

作者:高超尘、伍星 等
机构:中国科学院信息工程研究所/小红书/清华
Arxiv:https://arxiv.org/abs/2501.12766
Huggingface:https://huggingface.co/datasets/caskcsg/NExtLong-512K-dataset 目前五个数据集累积下载次数超过1200次。
Github:https://github.com/caskcsg/longcontext/tree/main/NExtLong
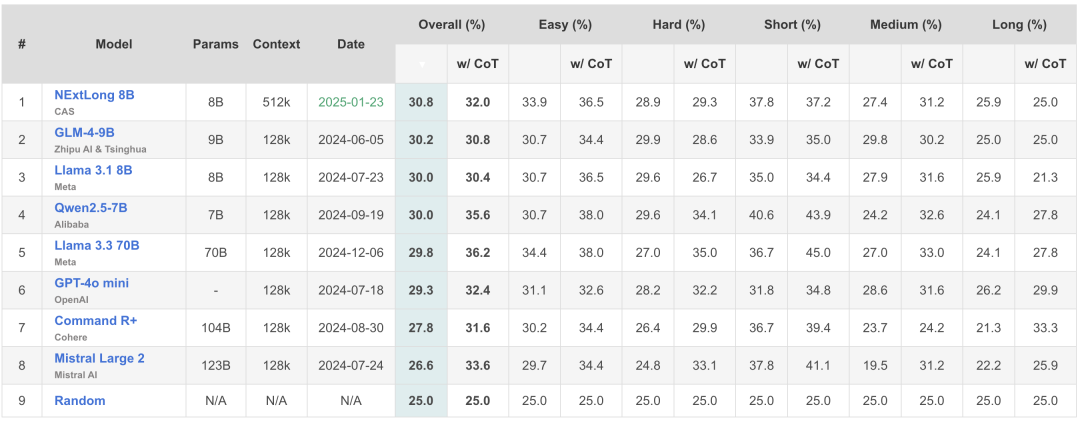
Longbench V2榜单:NExtLong 8B在10B以下长文本大模型中排名第一!
简介:在这篇文章中,我们提出了长文本数据合成办法NExtLong,该方法让大模型摆脱了对原生长文本数据集的强依赖,可以使用短文本数据集训练出SOTA级别的长文本大模型,并且有助于训练出任意长度且性能强大的长文本大模型。
一、背景:原生长文本数据匮乏,且现有长文数据合成方法缺少明确捕捉长依赖的机制。
长文本大模型因其强大且丰富的能力而受到了广泛关注。近来,长文本大模型的上下文长度得到了快速扩展,例如Llama系列模型的上下文长度从Llama 2的4K增加到Llama 3.1的128K。这种扩展的上下文窗口使LLMs能够解锁更具挑战性的任务,如文档摘要、长篇小说问答和代码规划。面对非常长的上下文需求,一种广泛采用的方法是收集并使用长上下文数据继续训练大语言模型。然而,随着目标上下文长度的不断增加,大多数领域中高质量长文档的稀缺性仍然是一个重大挑战。
为了应对长文档稀缺的挑战,现有的方法通过拼接较短的文档来合成长上下文数据。然而,这些方法通常基于随机或基于相似性的排名拼接短文档,缺乏明确的机制来捕捉长距离依赖关系。此外,最新的研究表明,大型语言模型很容易被无关上下文分散注意力,这一问题随着上下文长度的增加而加剧。这提出了一个关键挑战:在处理长上下文任务时,我们如何增强模型从大量干扰内容中甄别长距离关键信息的能力?
二、NExtLong:如何增强模型从大量干扰内容中甄别长距离关键信息的能力?
