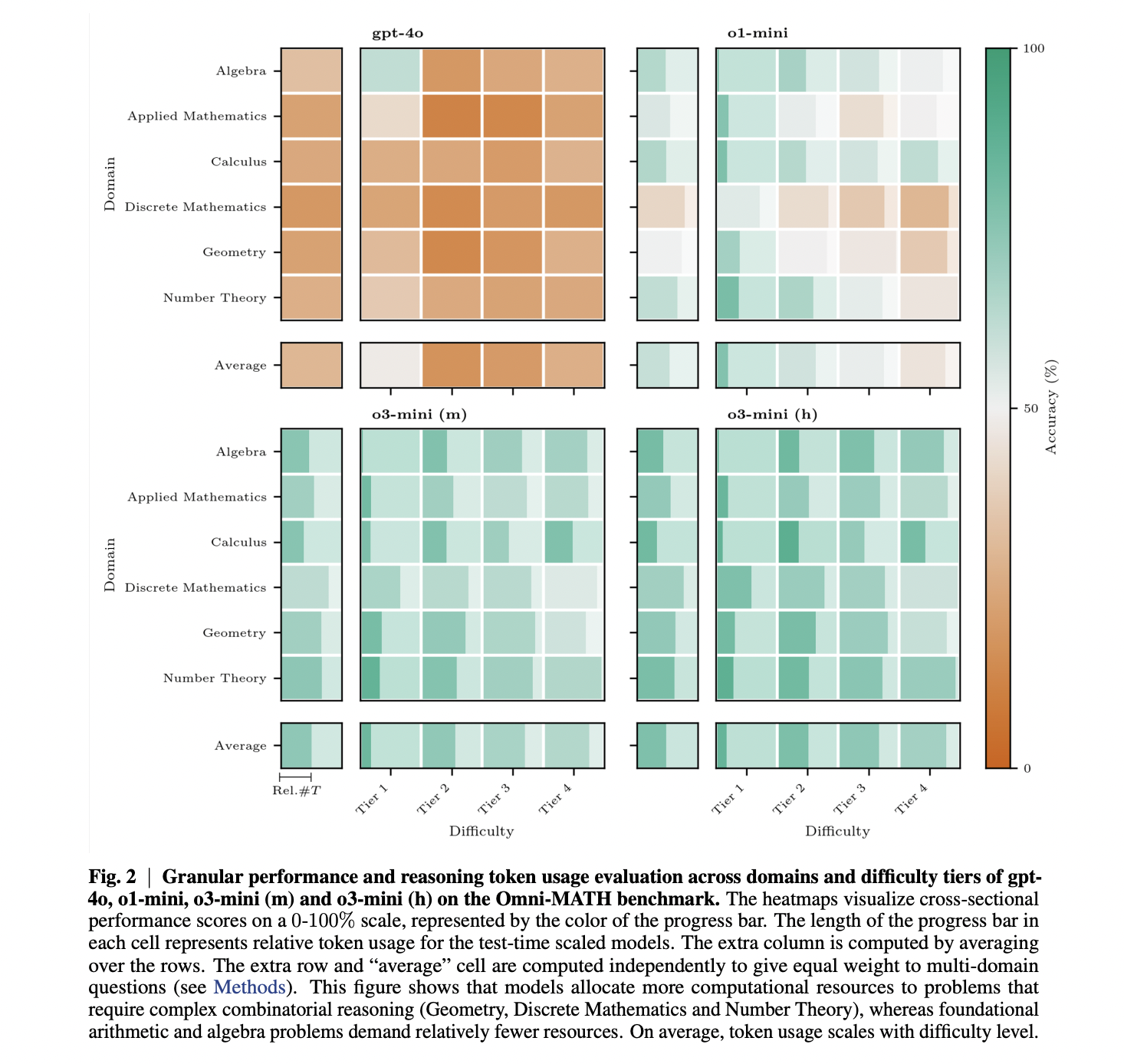
The study evaluated model performance using the Omni-MATH benchmark, which features 4,428 Olympiad-level math problems across six domains and four difficulty tiers. Results show a clear performance hierarchy among the tested models: gpt-4o achieved 20-30% accuracy across disciplines, significantly lagging behind the reasoning models; o1-mini reached 40-60%; o3-mini (m) achieved at least 50% in all categories; and o3-mini (h) improved by approximately 4% over o3-mini (m), exceeding 80% accuracy for Algebra and Calculus. Token usage analysis revealed that relative token consumption increases with problem difficulty across all models, with Discrete Mathematics being particularly token-intensive. Importantly, o3-mini (m) does not use more reasoning tokens than o1-mini to achieve superior performance, suggesting more effective reasoning. Also, accuracy decreases with increasing token usage across all models, with the effect being strongest for o1-mini (3.16% decrease per 1000 tokens) and weakest for o3-mini (h) (0.81% decrease). This indicates that while o3-mini (h) shows marginally better performance, it comes at a substantially higher computational cost.
