
那么,有什么方法能自动筛选出,甚至是自动创建出高质量又兼具多样性的数据集?
最近,Meta、UC伯克利、NYU等机构的学者提出了一种最新方法,简称RIP,让低质量数据「一路走好」的同时,也是在暗示——只有成功存活下来的数据才是高质量的数据。

受到进化算法的启发,RIP在Alpacaeval2、Arena-Hard、Wildbench等多个有影响力的基准上实现了大幅提升,获得了LeCun的转赞。

RIP方法概述
拒绝指令偏好(RIP)的基础是两个核心假设。
第一个假设是,低质量prompt很可能产生低质量响应。具体来说,那些意义不明确、模糊或包含冲突信息的提示词,很可能导致嘈杂或不准确的模型响应。这些提示词不应该作为之后用于指令微调(SFT)的训练数据。
第二个假设是,低质量prompt很可能产生具有更大差异的响应。
低质量prompt会引入不确定性和模糊性,可能存在多种解释,因此LLM可能会猜测或填补提示词中的空白,这导致多次响应之间的差异性更高。虽然其中一些响应可能与prompt的原始意图一致,但其他响应可能显著偏离。
从这一点上进行逆向思考,我们就可以将模型多次响应的方差视为评估提示词质量的指标。方差越小,表明提示词的质量更高。
基于上述两个假设,RIP方法就可以测量被拒绝的响应质量(下图m_1),以及被选择和被拒绝的响应之间的奖励差距(reward gap,下图m_3),从而评估数据的完整性。

