


Large language models (LLMs) use extensive computational resources to process and generate human-like text. One emerging technique to enhance reasoning capabilities in LLMs is test-time scaling, which dynamically allocates computational resources during inference. This approach aims to improve the accuracy of responses by refining the model’s reasoning process. As models like OpenAI’s o1 series introduced test-time scaling, researchers sought to understand whether longer reasoning chains led to improved performance or if alternative strategies could yield better results.
Scaling reasoning in AI models poses a significant challenge, especially in cases where extended chains of thought do not necessarily translate to better outcomes. The assumption that increasing the length of responses enhances accuracy is being questioned by researchers, who have found that longer explanations can introduce inconsistencies. Errors accumulate over extended reasoning chains, and models often make unnecessary self-revisions, leading to performance degradation rather than improvement. If test-time scaling is to be an effective solution, it must balance reasoning depth with accuracy, ensuring that computational resources are used efficiently without diminishing the model’s effectiveness.
Current approaches to test-time scaling primarily fall into sequential and parallel categories. Sequential scaling extends the chain-of-thought (CoT) during inference, expecting that more extended reasoning will lead to improved accuracy. However, studies on models like QwQ, Deepseek-R1 (R1), and LIMO indicate that extending CoTs does not consistently yield better results. These models frequently use self-revision, introducing redundant computations that degrade performance. In contrast, parallel scaling generates multiple solutions simultaneously and selects the best one based on a predetermined criterion. Comparative analyses suggest that parallel scaling is more effective in maintaining accuracy and efficiency.
