
Published on February 22, 2025 4:43 AM GMT
Epistemic status: I'm attempting to relate my observations, as well as some of those shared with me by my coworkers at the small CRO[1] where I work. I will try to make the distinction clear between object-level observations and speculative interpretations of the former.
The (very simplified) process of developing a new drug or medical device follows these approximate steps:
- Novel Compound Phlebotinum is selected from a pool of candidate molecules[2] as most promising for clinical usesIn vitro experiments are performed in labs to confirm that the substance behaves as predictedAssuming step 2 results were promising, animal trials are conducted in hopes that fruit flies/rats/pigs/monkeys will have enough biological similarity with us to provide meaningful information about how Phlebotinum might affect humansAssuming step 3 passed, lots of paperwork is filed to assure officials that
This is where the problems begin to appear.[3]
One of the biggest can be summarized as "lack of data standardization".
To be clear, standards do exist, and in fact the Regulatory Authorities (by whose evaluation your new treatment will succeed or fail[4]) require the data they receive to conform to these standards. But despite this, a disturbingly common attitude of many of those companies running studies has been "just get the data collected, we'll let the CRO format/standardize the data later".
Some attitudes with comparable failure modes might be:
Software developers: "Just keep coding, we can fix it later" (about a fundamental design flaw in a foundational piece of code).
Amateur bakers: "No need to follow the recipe, cake is super easy! We'll just cover any problems with frosting later."
Rocket scientists: "The standards are really just guidelines, we'll do whatever we have the time for. The astronauts are smart, we can fix any problems as they come up."[5]
The intuitive heuristic is that generally, doing something correctly from the beginning will be far more efficient than doing it wrong and having to backtrack later to fix it. This is well demonstrated in collecting data for analysis.
Here is an example of pressures that incentivize messing it up:
For a demographics form, which ~every human trial has, you typically collect race. The acceptable entries for RACE are CDISC controlled terminology. They are trying to have every piece of data be fitted into the best match in the pre-defined categories. In this case, as of 2024-09-27 the available terms are:
AMERICAN INDIAN OR ALASKA
NATIVE
ASIAN
BLACK OR AFRICAN AMERICAN
NATIVE HAWAIIAN OR OTHER
PACIFIC ISLANDER
NOT REPORTED
OTHER
UNKNOWN
WHITE
Which obviously cover all emphatic self-identifications any human on earth could possibly have /s
The point here is not that these options specifically are the best way to divide reality at the seams. Most studies would be better served collecting genetic data and determining 'race' by ancestry for biological contexts and using other proxies for information relevant to cultural contexts.
At the end of the day, no matter how much any subject or doctor protests and demands to be able to enter their preferred verbatim option-not-on-the-list, when the data is prepared to be sent off in a New Drug Application to the FDA, if the person preparing it knows what the FDA requires they will see that RACE is a non-extensible code list and thus only the options in the list of controlled terminology are acceptable.
Therefore, any data for that variable that is not on that list will need to be queried or otherwise adjusted with meticulous effort to match the available options such that nothing is lost or changed. By allowing any options in the data entry field to deviate from the standardized terminology, they are accomplishing nothing other than making more work for themselves or those they've hired.
And don't get me started on free text fields. Data collected in free text may as well be blank for the purposes of statistical analysis for clinical relevance[6]. Most instances of the "comments" or "notes" fields in trials are added presumably because doctors (clinicians) are the ones usually designing the trials and their workflow for treating patients typically involves keeping extensive individualized notes for each patient, but this is not well fitted to the task of "collecting data that can be analyzed in bulk".
Other areas of inefficiency:
Paper source documents instead of digital
Most trials are still collected on paper source documents before being entered into EDC (Electronic Data Capture) platforms, in spite of the FDA recommending eSource since at least 2014.
This is also despite the fact that it requires the clinics to do both paper data collection and then enter the same data into an EDC.[7] After that there is the arduous task of source document verification where they have some unfortunate person go through and double check that all the electronic records match their respective papers.
