
We are excited to announce Phi-4-multimodal and Phi-4-mini, the newest models in Microsoft’s Phi family of small language models (SLMs). These models are designed to empower developers with advanced AI capabilities. Phi-4-multimodal, with its ability to process speech, vision, and text simultaneously, opens new possibilities for creating innovative and context-aware applications. Phi-4-mini, on the other hand, excels in text-based tasks, providing high accuracy and scalability in a compact form. Now available in Azure AI Foundry, HuggingFace, and the NVIDIA API Catalog where developers can explore the full potential of Phi-4-multimodal on the NVIDIA API Catalog, enabling them to experiment and innovate with ease.
What is Phi-4-multimodal?
Phi-4-multimodal marks a new milestone in Microsoft’s AI development as our first multimodal language model. At the core of innovation lies continuous improvement, and that starts with listening to our customers. In direct response to customer feedback, we’ve developed Phi-4-multimodal, a 5.6B parameter model, that seamlessly integrates speech, vision, and text processing into a single, unified architecture.
By leveraging advanced cross-modal learning techniques, this model enables more natural and context-aware interactions, allowing devices to understand and reason across multiple input modalities simultaneously. Whether interpreting spoken language, analyzing images, or processing textual information, it delivers highly efficient, low-latency inference—all while optimizing for on-device execution and reduced computational overhead.
Natively built for multimodal experiences
Phi-4-multimodal is a single model with mixture-of-LoRAs that includes speech, vision, and language, all processed simultaneously within the same representation space. The result is a single, unified model capable of handling text, audio, and visual inputs—no need for complex pipelines or separate models for different modalities.
The Phi-4-multimodal is built on a new architecture that enhances efficiency and scalability. It incorporates a larger vocabulary for improved processing, supports multilingual capabilities, and integrates language reasoning with multimodal inputs. All of this is achieved within a powerful, compact, highly efficient model that’s suited for deployment on devices and edge computing platforms.
This model represents a step forward for the Phi family of models, offering enhanced performance in a small package. Whether you’re looking for advanced AI capabilities on mobile devices or edge systems, Phi-4-multimodal provides a high-capability option that’s both efficient and versatile.
Unlocking new capabilities
With its increased range of capabilities and flexibility, Phi-4-multimodal opens exciting new possibilities for app developers, businesses, and industries looking to harness the power of AI in innovative ways. The future of multimodal AI is here, and it’s ready to transform your applications.
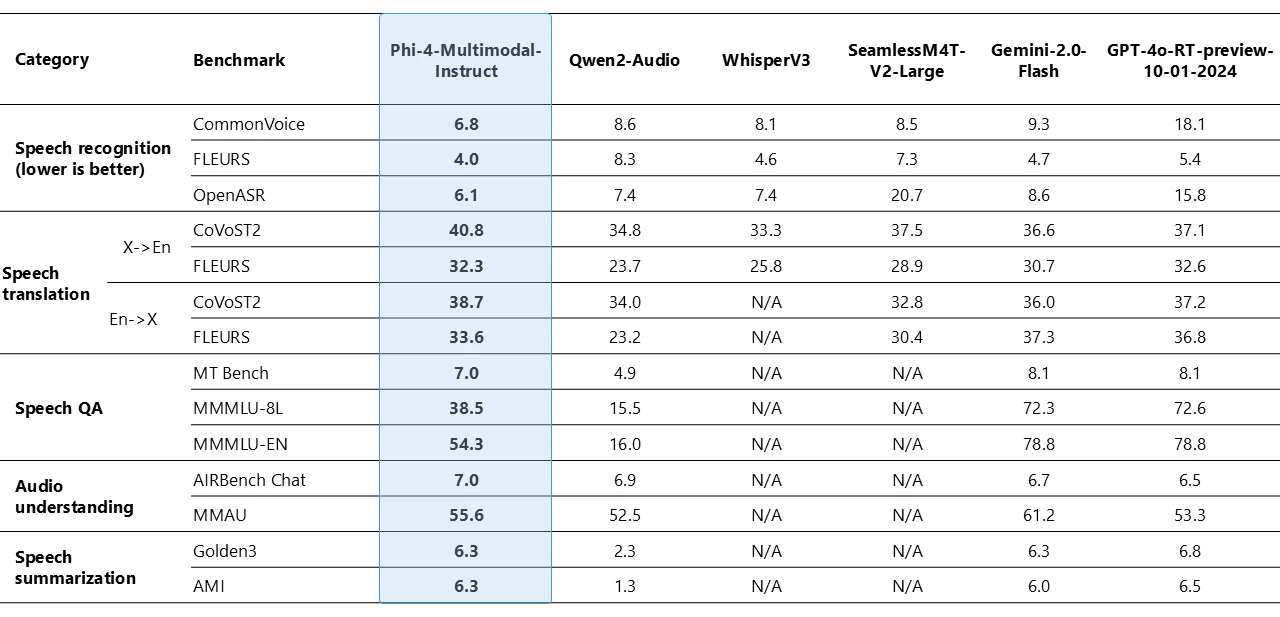
Phi-4-multimodal is capable of processing both visual and audio together. The following table shows the model quality when the input query for vision content is synthetic speech on chart/table understanding and document reasoning tasks. Compared to other existing state-of-the-art omni models that can enable audio and visual signals as input, Phi-4-multimodal achieves much stronger performance on multiple benchmarks.