上图中定义的3个关键指标分别有如下含义:
m_1:被拒绝响应的的质量。
m_2:被拒绝响应的长度,较长的被拒绝响应可能意味着提示更复杂或更模糊。
m_3:被选择与被拒绝响应之间的奖励差距,较小的差距可能表明提示更清晰、更具体。
基于这种方法,RIP可以用于筛选、构建高质量数据集。给定一组提示词X={x} ,RIP旨在找到一个子集S⊆X ,S可用于微调大模型ℳ。
RIP如同设定一个优胜劣汰的提示词斗兽场,提示词对应的响应要么获胜(被选择),要么失败(被拒绝)。响应对及其奖励可以来自人类偏好数据,也可以由模型本身ℳ生成,然后使用其它大模型进行评分。
除了过滤现有训练集,RIP也可以用于构建高质量合成数据集。
用于生成合成数据时,首先筛选出一组高质量的提示作为种子池,然后使用这些种子提示词作为少量样本,引导模型生成新的提示词。
这些新生成的提示词可以进一步通过RIP进行筛选,以确保合成数据的质量,这种方法被称为Self-RIP。
实验结果与分析
RIP在多个实验中都取得了显著的性能提升,尤其是在人类编写的提示上,表现出了显著的优势。
例如,在包含超过25万条人工编写提示词的WildChat数据集上,通过Llama 3.1-405B-Instruct评估响应的质量,为每个回答需进行 10 次独立评估,每次给出0到10分的评分,并使用平均分作为最终奖励。
如下表所示,RIP只需要不到一半的训练样本,就能在多个指标上实现显著提升。
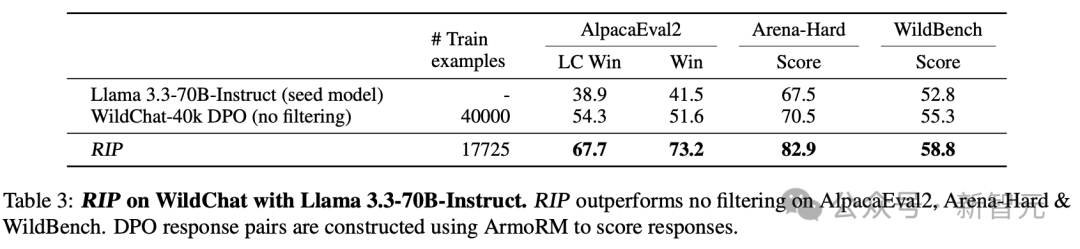
使用RIP过滤出高质量的提示词后,RIP显著提高了Llama3.1-8B-Instruct DPO基线的性能。
在更大参数的模型上,RIP同样有效。过滤显著提升了Llama 3.3-70B-Instruct模型的性能,AlpacaEval2 LC胜率从38.9提升至67.7,Arena Hard从67.5提升至82.9,WildBench从52.8提升至58.8。
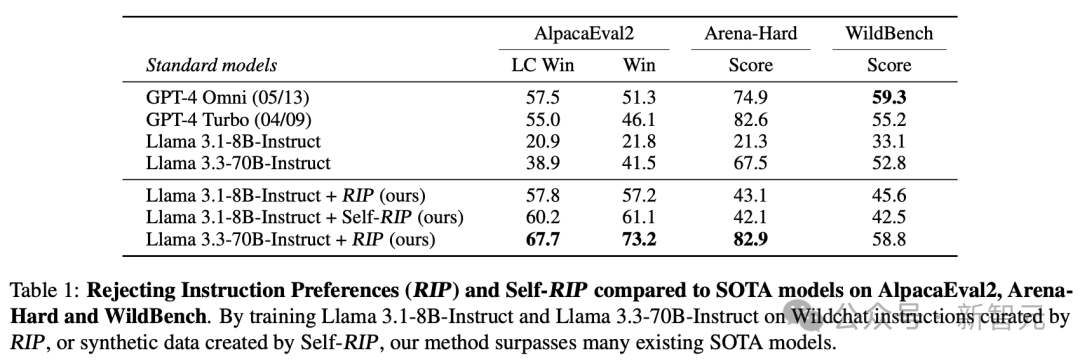
这些结果表明,RIP能够有效地筛选出高质量的提示,从而提升模型的性能。
应Self-RIP方法 ,基于少样本生成而不进行后过滤得到20k大小的数据集,可以让模型在AlpacaEval2上的LC胜率从 48.4%提高到53.6%,Arena-Hard胜率从37.9%提高到43.7%,以及在WildBench上的WB-Score从41.5提高到44.8。这进一步说明了在高质量指令上训练的重要性。
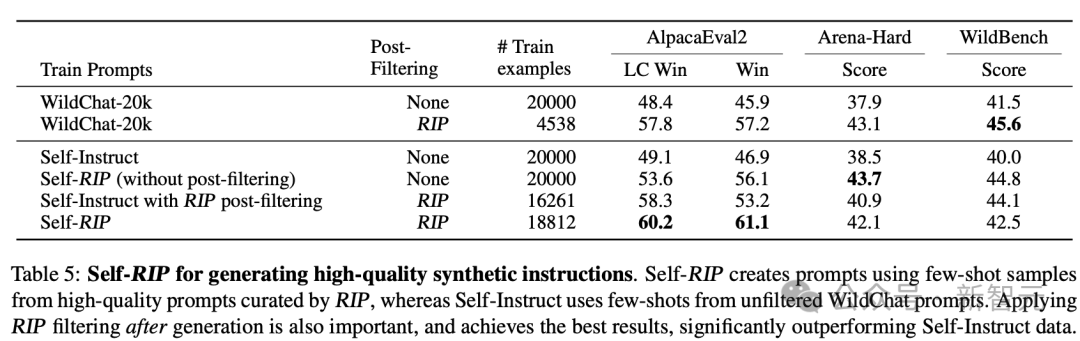
当应用完整的Self-RIP方法并使用后过滤(post-filtering)时,训练效果进一步改善,实现了最佳的AlpacaEval2 LC胜率60.2%。
RIP在与其他筛选方法的比较中也表现出色。与基于提示的筛选方法(如InsTag Diversity/Difficulty Filtering)相比,RIP在所有基准测试中都取得了更高的分数。
此外,与基于提示和选择响应的筛选方法(如PPL和IFD)相比,RIP也表现出更好的性能。这些结果表明,RIP在筛选提示时考虑了更多的因素,从而能够更准确地评估提示的质量。
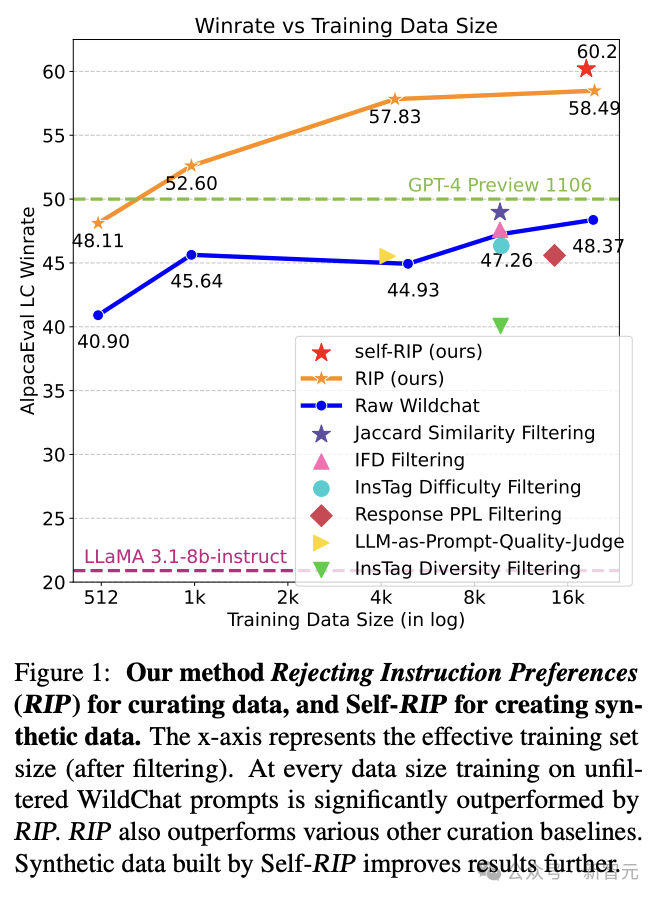
图1:不同训练数据大小下,使用RIP及self-RIP之后的模型训练效果提升。
总体来看,RIP借鉴进化算法,为LLM的训练提供了一种简单却新颖的思路。相比人类编写的和模型生成的提示词,使用RIP过滤后的提示词集合,在进行指令微调后,模型性能有显著提升。
未来的研究可以在此基础上进行进一步的探索和改进。例如,可以研究如何优化评估模型,以提高其对响应质量的评估准确性;可以探索如何降低RIP方法的计算成本,使其更适合大规模数据的处理;还可以研究进行安全性评估——探索使用RIP进行安全性过滤,在现有系统中构建专门用于安全性的奖励模型。
https://arxiv.org/abs/2501.18578
https://x.com/jaseweston/status/1885160135053459934



内容中包含的图片若涉及版权问题,请及时与我们联系删除
