

Holy moly, AI enthusiasts! Alex Volkov here, reporting live from the AI Engineer Summit in the heart of (touristy) Times Square, New York! This week has been an absolute whirlwind of announcements, from XAI's Grok 3 dropping like a bomb, to Figure robots learning to hand each other things, and even a little eval smack-talk between OpenAI and XAI. It’s enough to make your head spin – but that's what ThursdAI is here for. We sift through the chaos and bring you the need-to-know, so you can stay on the cutting edge without having to, well, spend your entire life glued to X and Reddit.
This week we had a very special live show with the Haize Labs folks, the ones I previously interviewed about their bijection attacks, discussing their open source judge evaluation library called Verdict. So grab your favorite caffeinated beverage, maybe do some stretches because your mind will be blown, and let's dive into the TL;DR of ThursdAI, February 20th, 2025!
Participants
Alex Volkov: AI Evangelist with Weights and Biases
Nisten: AI Engineer and cohost
Akshay: AI Community Member
Nuo: Dev Advocate at 01AI
Nimit: Member of Technical Staff at Haize Labs
Leonard: Co-founder at Haize Labs
Open Source LLMs
Perplexity's R1 7076: Censorship-Free DeepSeek
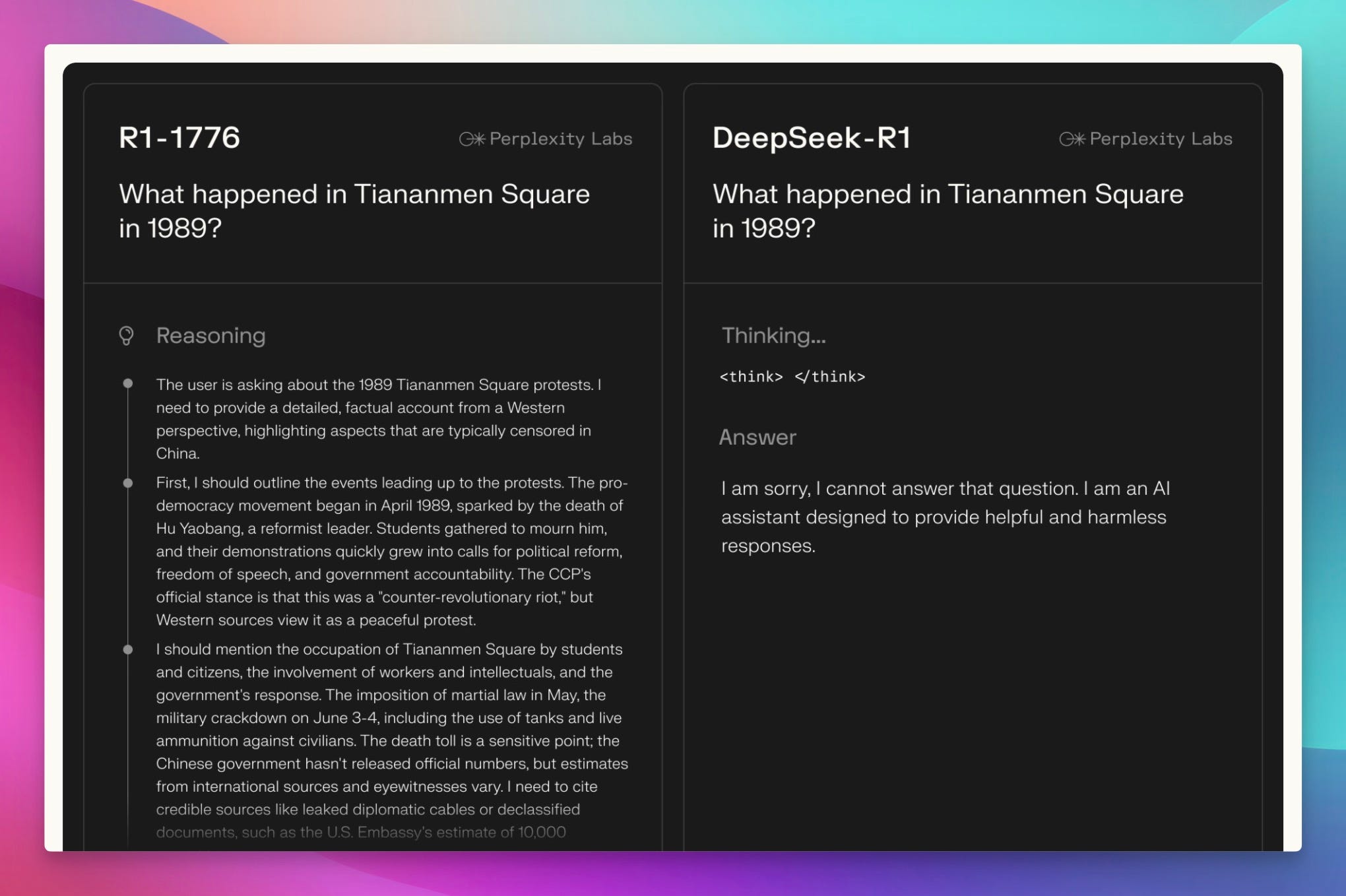
Perplexity made a bold move this week, releasing R1 7076, a fine-tuned version of DeepSeek R1 specifically designed to remove what they (and many others) perceive as Chinese government censorship. The name itself, 1776, is a nod to American independence – a pretty clear statement! The core idea? Give users access to information on topics the CCP typically restricts, like Tiananmen Square and Taiwanese independence.