受对比学习中的困难负样本(hard negative)技术的启发,该技术通过引入困难负样本来增强模型区分相关样本与干扰样本的能力,我们将这一概念适应为创建加强长距离依赖建模的困难干扰项。关键思想是通过在依赖段之间插入语义相似但具有干扰性的文本来生成负例扩展文档。这些干扰增加了模型的学习难度,从而增强了其建模长距离依赖关系的能力。具体来说,NExtLong首先将文档分块为多个顺序依赖的片段,称为meta-chunks。我们从预训练语料库中检索meta-chunks的困难负样本,并将它们插入顺序依赖的meta-chunks之间。由于预训练语料库经过广泛的去重处理,这些困难负样本与meta-chunks部分语义相似,但并不重复。通过将这些干扰项插入原本依赖的meta-chunks之间,NExtLong不仅增加了依赖片段之间的距离,有效地将短依赖关系转化为长距离依赖关系,还引入了干扰噪音,迫使模型加强其区分长距离依赖的关键上下文与其他干扰内容的能力。
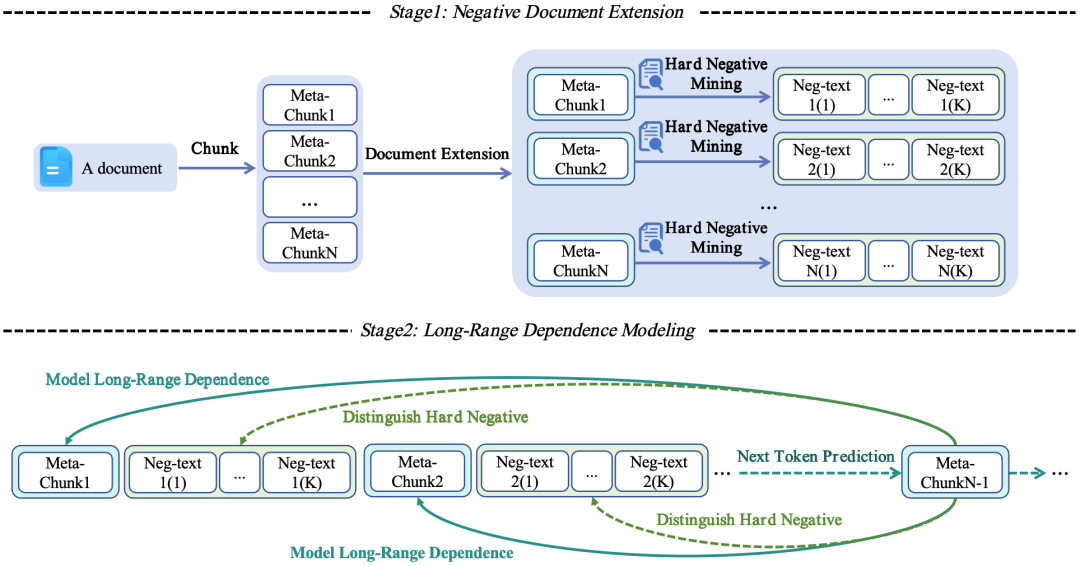
NExtLong分为两个阶段:负例文档扩展(Negative Document Extension)和长距离依赖建模(Long-Range Dependence Modeling)。NExtLong 旨在通过合成负例长文档来增强长上下文建模。
2.1 负例文档扩展
负例文档扩展阶段包含两个步骤:文档分块和困难负样本挖掘。
(1)文档分块: 首先,我们从训练数据集中采样一篇文档作为元文档(meta-document),并将其划分为连续的元块(meta-chunks)。我们将待扩展的文档定义为meta-document。meta-document根据分块粒度(chunking granularity)被划分为多个块,这些块被称为meta-chunks。为了确保chunks语义的完整性,我们定义最大长度 作为分块粒度。分块过程遵循以下两个步骤:
(2)困难负样本挖掘: 为了获取每个meta-chunks的干扰文本作为困难负样本,我们使用经过广泛去重的预训练数据集构建 FAISS 索引。与将整个文档视为不可分割单元的KNN类方法不同,我们还将预训练数据集中的每个文档基于相同的粒度 s 划分为更小的块。这种分块方法使得在扩展过程中能够进行更细粒度且高效的内容检索。具体来说,预训练数据集中的文档也会被分为若干chunks。
每个chunk被单独建立索引以实现精确和高效的检索。我们计算每个chunks的embedding向量并将其插入FAISS索引。
构建FAISS索引后,我们为每个meta-chunks检索前k个最相似的文本作为困难负样本。这些困难负样本随后与meta-chunks连接形成扩展块:
最后,我们通过连接扩展块合成一个长文档:
2.2长距离依赖建模
与预训练阶段一致,我们采用Next Token Prediction loss(NTP)来训练并扩展基础模型的上下文长度。损失函数定义为:
NExtLong和其他使用NTP loss的方法的关键区别在于,NExtLong在训练期间促使模型对不同类型的token进行了区分。合成后的长文档中的tokens被分为两类:来源于meta-chunks 的tokens 以及来源于困难负样本 的tokens,它们共同形成一个扩展块。为简化起见,我们使用、 和 分别表示meta-chunks、困难负样本和扩展块编码之后的tokens。损失函数可以重新表述为:
在训练过程中,NTP loss 损失鼓励模型区分在上文中远端的meta-chunks与周围的困难负样本,并有效地建模长依赖关系。伪代码如下图所示:

三、实验设置及结果
在本节中,我们通过将NExtLong与其他数据合成方法以及最先进的SOTA模型进行比较,证明了NExtLong合成数据的有效性。
训练数据集: 我们选择了预训练数据集Cosmopedia v2以及FineWeb-Edu来合成长文本数据集,这两个数据集由短文档组成。最近的长文评测工作主要集中在构建128K长度的评测集。因此,我们将合成数据的长度设置为128K以进行全面评估。
评测数据集: 我们使用HELMET 和 RULER基准来评估预训练Base模型,以及Longbench V2来评估Instruct 模型。评估涵盖了HELMET基准中的五种任务类型:合成召回、检索增强生成(RAG)、多样本上下文学习(ICL)、段落重排序和长文档问答,共包括17个子任务。此外,RULER基准包括13个合成子任务。
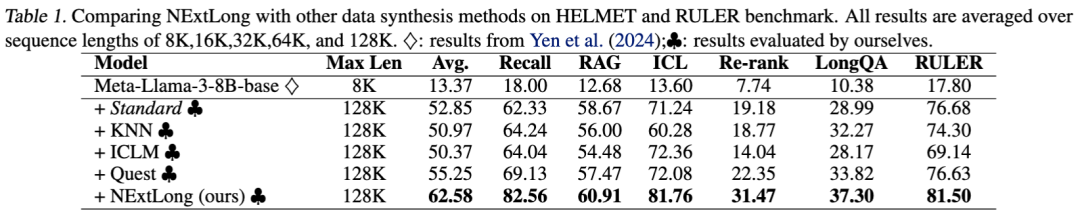
3.1 NExtLong 大幅超过了以往的长文数据合成方法。
我们使用不同的数据合成方法分别合成了128K的长文本数据集,在最新的HELMET 以及RULER Benchmark进行了测试,实验结果如下表所示,可以发现,我们的NExtLong 方法超过了之前最好的数据合成方法Quest(ICLR 2025),平均性能提升了7.33%。
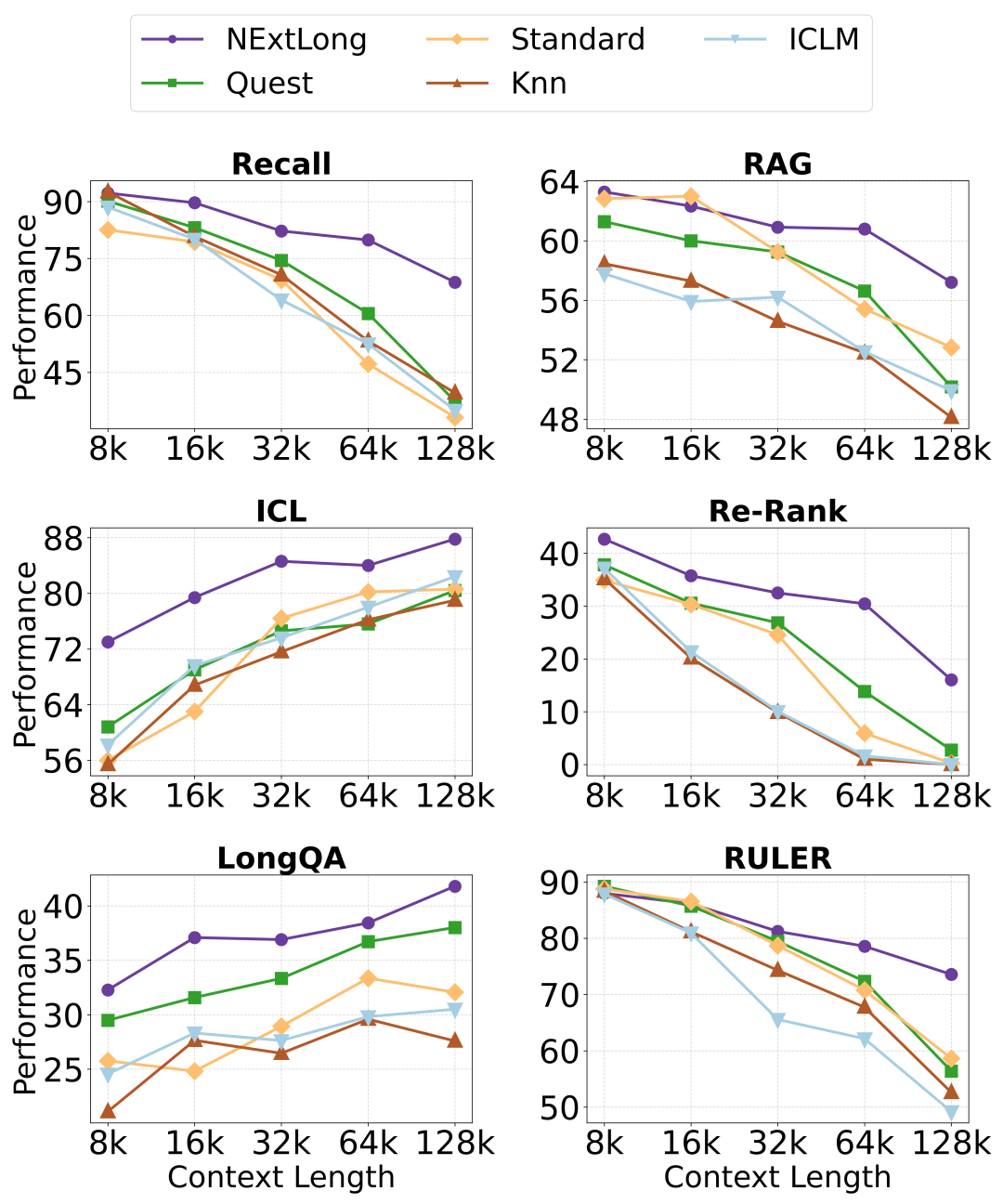
此外,我们统计了不同长度区间下的模型性能表现,如下图所示,NExtLong 在不同上下文长度下优于其他方法,且随着上下文长度的增加,优势更加明显。结果表明,NExtLong 在建模长依赖方面具有卓越的能力,即使在 128K 的上下文长度下也能保持稳健的性能,这展示了 NExtLong 在不同任务中的多功能性和可靠性,以及其在处理超长上下文任务的有效性。