Phi-4-multimodal has demonstrated remarkable capabilities in speech-related tasks, emerging as a leading open model in multiple areas. It outperforms specialized models like WhisperV3 and SeamlessM4T-v2-Large in both automatic speech recognition (ASR) and speech translation (ST). The model has claimed the top position on the Huggingface OpenASR leaderboard with an impressive word error rate of 6.14%, surpassing the previous best performance of 6.5% as of February 2025. Additionally, it is among a few open models to successfully implement speech summarization and achieve performance levels comparable to GPT-4o model. The model has a gap with close models, such as Gemini-2.0-Flash and GPT-4o-realtime-preview, on speech question answering (QA) tasks as the smaller model size results in less capacity to retain factual QA knowledge. Work is being undertaken to improve this capability in the next iterations.
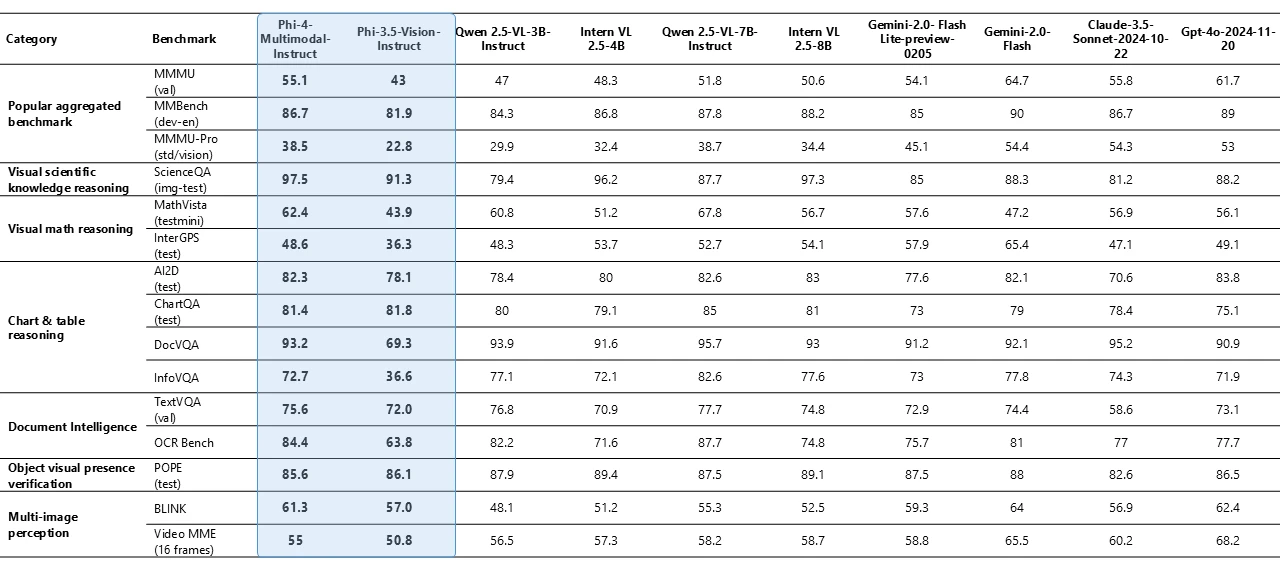
Phi-4-multimodal with only 5.6B parameters demonstrates remarkable vision capabilities across various benchmarks, most notably achieving strong performance on mathematical and science reasoning. Despite its smaller size, the model maintains competitive performance on general multimodal capabilities, such as document and chart understanding, Optical Character Recognition (OCR), and visual science reasoning, matching or exceeding close models like Gemini-2-Flash-lite-preview/Claude-3.5-Sonnet.
What is Phi-4-mini?