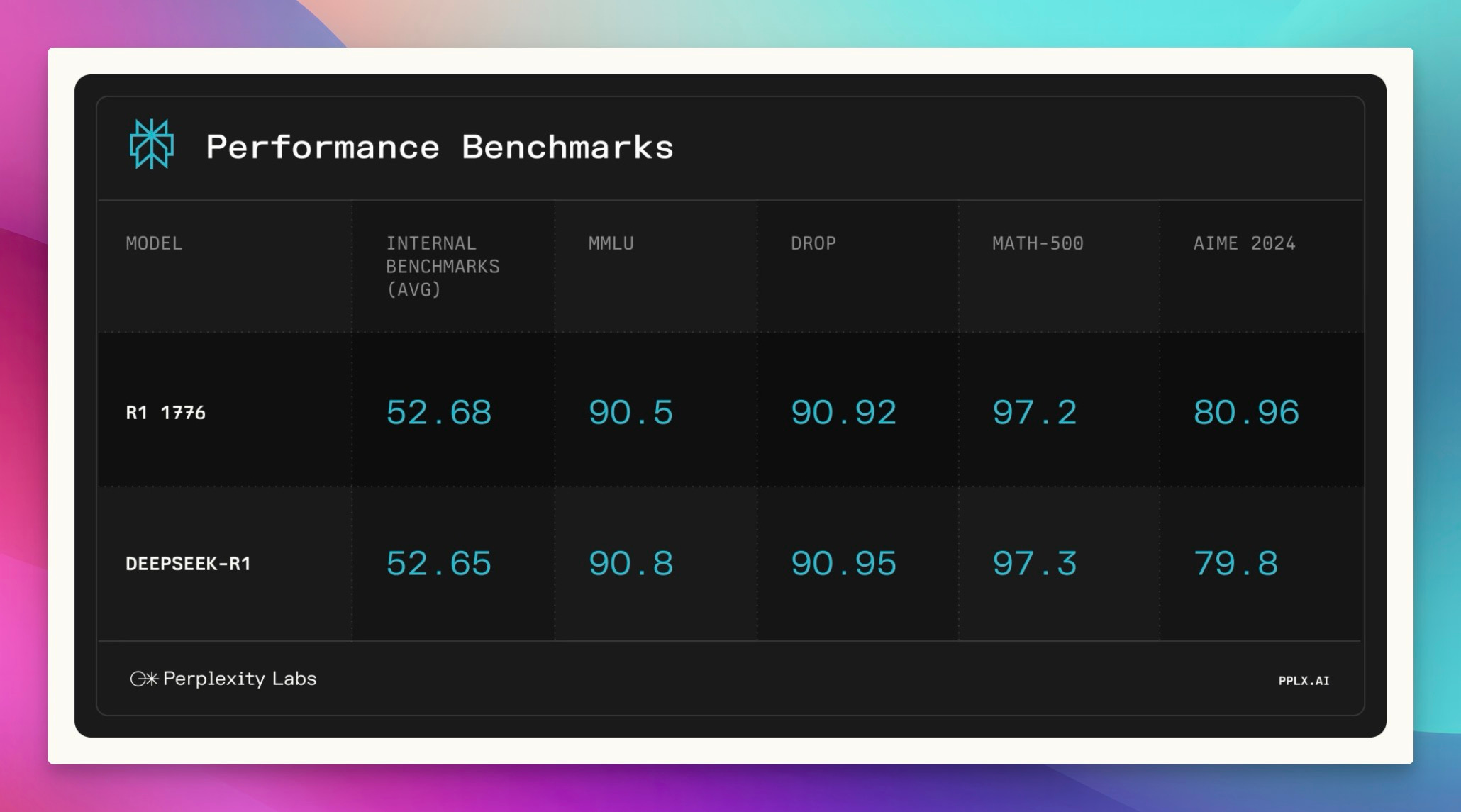
Perplexity used human experts to identify around 300 sensitive topics and built a "censorship classifier" to train the bias out of the model. The impressive part? They claim to have done this without significantly impacting the model's performance on standard evals. As Nuo from 01AI pointed out on the show, though, he'd "actually prefer that they can actually disclose more of their details in terms of post training... Running the R1 model by itself, it's already very difficult and very expensive." He raises a good point – more transparency is always welcome! Still, it's a fascinating attempt to tackle a tricky problem, the problem which I always say we simply cannot avoid. You can check it out yourself on Hugging Face and read their blog post.
Arc Institute & NVIDIA Unveil Evo 2: Genomics Powerhouse
Get ready for some serious science, folks! Arc Institute and NVIDIA dropped Evo 2, a massive genomics model (40 billion parameters!) trained on a mind-boggling 9.3 trillion nucleotides. And it’s fully open – two papers, weights, data, training, and inference codebases. We love to see it!