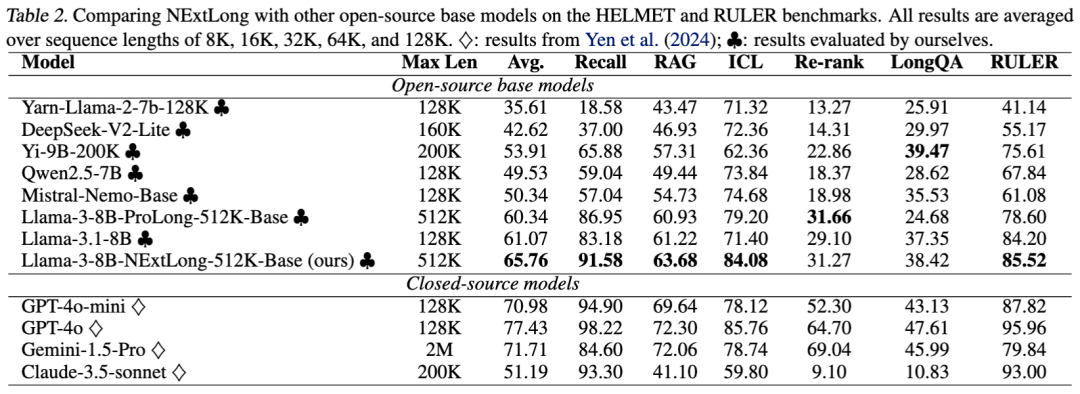
3.2 在不使用原生长文本数据集的情况下,NExtLong预训练长文本模型达到了最先进的开源效果。
为了进一步挖掘NExtLong的潜力,我们使用Cosmopedia v2以及FineWeb-Edu合成了512K的数据集,并使用了两阶段的长文扩展方法训练出了 LLama-3-8B-NExtLong-512K-Base 模型。和其他开源模型相比,该模型在HELMET和RULER测试中的平均指标达到了最高水平。
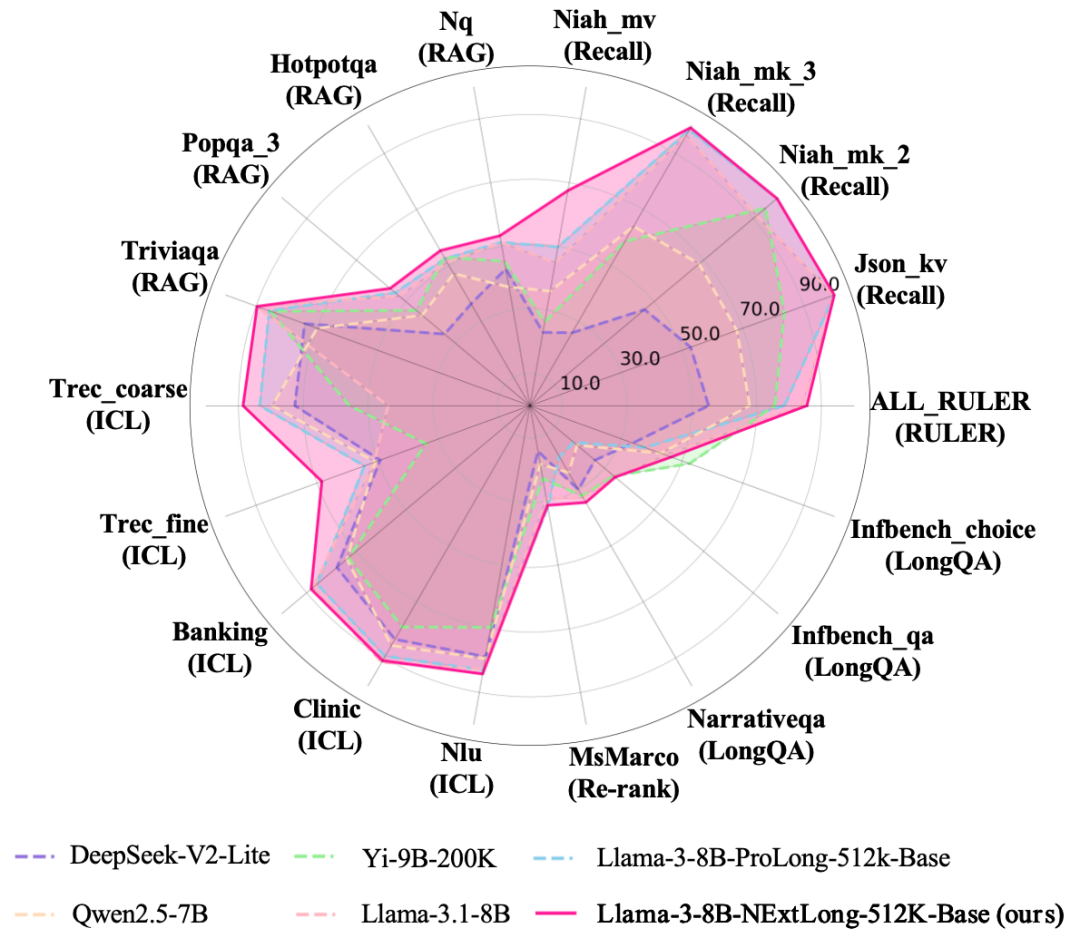
3.3 在ICL任务中,8B NExtLong模型甚至超过了GPT-4O。
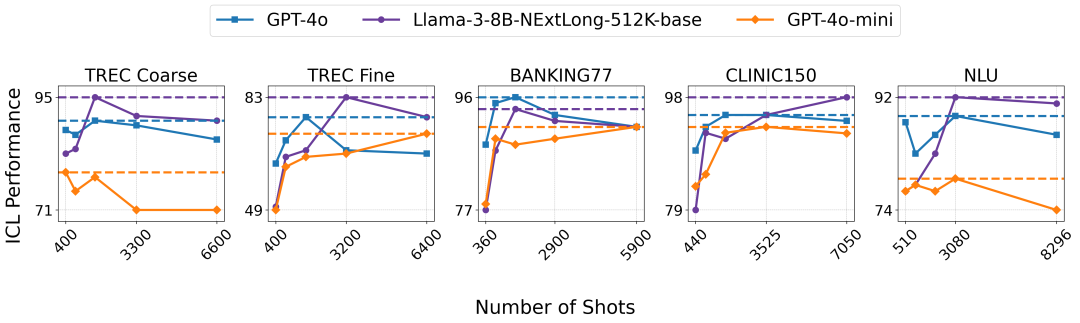
最近,长上下文模型在ICL(上下文学习)任务中的表现引起了广泛关注。在下图中,随着示例数量的增加,8B的 NExtLong模型在 Banking77 任务中与 GPT-4o 表现相当,并在其他四个任务中超越了 GPT-4o。其强大的性能和较小的计算成本使得 NExtLong 非常适合未来的 ICL 应用。
3.4 在Longbench V2的榜单上,经过开源SFT数据集微调的8B NExtLong Instruct模型在10B以下模型中排名第一。
我们使用开源SFT数据集Magpie-Align/Magpie-Llama-3.3-Pro-1M-v0.1 对 NExtLong Base微调。NExtLong Instruct模型 在10B以下的模型中排名第一。
四、实验分析:为什么NExtLong有效?