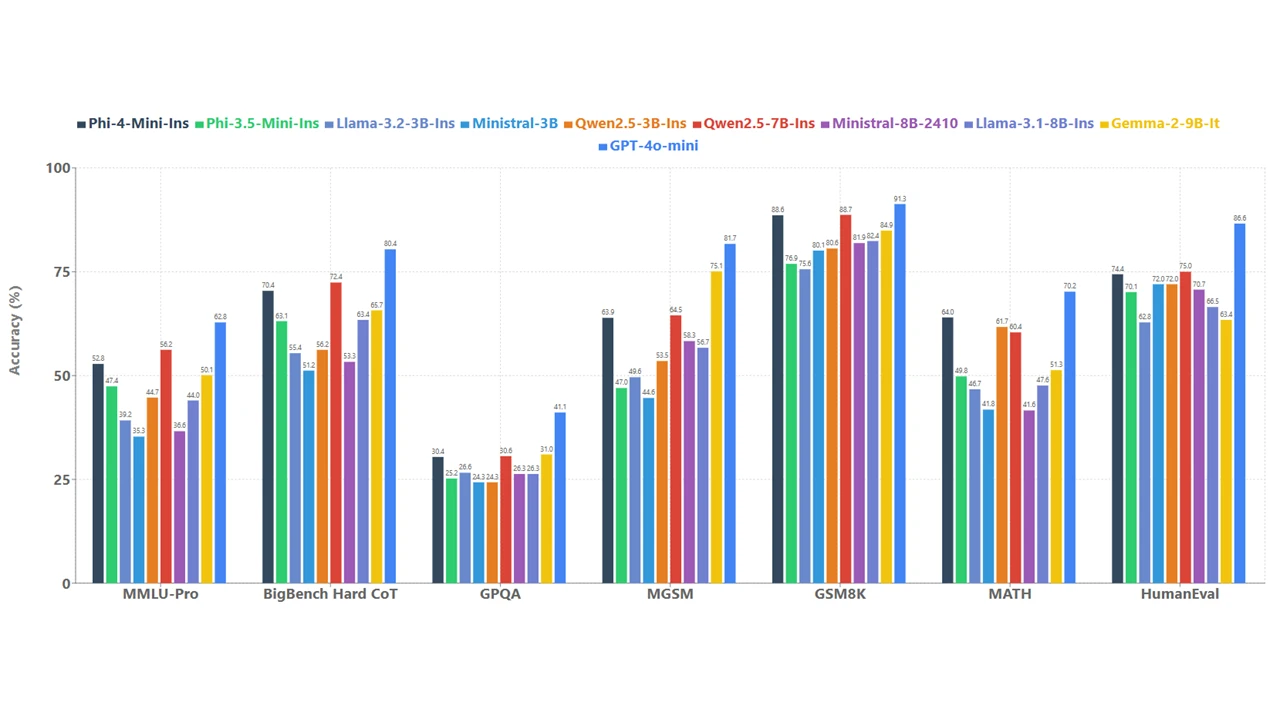
Phi-4-mini is a 3.8B parameter model and a dense, decoder-only transformer featuring grouped-query attention, 200,000 vocabulary, and shared input-output embeddings, designed for speed and efficiency. Despite its compact size, it continues outperforming larger models in text-based tasks, including reasoning, math, coding, instruction-following, and function-calling. Supporting sequences up to 128,000 tokens, it delivers high accuracy and scalability, making it a powerful solution for advanced AI applications.
To understand the model quality, we compare Phi-4-mini with a set of models over a variety of benchmarks as shown in Figure 4.
Function calling, instruction following, long context, and reasoning are powerful capabilities that enable small language models like Phi-4-mini to access external knowledge and functionality despite their limited capacity. Through a standardized protocol, function calling allows the model to seamlessly integrate with structured programming interfaces. When a user makes a request, Phi-4-Mini can reason through the query, identify and call relevant functions with appropriate parameters, receive the function outputs, and incorporate those results into its responses. This creates an extensible agentic-based system where the model’s capabilities can be enhanced by connecting it to external tools, application program interfaces (APIs), and data sources through well-defined function interfaces. The following example simulates a smart home control agent with Phi-4-mini.
At Headwaters, we are leveraging fine-tuned SLM like Phi-4-mini on the edge to enhance operational efficiency and provide innovative solutions. Edge AI demonstrates outstanding performance even in environments with unstable network connections or in fields where confidentiality is paramount. This makes it highly promising for driving innovation across various industries, including anomaly detection in manufacturing, rapid diagnostic support in healthcare, and enhancing customer experiences in retail. We are looking forward to delivering new solutions in the AI agent era with Phi-4 mini.
—Masaya Nishimaki, Company Director, Headwaters Co., Ltd.