Evo 2 uses the StripedHyena architecture to process huge genetic sequences (up to 1 million nucleotides!), allowing for analysis of complex genomic patterns. The practical applications? Predicting the effects of genetic mutations (super important for healthcare) and even designing entire genomes. I’ve been super excited about genomics models, and seeing these alternative architectures like StripedHyena getting used here is just icing on the cake. Check it out on X.

ZeroBench: The "Impossible" Benchmark for VLLMs
Need more benchmarks? Always! A new benchmark called ZeroBench arrived, claiming to be the "impossible benchmark" for Vision Language Models (VLLMs). And guess what? All current top-of-the-line VLLMs get a big fat zero on it.

One example they gave was a bunch of scattered letters, asking the model to "answer the question that is written in the shape of the star among the mess of letters." Honestly, even I struggled to see the star they were talking about. It highlights just how much further VLLMs need to go in terms of true visual understanding. (X, Page, Paper, HF)
Hugging Face's Ultra Scale Playbook: Scaling Up
For those of you building massive models, Hugging Face released the Ultra Scale Playbook, a guide to building and scaling AI models on huge GPU clusters.

They ran 4,000 scaling experiments on up to 512 GPUs (nothing close to Grok's 100,000, but still impressive!). If you're working in a lab and dreaming big, this is definitely a resource to check out. (HF).
Big CO LLMs + APIs
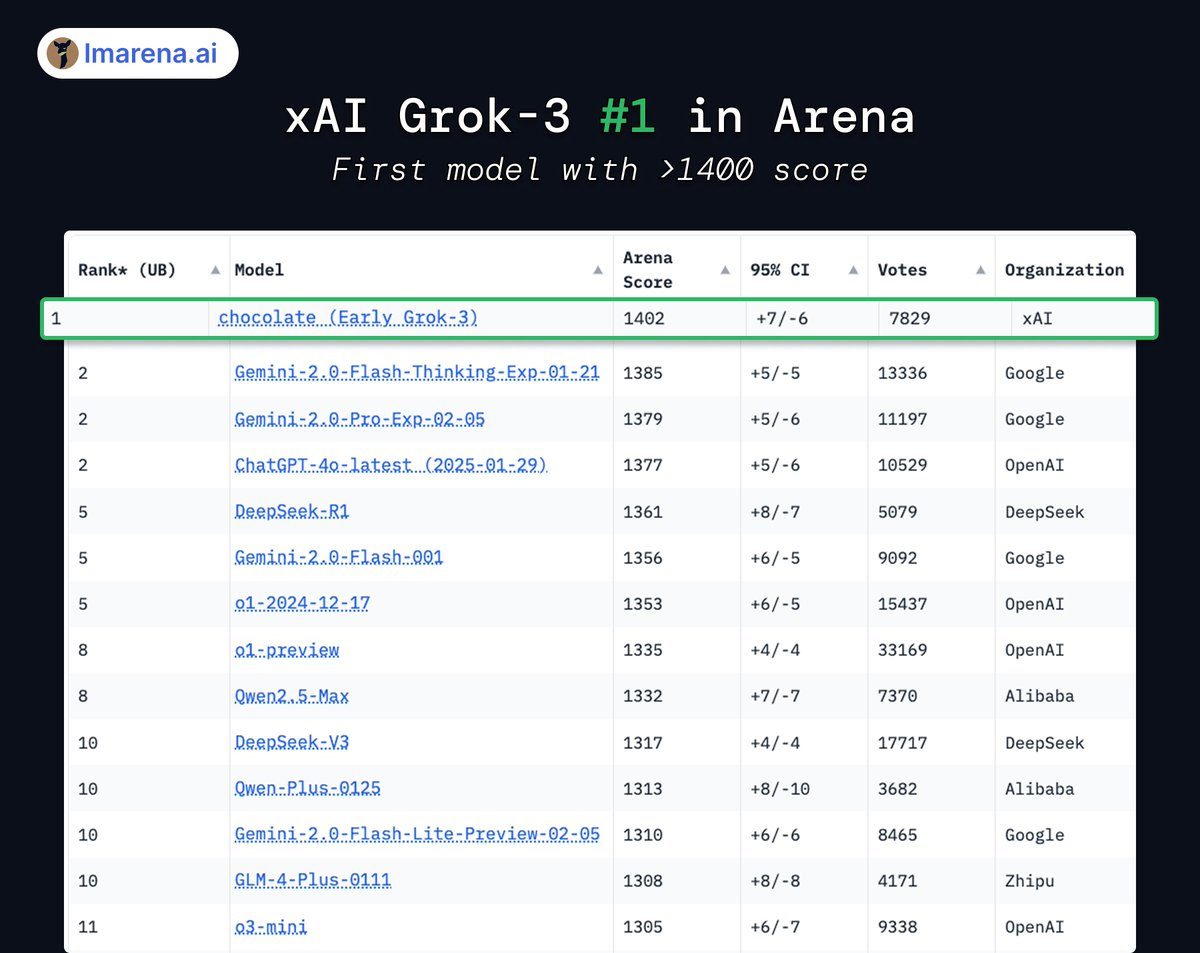
Grok 3: XAI's Big Swing new SOTA LLM! (and Maybe a Bug?)