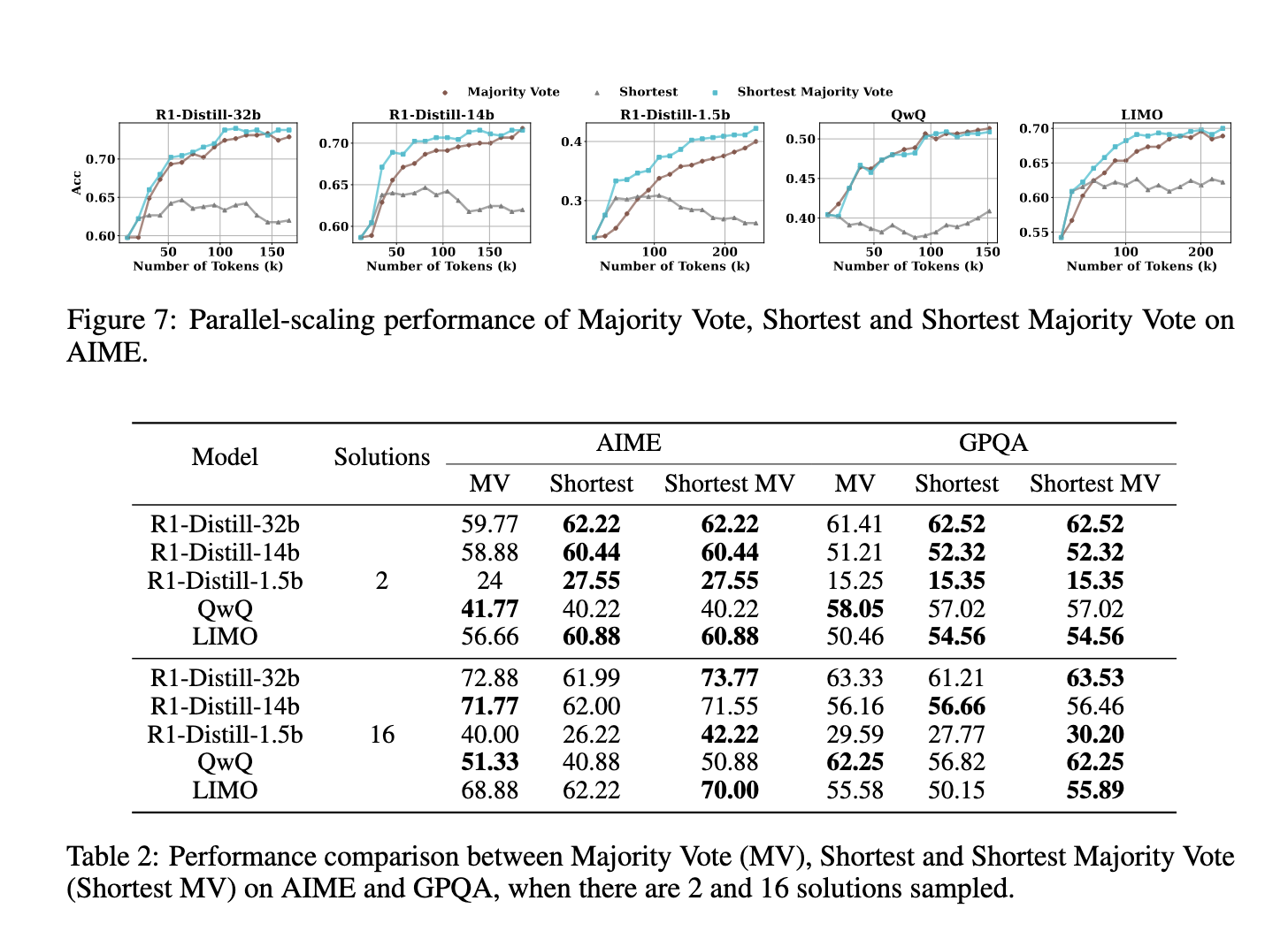
Researchers from Fudan University and the Shanghai AI Laboratory introduced an innovative method called “Shortest Majority Vote” to address the limitations of sequential scaling. This method optimizes test-time scaling by leveraging parallel computation while factoring in solution length. The primary insight behind this approach is that shorter solutions tend to be more accurate than longer ones, as they contain fewer unnecessary self-revisions. By incorporating solution length into the majority voting process, this method enhances models’ performance by prioritizing frequent and concise answers.
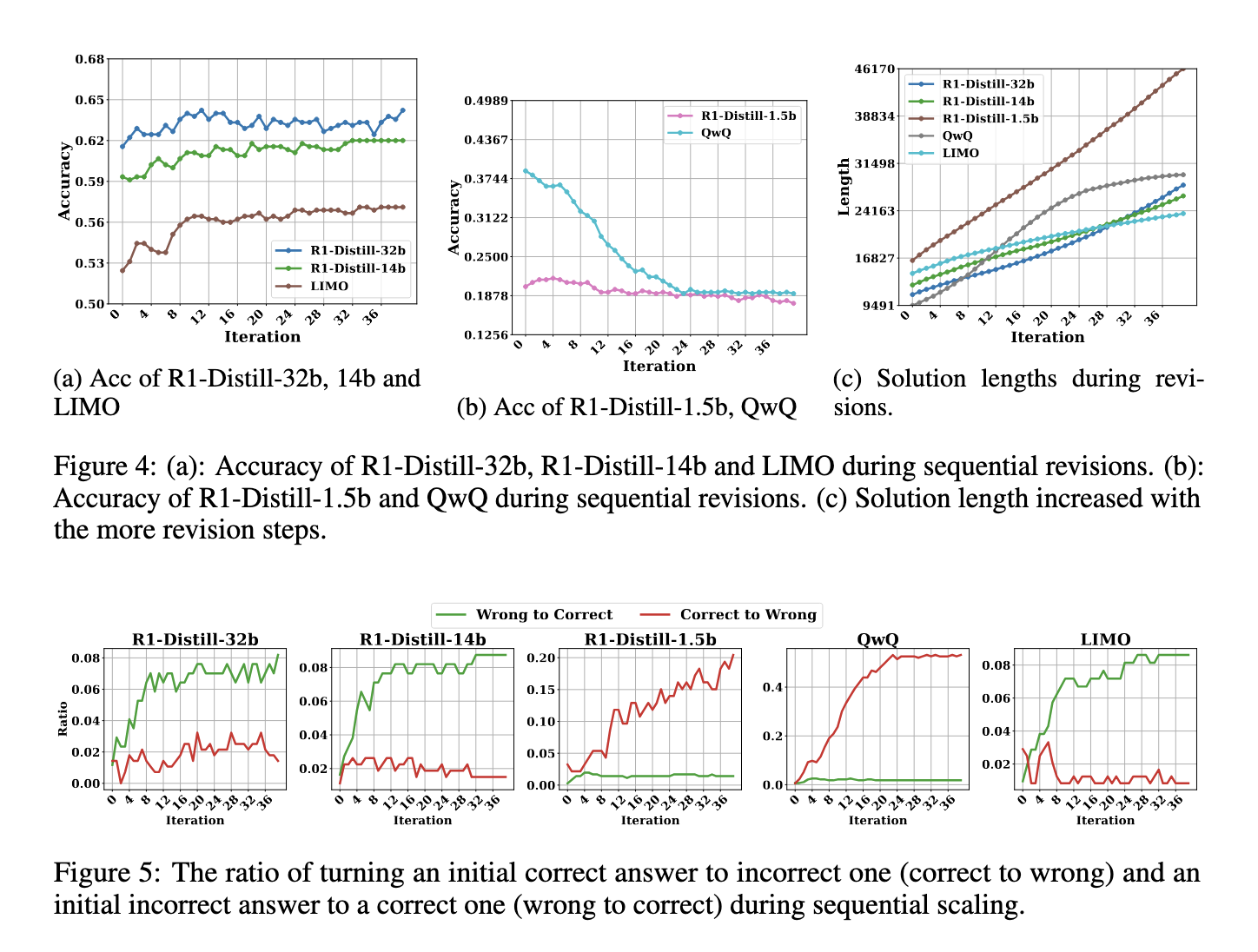
The proposed method modifies traditional majority voting by considering the number and length of solutions. Conventional majority voting selects the most frequently occurring answer among generated solutions, whereas Shortest Majority Vote assigns higher priority to answers that appear often but are also shorter. The reasoning behind this approach is that longer solutions tend to introduce more errors due to excessive self-revisions. Researchers found that QwQ, R1, and LIMO generate increasingly longer responses when prompted to refine their solutions, often leading to lower accuracy. The proposed method aims to filter out unnecessary extensions and prioritize more precise answers by integrating length as a criterion.
Experimental evaluations demonstrated that Shortest Majority Vote method significantly outperformed traditional majority voting across multiple benchmarks. On the AIME dataset, models incorporating this technique showed an increase in accuracy compared to existing test-time scaling approaches. For instance, accuracy improvements were observed in