Since my perspective is further downstream than the clinics I can only speculate why most of them are still using paper. Is it because of the aging workforce's reluctance to embrace change? If any of you has insight please enlighten me.
Difficult software
EDC platforms themselves are in my experience badly optimized behemoths with labyrinthine user interfaces and loaded with as many idiosyncrasies as they can get away with. They frequently lack for many of the features we take for granted on modern sites such as:
- Well-documented APIs[8]Ability to revert to previous state when making changes[9]Ability to export entire study of settings & configurations into a file that can then be re-imported[10]Ability to handle calculated fields with algorithms more complex than addition and subtraction[11]Many more. These are just those that leapt readily to mind
Inconsistent instruments
Last but not least, there are many Official Instruments that are used in spite of[12] their design rather than because of it.
One of the most egregious examples is the CDR. I don't have any specific complaints about the questions on the form itself—I have problems with the over-engineered proprietary scoring algorithm that is used to calculate the Global Score.
Here is a demonstration of the official implementation:
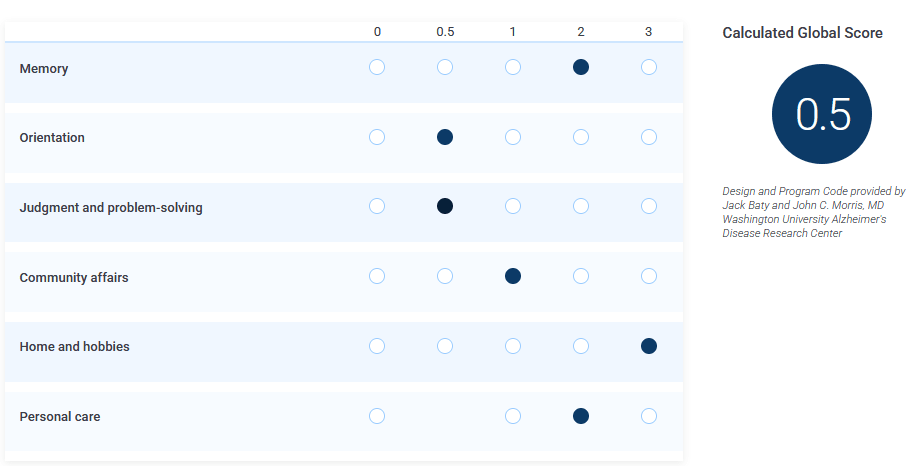
Then, here I change the "judgement" value from 0.5 to 0:
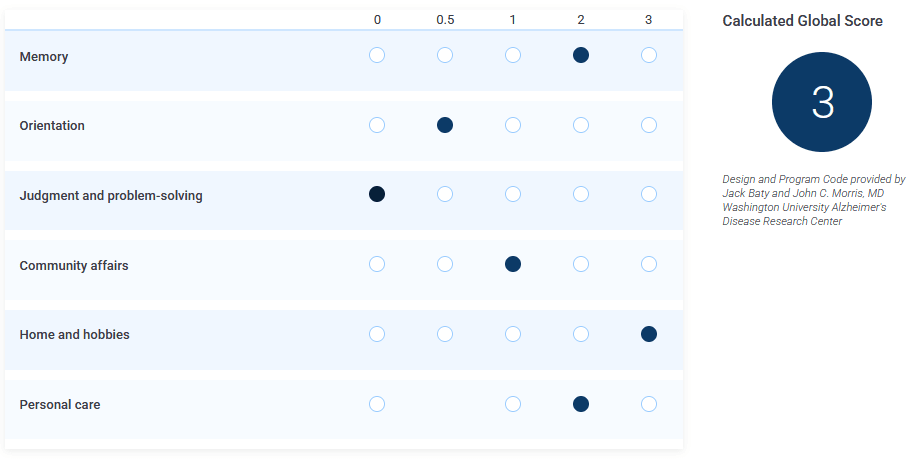
I'm not making this up, you can try it yourself.