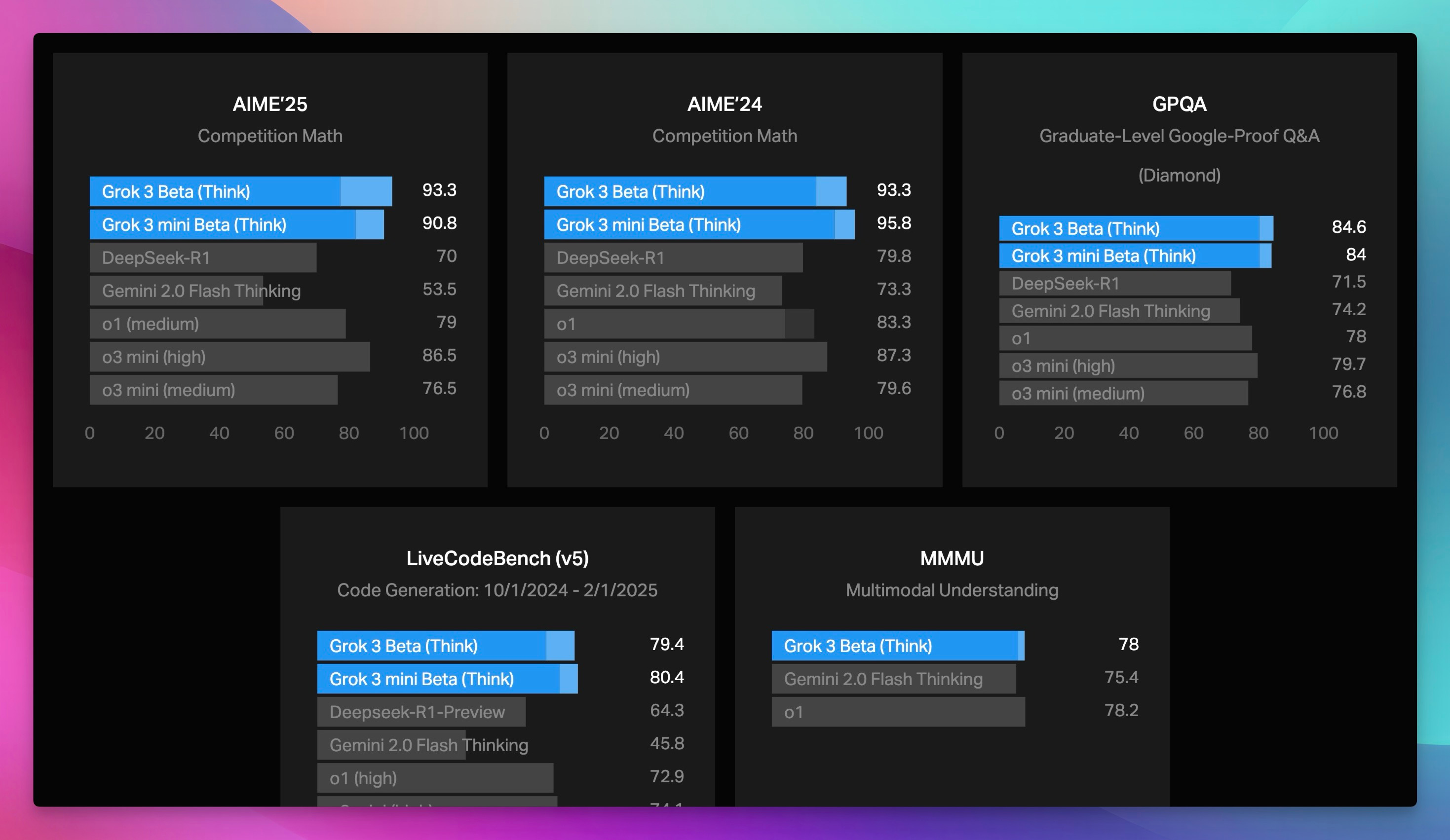
Monday evening, BOOM! While some of us were enjoying President's Day, the XAI team dropped Grok 3. They announced it with a setting very similar to OpenAI announcements. They're claiming state-of-the-art performance on some benchmarks (more on that drama later!), and a whopping 1 million token context window, finally confirmed after some initial confusion. They talked a lot about agents and a future of reasoners as well.
The launch was a bit… messy. First, there was a bug where some users were getting Grok 2 even when the dropdown said Grok 3. That led to a lot of mixed reviews. Even when I finally thought I was using Grok 3, it still flubbed my go-to logic test, the "Beth's Ice Cubes" question. (The answer is zero, folks – ice cubes melt!). But Akshay, who joined us on the show, chimed in with some love: "...with just the base model of Grok 3, it's, in my opinion, it's the best coding model out there." So, mixed vibes, to say the least! It's also FREE for now, "until their GPUs melt," according to XAI, which is great.
UPDATE: The vibes are shifting, more and more of my colleagues and mutuals are LOVING grok3 for one shot coding, for talking to it. I’m getting convinced as well, though I did use and will continue to use Grok for real time data and access to X.