Customization and cross-platform
Thanks to their smaller sizes, Phi-4-mini and Phi-4-multimodal models can be used in compute-constrained inference environments. These models can be used on-device, especially when further optimized with ONNX Runtime for cross-platform availability. Their lower computational needs make them a lower cost option with much better latency. The longer context window enables taking in and reasoning over large text content—documents, web pages, code, and more. Phi-4-mini and multimodal demonstrates strong reasoning and logic capabilities, making it a good candidate for analytical tasks. Their small size also makes fine-tuning or customization easier and more affordable. The table below shows examples of finetuning scenarios with Phi-4-multimodal.
| Tasks | Base Model | Finetuned Model | Compute |
| Speech translation from English to Indonesian | 17.4 | 35.5 | 3 hours, 16 A100 |
| Medical visual question answering | 47.6 | 56.7 | 5 hours, 8 A100 |
For more information about customization or to learn more about the models, take a look at Phi Cookbook on GitHub.
How can these models be used in action?
These models are designed to handle complex tasks efficiently, making them ideal for edge case scenarios and compute-constrained environments. Given the new capabilities Phi-4-multimodal and Phi-4-mini bring, the uses of Phi are only expanding. Phi models are being embedded into AI ecosystems and used to explore various use cases across industries.
Language models are powerful reasoning engines, and integrating small language models like Phi into Windows allows us to maintain efficient compute capabilities and opens the door to a future of continuous intelligence baked in across all your apps and experiences. Copilot+ PCs will build upon Phi-4-multimodal’s capabilities, delivering the power of Microsoft’s advanced SLMs without the energy drain. This integration will enhance productivity, creativity, and education-focused experiences, becoming a standard part of our developer platform.
—Vivek Pradeep, Vice President Distinguished Engineer of Windows Applied Sciences.
- Embedded directly to your smart device: Phone manufacturers integrating Phi-4-multimodal directly into a smartphone could enable smartphones to process and understand voice commands, recognize images, and interpret text seamlessly. Users could benefit from advanced features like real-time language translation, enhanced photo and video analysis, and intelligent personal assistants that understand and respond to complex queries. This would elevate the user experience by providing powerful AI capabilities directly on the device, ensuring low latency and high efficiency.
- On the road: Imagine an automotive company integrating Phi-4-multimodal into their in-car assistant systems. The model could enable vehicles to understand and respond to voice commands, recognize driver gestures, and analyze visual inputs from cameras. For instance, it could enhance driver safety by detecting drowsiness through facial recognition and providing real-time alerts. Additionally, it could offer seamless navigation assistance, interpret road signs, and provide contextual information, creating a more intuitive and safer driving experience while connected to the cloud and offline when connectivity isn’t available.
- Multilingual financial services: Imagine a financial services company integrating Phi-4-mini to automate complex financial calculations, generate detailed reports, and translate financial documents into multiple languages. For instance, the model can assist analysts by performing intricate mathematical computations required for risk assessments, portfolio management, and financial forecasting. Additionally, it can translate financial statements, regulatory documents, and client communications into various languages and could improve client relations globally.
Microsoft’s commitment to security and safety
Azure AI Foundry provides users with a robust set of capabilities to help organizations measure, mitigate, and manage AI risks across the AI development lifecycle for traditional machine learning and generative AI applications. Azure AI evaluations in AI Foundry enable developers to iteratively assess the quality and safety of models and applications using built-in and custom metrics to inform mitigations.
Both models underwent security and safety testing by our internal and external security experts using strategies crafted by Microsoft AI Red Team (AIRT). These methods, developed over previous Phi models, incorporate global perspectives and native speakers of all supported languages. They span areas such as cybersecurity, national security, fairness, and violence, addressing current trends through multilingual probing. Using AIRT’s open-source Python Risk Identification Toolkit (PyRIT) and manual probing, red teamers conducted single-turn and multi-turn attacks. Operating independently from the development teams, AIRT continuously shared insights with the model team. This approach assessed the new AI security and safety landscape introduced by our latest Phi models, ensuring the delivery of high-quality capabilities.
Take a look at the model cards for Phi-4-multimodal and Phi-4-mini, and the technical paper to see an outline of recommended uses and limitations for these models.
Learn more about Phi-4
We invite you to come explore the possibilities with Phi-4-multimodal and Phi-4-mini in Azure AI Foundry, Hugging Face, and NVIDIA API Catalog with a full multimodal experience. We can’t wait to hear your feedback and see the incredible things you will accomplish with our new models.
The post Empowering innovation: The next generation of the Phi family appeared first on Microsoft Azure Blog.