And yes, the scale is supposed to be linear[13] and a higher score is supposed to indicate worse symptoms:
CDR Global Score interpretation
0: No dementia
0.5: Questionable dementia
1: Mild cognitive impairment (MCI)
2: Moderate cognitive impairment
3: Severe cognitive impairment
One of my coworkers contacted the publishers of the CDR to point out the inconsistencies and they said (paraphrased): "Yes we know but those edge cases don't come up in real life".
Why not use a consistent scoring method rather than a demonstrably inconsistent one?
To be fair to those using CDR in their studies, in my experience they typically use the sum of the sub-scores[14] in their analysis rather than the arbitrarily algorithmically generated Global Score. So I suppose they do prefer to use more consistent measures.
Nevertheless, when using an Official Instrument, all instances are typically required to implement every part of the instrument, even if everyone involved knows they don't plan on using a particular part of it.
While ensuring inter-study instrument consistency is of course important, surely it's not too much to ask for widely used instruments to only include things that are both useful and well designed? So as to not waste hours of coders' time calculating the result of an algorithm that everyone knows will not be used anyway?[15]
Pure speculation: Maybe the publishers are attached to the algorithm because they put so much work into it, or perhaps because they collect licensing royalties from anyone using it? (Although even without it they would still get royalties from the rest of the instrument)
These observations of mine are only the tip of the iceberg, there are many more I didn't write down, and I'm sure others with more experience or different perspectives could add to or edit this list.
I'm not even close to the first person to notice these issues. What are the factors keeping them and the rest of their reference class from being solved?
I don't really have any answer beyond speculation, but perhaps with this small window of info some of you will have better insights than me.
- ^
Contract Research Organization
- ^
Typically these are selected for unambiguous patent eligibility, i.e. novel synthetic compounds.
While substances found in nature can also have clinical usefulness (as they ostensibly evolved for a reason and organisms tend to have correlated needs) they are also more difficult to secure legal exclusivity of production or claim patent violation if you can just stick a fish in a blender and get the same thing.
Thus the space of things-with-potential-clinical-usefulness is less-than-optimally explored due to perverse incentive structures, which should surprise ~0 people reading this. - ^
Though it is likely similar problems also occur in animal trials, I have no direct experience with those.
- ^
In terms of having a regulatory stamp of approval so it can be marketed
- ^
I've never seen this type of attitude among rocket scientists, but wouldn't it be surreal?
- ^
Yes, some cases exist where through great effort you can map free text data to a more structured form. This is exactly the sort of inefficiency I'm trying to fix
- ^
Need I mention that we add new points of failure any time it passes through human hands?
- ^
At this point my expectations are so low I'm mildly surprised if they have a usable API at all
- ^
They typically have some sort of backup in place, but rarely accessible through the user interface so one has to contact support and wait a couple business days. If only they implemented git-like version control
- ^
It would be so nice to be able to build a phase 3 study by using the phase 2 forms and settings as a starting point. They usually want to do very similar things and keep as much parity as possible between them. Par for the course is making the study builders add everything manually. Again.
- ^
Seriously, it seems like they are mortally afraid of giving study builders a sandboxed Python or Javascript instance to use.
- ^
Perhaps because of regulatory momentum
- ^
Swapping steps between 0.5 and 1 mid-scale is approximately linear. Just like the CDR Global Scoring is approximately consistent
- ^
Referred to as CDR Sum of Boxes.
- ^
I'm a bit salty about this still. Few things are quite as demotivating as spending time working on functionally irrelevant box-checking rituals to conform to arbitrary requirements.
Is it too much to ask for work to be focused on usefully productive things?
I would not be happy collecting a paycheck for spinning my wheels accomplishing merely the symbolic representation of work. I want my effort to accomplish actual progress toward object-level values.
Discuss