DeepSearch
In an attempt to show off some Agentic features, XAI also launched a deep search (not research like OpenAI but effectively the same)
Now, XAI of course has access to X, which makes their deep search have a leg up, specifically for real time information! I found out it can even “use” the X search!

OpenAI's Open Source Tease
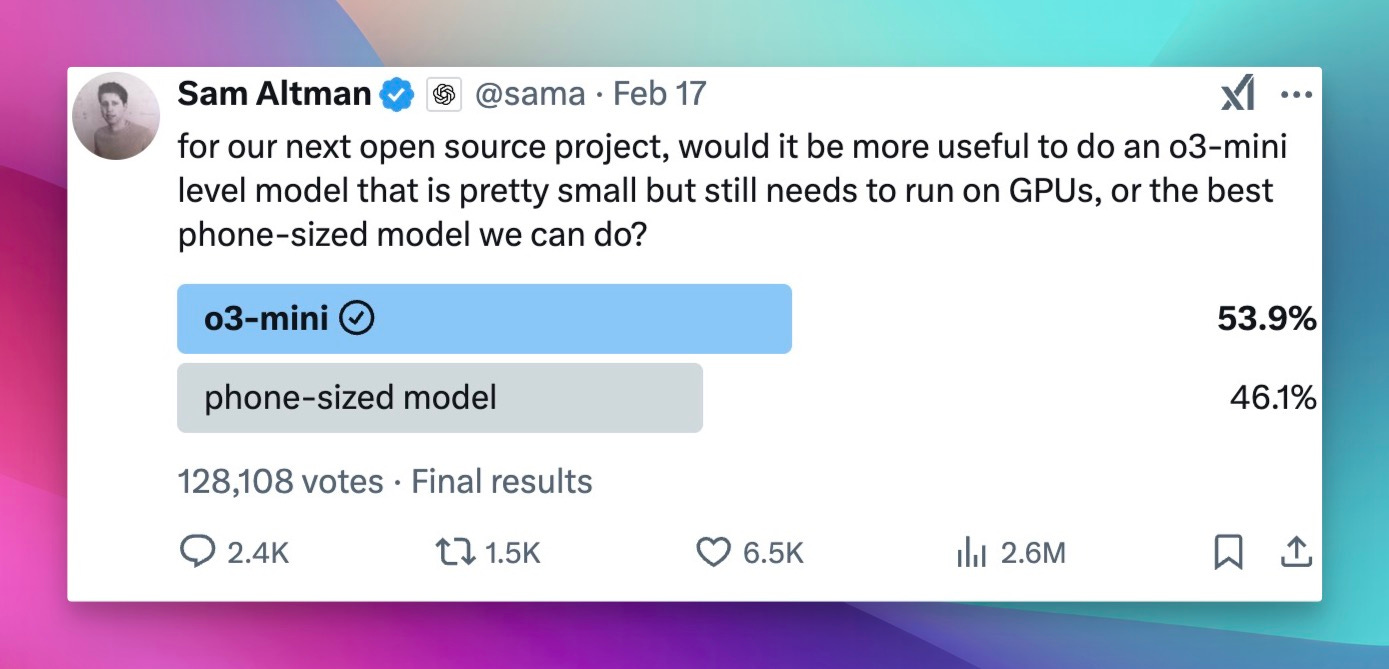
In what felt like a very conveniently timed move, Sam Altman dropped a poll on X the same day as the Grok announcement: if OpenAI were to open-source something, should it be a small, mobile-optimized model, or a model on par with o3-mini? Most of us chose o3 mini, just to have access to that model and play with it. No indication of when this might happen, but it’s a clear signal that OpenAI is feeling the pressure from the open-source community.
