


Reinforcement learning (RL) has been a core component in training large language models (LLMs) to perform tasks that involve reasoning, particularly mathematical problem-solving. A considerable inefficiency occurs during training, including a situation where many questions are always answered or left unsolved. The lack of variability in success rates is to blame for inefficient learning results because questions that do not yield a gradient signal do not allow the model’s performance to be improved. Traditional RL-based fine-tuning strategies are susceptible to expensive computational costs, increased energy usage, and inefficient use of resources. Correcting this is necessary to improve training efficiency and make language models learn from problems that greatly improve their reasoning.
The standard training regimen of large language models (LLMs) uses policy gradient techniques, such as Proximal Policy Optimization (PPO), in which models engage with each query repeatedly and corrections are applied based on signs of success or failure. One of the greatest drawbacks of this approach, however, is that the majority of training examples belong to clusters of extremes—either always correct or always incorrect. When an example is always solved correctly, repeated attempts do not provide further learning information. On the contrary, an impossible query provides no feedback for improvement. As a result, precious computational resources are wasted on useless training scenarios. Different curriculum-learning techniques, such as Unsupervised Environment Design (UED), have attempted to dynamically control training difficulty. These techniques, however, rely on heuristics such as regret-based selection, which are largely insufficient in anticipating optimal problem difficulty and fail to generalize well to reasoning tasks relevant to LLM training.
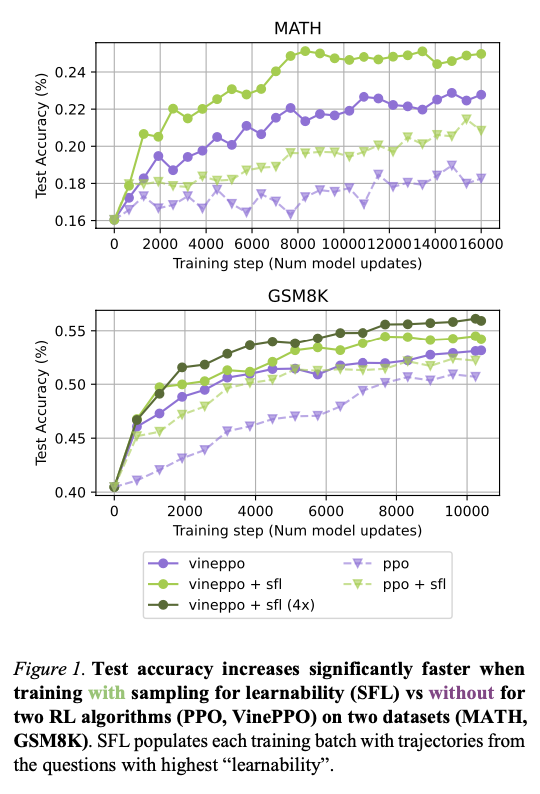
To address this inefficiency, a novel training policy has been suggested and proposed that focuses on samples with high variance of success rates, thus forcing models to focus on questions not too easy and not too difficult. By identifying and choosing issues where the model performs erratically, the approach concentrates training on scenarios that provide the most informative learning signals. Differing from previous policies that utilized random sampling to train batches, this systematic selection method enhances update efficiency by eliminating problems that do not allow significant improvement. The procedure adapts during training, continuously optimizing question selection to track the fluctuating strength of the model. By targeting instances of moderate difficulty, the approach enables better learning and better generalization to novel tasks.

The structured selection process operates through a multi-step pipeline that begins with the identification of candidate questions at each training iteration. Multiple rollouts are generated to assess the probability of success for each problem, and the variance of these success rates is computed using the function ? ( 1 − ? ), where ? represents the likelihood of a correct solution. The most learnable questions with moderate success probabilities are prioritized and stored in a dynamic buffer. Training batches are then formed by selecting a combination of high-variance problems from this buffer and additional randomly sampled examples from the dataset. This carefully crafted batch is then utilized to calculate policy gradients and update the model parameters. The efficacy of this strategy is validated by applying two reinforcement learning algorithms, PPO and VinePPO, to two mathematical reasoning datasets: MATH, comprising 12,000 competition-level problems, and GSM8K, comprising 8,000-grade school-level questions. Additional tests are performed on the CollegeMath and OlympiadBench datasets to quantify the generalization capabilities outside the original training distribution. The entire framework combines VinePPO with smooth optimizations such as gradient accumulation, multi-rollout estimation, and Deepspeed ZeRO to offer scalable performance.

The learning-driven selection mechanism greatly improves both the speed and efficiency of model training. Models trained with this curriculum are as accurate as models trained with traditional methods in roughly four times fewer training steps, with a remarkable improvement in convergence rates. Performance improves consistently through several datasets, with better test accuracy on GSM8K and MATH. The structured curriculum also generalizes to out-of-distribution tasks, with better generalization to datasets like CollegeMath and OlympiadBench. Training batch composition is optimized by eliminating questions with zero learning signal, leading to more efficient training. The approach is also found to be computationally beneficial, as sample generation can be scaled efficiently without redundant model updates. The combination of faster convergence, better generalization, and lower computational overhead makes this adaptive learning process a valuable and efficient tool for reinforcement learning-based LLM fine-tuning.

A paradigm for high-variance learning opportunity target question selection effectively addresses the inefficiencies witnessed in language model fine-tuning based on reinforcement learning. Focusing on problems that produce the most informative training signals maximizes learning efficiency, achieving faster improvement and better adaptability with new samples. Large-scale experiments validate the strategy to be better in enhancing training speed, test accuracy, and generalization to more than one dataset. The findings highlight the promise of structured sample selection in model training refinement improvement and computational resource optimization. Future studies on the strategy can investigate its applicability to other reinforcement learning tasks, such as reward model optimization, preference-based fine-tuning, and generalized decision-making tasks in AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Elevating AI Reasoning: The Art of Sampling for Learnability in LLM Training appeared first on MarkTechPost.