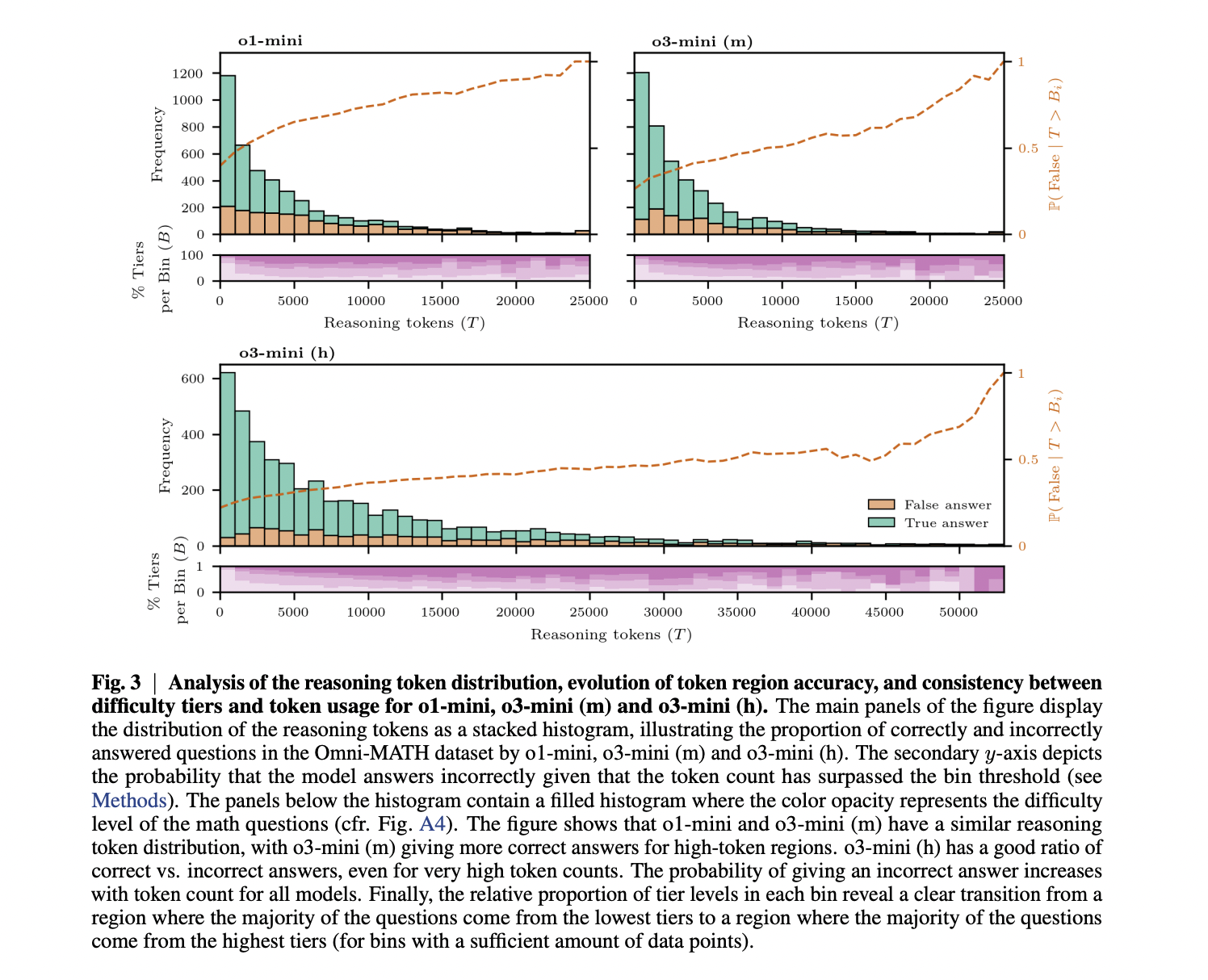
The research yields two significant findings regarding language model reasoning. First, more capable models do not necessarily require longer reasoning chains to achieve higher accuracy, as demonstrated by the comparison between o1-mini and o3-mini (m). Second, while accuracy generally declines with longer chain-of-thought processes, this effect diminishes in more advanced models, emphasizing that “thinking harder” differs from “thinking longer.” This accuracy drop may occur because models tend to reason more extensively on problems they struggle to solve, or because longer reasoning chains inherently increase the probability of errors. The findings have practical implications for model deployment, suggesting that constraining chain-of-thought length is more beneficial for weaker reasoning models than for stronger ones, as the latter maintain reasonable accuracy even with extended reasoning. Future work could benefit from mathematical benchmarks with reference reasoning templates to further explore these dynamics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Thinking Harder, Not Longer: Evaluating Reasoning Efficiency in Advanced Language Models appeared first on MarkTechPost.