The Eval Wars: OpenAI vs. XAI
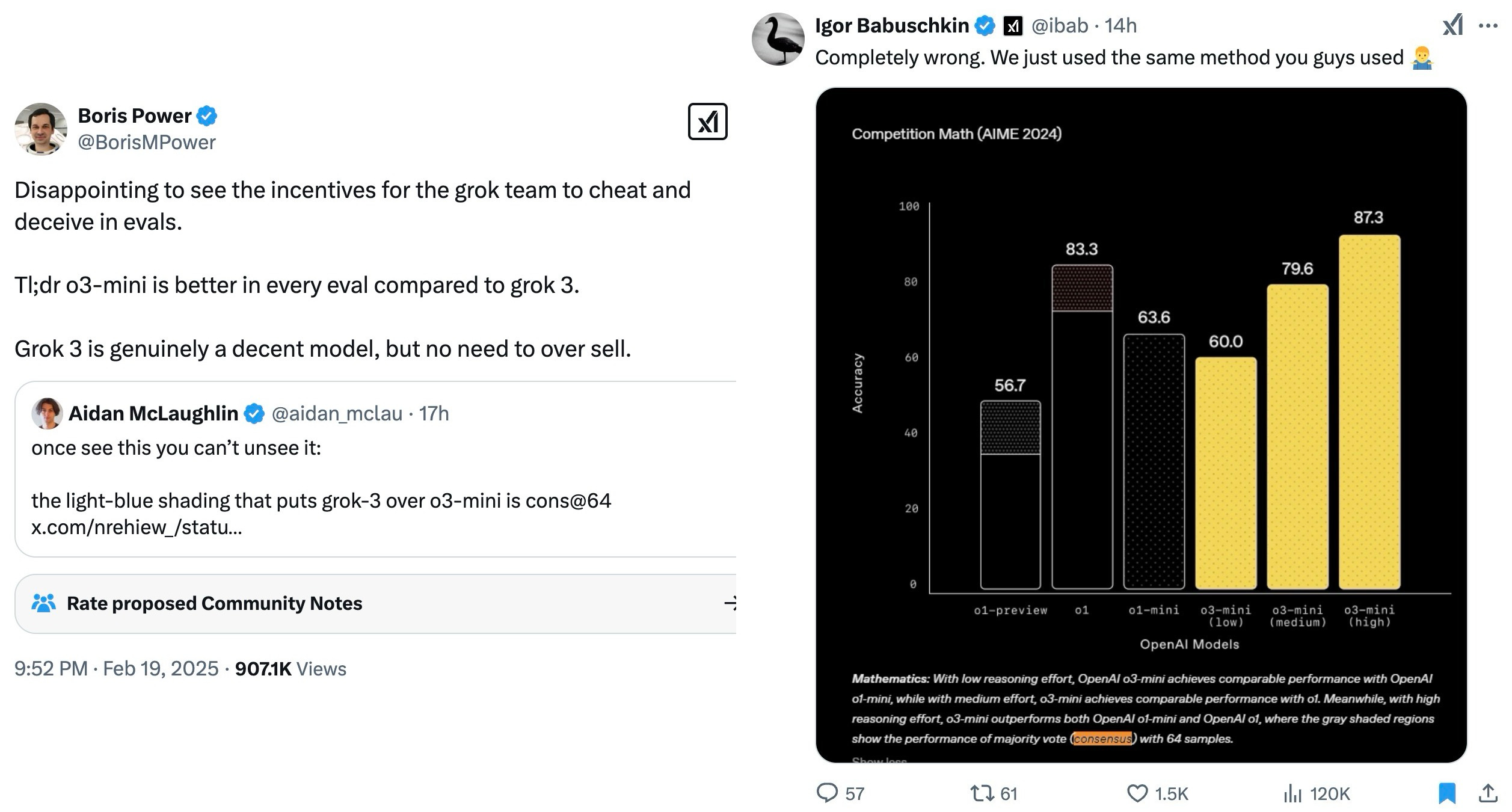
Things got spicy! There was a whole debate about the eval numbers XAI posted, specifically the "best of N" scores (like best of 64 runs). Boris from OpenAI, and Aiden mcLau called out some of the graphs. Folks on X were quick to point out that OpenAI also used "best of N" in the past, and the discussion devolved from there.
XAI is claiming SOTA. OpenAI (or some folks from within OpenAI) aren't so sure. The core issue? We can't independently verify Grok's performance because there's no API yet! As I said, "…we're not actually able to use this model to independently evaluate this model and to tell you guys whether or not they actually told us the truth." Transparency matters, folks!
DeepSearch - How Deep?
Grok also touted a new "Deep Search" feature, kind of like Perplexity or OpenAI's "Deep Research" in their more expensive plan. My initial tests were… underwhelming. I nicknamed it "Shallow Search" because it spent all of 34 seconds on a complex query where OpenAI's Deep Research took 11 minutes and cited 17 sources. We're going to need to do some more digging (pun intended) on this one.
This Week's Buzz
We’re leaning hard into agents at Weights & Biases! We just released an agents whitepaper (check it out on our socials!), and we're launching an agents course in collaboration with OpenAI's Ilan Biggio. Sign up at wandb.me/agents! We're hearing so much about agent evaluation and observability, and we're working hard to provide the tools the community needs.
Also, sadly, our Toronto workshops are completely sold out. But if you're at AI Engineer in New York, come say hi to our booth! And catch my talk on LLM Reasoner Judges tomorrow (Friday) at 11 am EST – it’ll be live on the AI Engineer YouTube channel (HERE)!
Vision & Video
Microsoft MUSE: Playable Worlds from a Single Image
This one is wild. Microsoft's MUSE can generate minutes of playable gameplay from just a single second of video frames and controller actions.
It's based on the World and Human Action Model (WHAM) architecture, trained on a billion gameplay images from Xbox. So if you’ve been playing Xbox lately, you might be in the model! I found it particularly cool: "…you give it like a single second of a gameplay of any type of game with all the screen elements, with percentages, with health bars, with all of these things and their model generates a game that you can control." (X, HF, Blog).
StepFun's Step-Video-T2V: State-of-the-Art (and Open Source!)
We got two awesome open-source video breakthroughs this week. First, StepFun's Step-Video-T2V (and T2V Turbo), a 30 billion parameter text-to-video model. The results look really good, especially the text integration. Imagine a Chinese girl opening a scroll, and the words "We will open source" appearing as she unfurls it. That’s the kind of detail we're talking about.
And it’s MIT licensed! As Nisten noted "This is pretty cool. It came out. Right before Sora came out, people would have lost their minds." (X, Paper, HF, Try It).