R1-Distill-32b, which reached 72.88% compared to conventional methods. Similarly, QwQ and LIMO also exhibited enhanced performance, particularly in cases where extended reasoning chains previously led to inconsistencies. These findings suggest that the assumption that longer solutions always yield better results is flawed. Instead, a structured and efficient approach that prioritizes conciseness can lead to superior performance.
The results also revealed that sequential scaling suffers from diminishing returns. While initial revisions may contribute to improved responses, excessive revisions often introduce errors rather than correcting them. In particular, models like QwQ and R1-Distill-1.5b tended to change correct answers into incorrect ones rather than improving accuracy. This phenomenon further highlights the limitations of sequential scaling, reinforcing the argument that a more structured approach, such as Shortest Majority Vote, is necessary for optimizing test-time scaling.
The research underscores the need to rethink how test-time scaling is applied in large language models. Rather than assuming that extending reasoning chains leads to better accuracy, the findings demonstrate that prioritizing concise, high-quality solutions through parallel scaling is a more effective strategy. The introduction of Shortest Majority Vote provides a practical and empirically validated improvement over existing methods, offering a refined approach to optimizing computational efficiency in LLMs. By focusing on structured reasoning rather than excessive self-revision, this method paves the way for more reliable and accurate AI-driven decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post This AI Paper Introduces ‘Shortest Majority Vote’: An Improved Parallel Scaling Method for Enhancing Test-Time Performance in Large Language Models appeared first on MarkTechPost.