我们在128K的长度上,对NExtLong进行了消融分析。
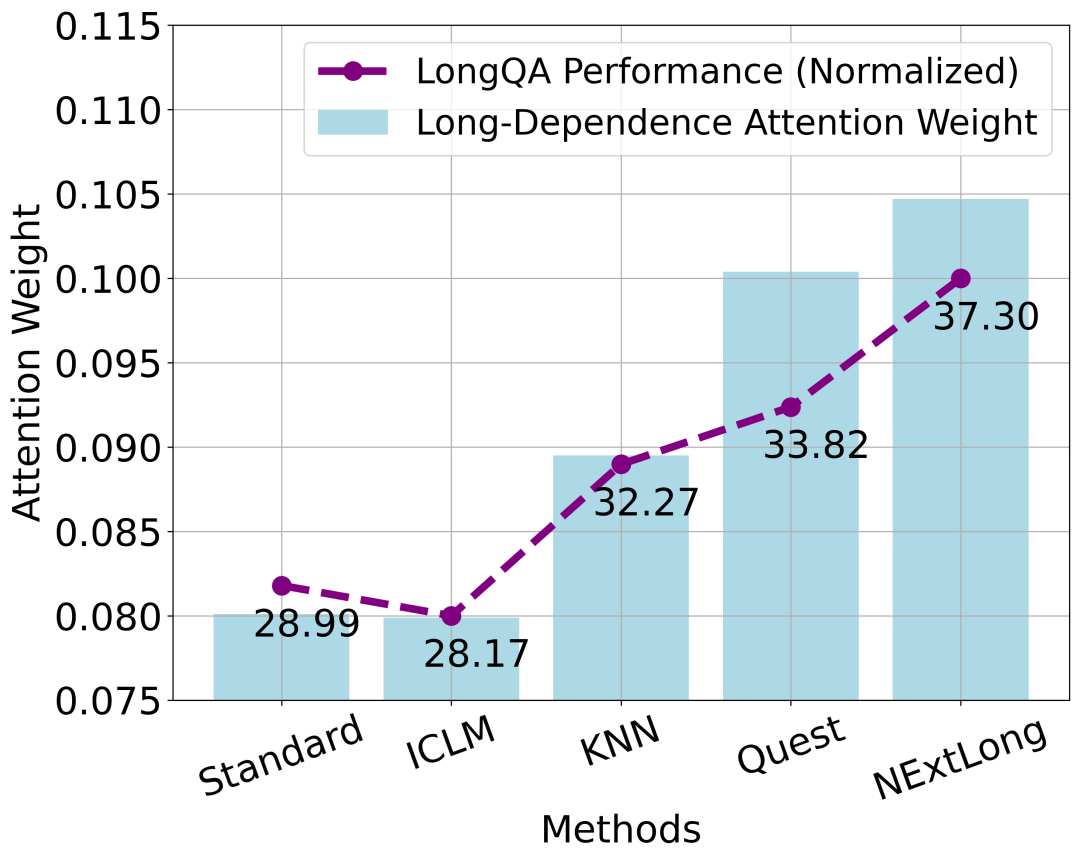
4.1 NExtLong 增强了长距离依赖建模能力。
为了评估 NExtLong 在长距离依赖建模方面的改进,我们使用 Longbook QA 数据集进行了一项探测实验。在实验中,我们使用模型在预测下一个词时分配给处于上文前三分之一区间文本的归一化注意力权重,作为评估模型长距离依赖建模能力的指标。如下图所示,我们观察到这一长距离依赖指标与模型在 LongQA 任务上的表现呈正相关。这表明,通过 NExtLong 的负例长文档训练的模型表现出更强的长距离依赖建模能力,从而显著提升了长上下文任务的性能。
4.2 困难负样本(hard negatives)对于达到更好的结果至关重要。
为了评估困难负样本对性能的影响,我们设计了五种文档检索策略。对于每个meta-chunks,我们从FAISS索引中检索出512个文档,并使用以下策略从中选择:
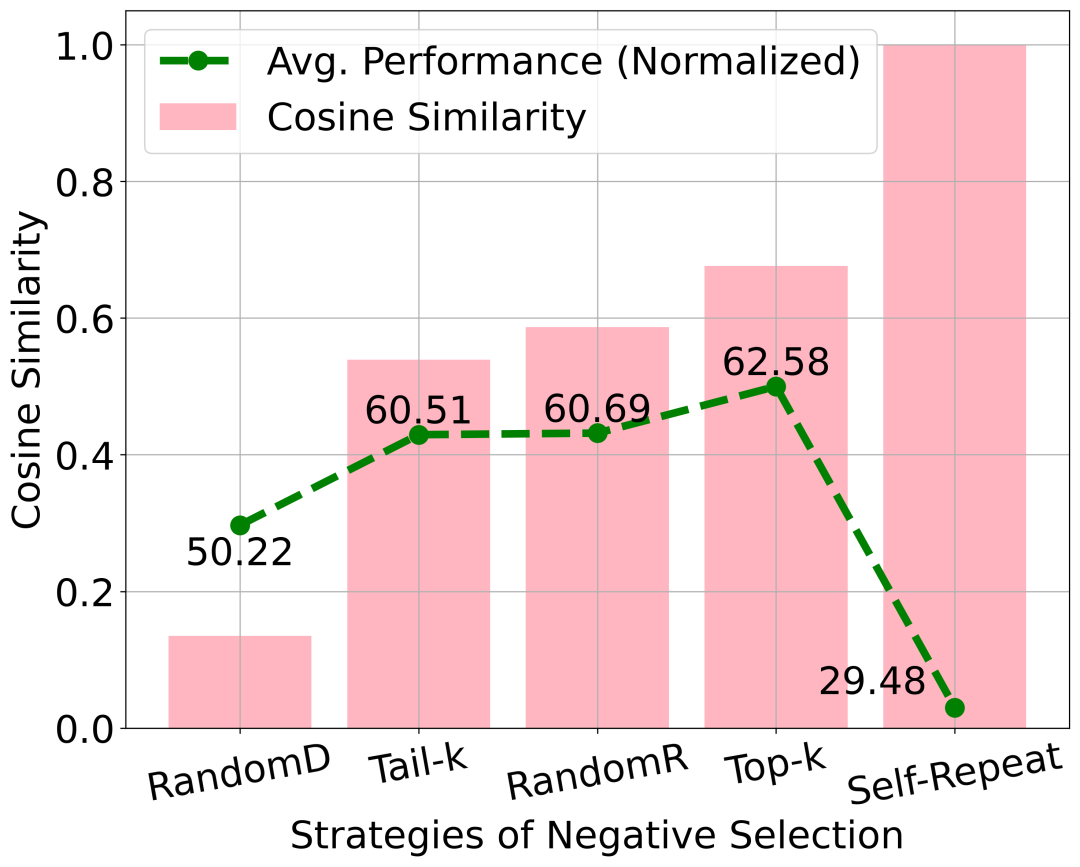
上图表明,选择困难负样本在NExtLong中起着至关重要的作用。低相似度的负样本降低了训练难度,从而削弱了性能。同时,使用重复的meta-chunks会引入假负样本,进一步降低模型性能,这与对比学习中观察到的现象一致。
总结
本文介绍了NExtLong,一个通过负例文档扩展的方法来合成长文本数据,帮助提升大语言模型的长距离依赖建模能力。通过将文档划分为meta-chunks并插入难以区分的负样本干扰项,NExtLong增加了长文本的建模学习难度,促使大模型在扩展上下文中更好地建模长距离依赖关系。实验结果显示,NExtLong在HELMET和RULER基准测试中超越了现有开源方法,取得了显著的性能提升。未来,我们将会在更长的文本上验证NExtLong的有效性。同时,我们计划探索更有效的负样本挖掘策略,例如采用生成式方法创建更多样化且更具挑战性的干扰项,从而进一步增强模型学习细粒度长距离依赖的能力。