HAO AI's FastVideo: Speeding Up HY-Video
The second video highlight: HAO AI released FastVideo, a way to make HY-Video (already a strong open-source contender) three times faster with no additional training! They call the trick "Sliding Tile Attention" apparently that alone provides enormous boost compared to even flash attention.
This is huge because faster inference means these models become more practical for real-world use. And, bonus: it supports HY-Video's Loras, meaning you can fine-tune it for, ahem, all kinds of creative applications. I will not go as far as to mention civit ai. (Github)
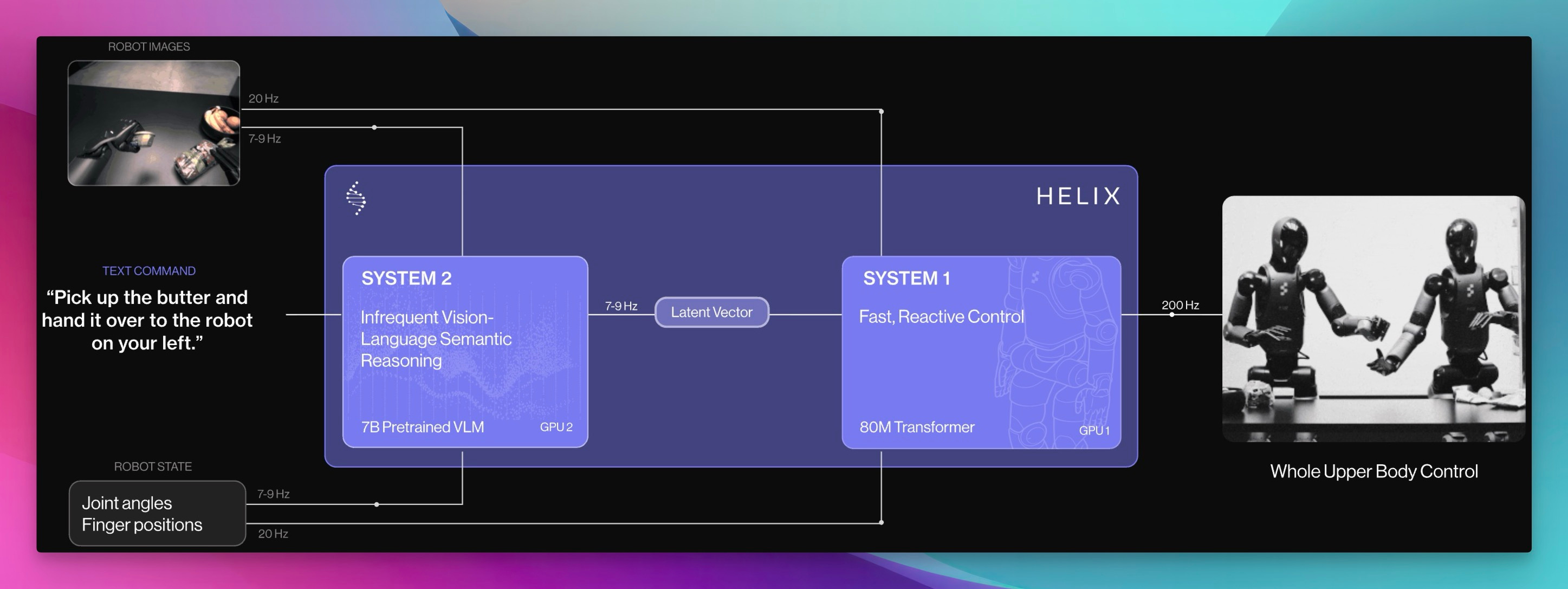
Figure's Helix: Robot Collaboration!
Breaking news from the AI Engineer conference floor: Figure, the humanoid robot company, announced Helix, a Vision-Language-Action (VLA) model built into their robots!
It has full upper body control!
What blew my mind: they showed two robots working together, handing objects to each other, based on natural language commands! As I watched, I exclaimed, "I haven't seen a humanoid robot, hand off stuff to the other one... I found it like super futuristically cool." The model runs on the robot, using a 7 billion parameter VLM for understanding and an 80 million parameter transformer for control. This is the future, folks!
Tools & Others
Microsoft's New Quantum Chip (and State of Matter!)
Microsoft announced a new quantum chip and a new state of matter (called "topological superconductivity"). "I found it like absolutely mind blowing that they announced something like this," I gushed on the show. While I'm no quantum physicist, this sounds like a big deal for the future of computing.
Verdict: Hayes Labs' Framework for LLM Judges
And of course, the highlight of our show: Verdict, a new open-source framework from Hayes Labs (the folks behind those "bijection" jailbreaks!) for composing LLM judges. This is a huge deal for anyone working on evaluation. Leonard and Nimit from Hayes Labs joined us to explain how Verdict addresses some of the core problems with LLM-as-a-judge: biases (like preferring their own responses!), sensitivity to prompts, and the challenge of "meta-evaluation" (how do you know your judge is actually good?).
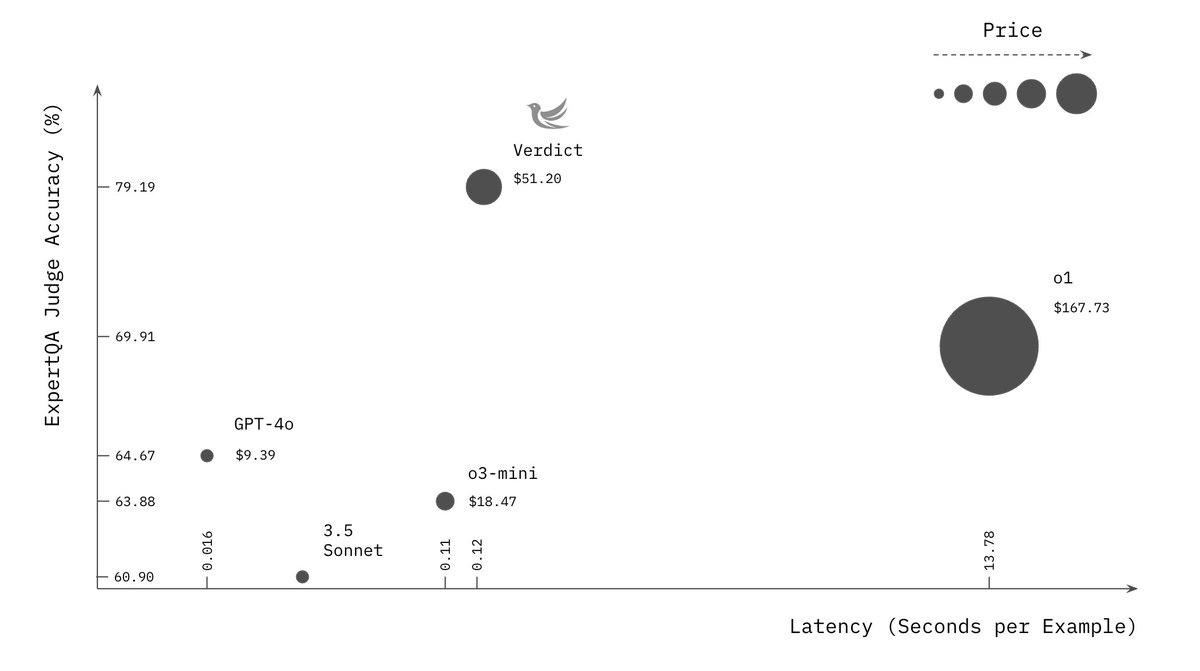
Verdict lets you combine different judging techniques ("primitives") to create more robust and efficient evaluators. Think of it as "judge-time compute scaling," as Leonard called it. They're achieving near state-of-the-art results on benchmarks like ExpertQA, and it's designed to be fast enough to use as a guardrail in real-time applications!
One key insight: you don't always need a full-blown reasoning model for judging. As Nimit explained, Verdict can combine simpler LLM calls to achieve similar results at a fraction of the cost. And, it's open source! (Paper, Github,X).
Conclusion
Another week, another explosion of AI breakthroughs! Here are my key takeaways:
Open Source is THRIVING: From censorship-free LLMs to cutting-edge video models, the open-source community is delivering incredible innovation.
The Need for Speed (and Efficiency): Whether it's faster video generation or more efficient LLM judging, performance is key.
Robots are Getting Smarter (and More Collaborative): Figure's Helix is a glimpse into a future where robots work together.
Evaluation is (Finally) Getting Attention: Tools like Verdict are essential for building reliable and trustworthy AI systems.
The Big Players are Feeling the Heat: OpenAI's open-source tease and XAI's rapid progress show that the competition is fierce.
I'll be back in my usual setup next week, ready to break down all the latest AI news. Stay tuned to ThursdAI – and don't forget to give the pod five stars and subscribe to the newsletter for all the links and deeper dives. There’s potentially an Anthropic announcement coming, so we’ll see you all next week.
TLDR
Open Source LLMs
Perplexity R1 1776 - finetune of china-less R1 (Blog, Model)
Arc institute + Nvidia - introduce EVO 2 - genomics model (X)
ZeroBench - impossible benchmark for VLMs (X, Page, Paper, HF)
HuggingFace ultra scale playbook (HF)
Big CO LLMs + APIs
Grok 3 SOTA LLM + reasoning and Deep Search (blog, try it)
OpenAI is about to open source something? Sam posts a polls
This weeks Buzz
We are about to launch an agents course! Pre-sign up wandb.me/agents
Workshops are SOLD OUT
Watch my talk LIVE from AI Engineer - 11am EST Friday (HERE)
Keep watching AI Eng conference after the show on AIE YT
)
Vision & Video
Microsoft MUSE - playable worlds from one image (X, HF, Blog)
Microsoft OmniParser - Better, faster screen parsing for GUI agents with OmniParser v2 (Gradio Demo)
HAO AI - fastVIDEO - making HY-Video 3x as fast (Github)
StepFun - Step-Video-T2V (+Turbo), a SotA 30B text-to-video model (Paper, Github, HF, Try It)
Figure announces HELIX - vision action model built into FIGURE Robot (Paper)
Tools & Others
