
得益于模型扩展性方面的进展,研究人员能够创建具有前所未有复杂度的模型。
当前的研究趋势是致力于构建更大、更复杂的模型,具有数百/数千亿个参数,但大型语言模型的训练需要海量的训练数据,尤其随着模型参数量的上升,对于优质数据数量的要求也将进一步加大,优质数据量的缺乏极大限制了模型能力的进一步增长。
RedStone是一个高效构建大规模指定领域数据的处理管道,结合了目前主流的数据处理工具以及自定义的处理模块,进一步优化发展而来。
通过RedStone,研究人员构建了包括RedStone-Web、RedStone-Code、RedStone-Math以及RedStone-QA等多个数据集,均在各类任务中超越了目前开源的数据集,能够为大模型的预训练以及后训练提供坚实的数据支撑。

仓库链接:https://github.com/microsoft/RedStone
受限于公司的开源策略,RedStone仅开源了数据索引以及所有处理代码以供社区复现。不过随着受社区关注度的逐渐提高,目前已有社区复现版本的RedStone,依据github中项目描述,该复现的数据集在规模和质量上与RedStone内部数据类似。

图1 RedStone概览图
如图1所示,RedStone以Common Crawl为原始数据源,旨在使用同一的数据处理框架清洗各类目标数据。
RedStone-Web为大规模通用的预训练数据,为模型注入全世界通用知识。
RedStone-Code和RedStone-Math为网络中的各类代码/数学相关数据,与其他开源的code、math类型数据不同的是,网页中的code/math天然具有纯文本和code/math交错的形式,例如代码教程、题目讲解等等。
因此模型可以像人类一样借助code/math上下文中的纯文本来进一步深刻理解code/math。此外RedStone还构建了RedStone-QA,这是一个大规模的QA数据集,最简单直接的方式为模型注入各类知识。
对于RedStone-Web,RedStone认为对于高质量数据的定义至关重要,早期社区认为文本的流畅度等指标代表了数据的质量,近期越来越多研究人员认为含有教育意义的数据代表了高质量数据。
RedStone则是在其中找了一个平衡点,包含知识且文本流畅的,被定义为高质量数据。其中知识可以是任何形式的,只要其中包含的内容可以让模型对世界的认识得到进一步发展。
因此在RedStone-web的构建上,主要处理框架参考了refinedweb和redpajama,但删除了原有的过滤模块,使用新构建的过滤系统,最终获得了总共3.1T token的高质量通用预训练数据。各个其各个步骤以及对应的数据量如图2所示。
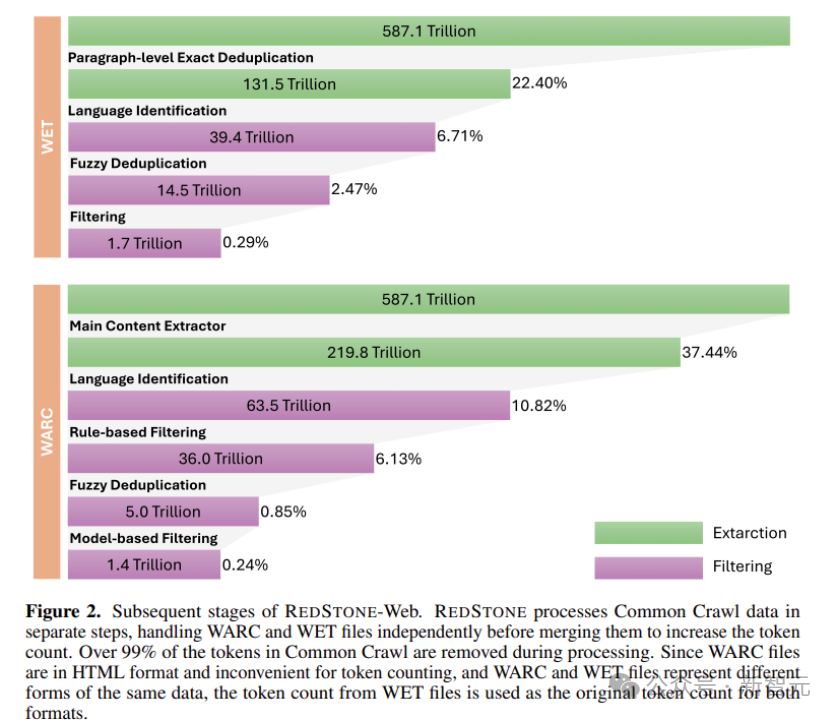
图2 RedStone-Web处理步骤
除了RedStone-Web这一通用领域的高质量数据集以外,RedStone认为网络是一个蕴含丰富宝藏的矿藏之地,足以挖掘各类在通用领域之外被遗漏的各类数据(例如对于RedStone-Web而言有些页面整体质量不高,但其中的某个片段在特定领域属于高质量),随后构建了RedStone-Code、RedStone-Math以及RedStone-QA等专有数据。
其核心仍然是过滤,RedStone提出了多层过滤系统,分别对应不同的数据规模。例如采用fasftext对所有网页进行统一快速过滤,随后使用更高性能模型精细过滤以及片段抽取。论文指出RedStone支持构建其他类型的专有数据,只需自定义好过滤器即可。通用领域和特定领域的数据构建代码都已开源。
图3展示了最终各个数据集的规模。
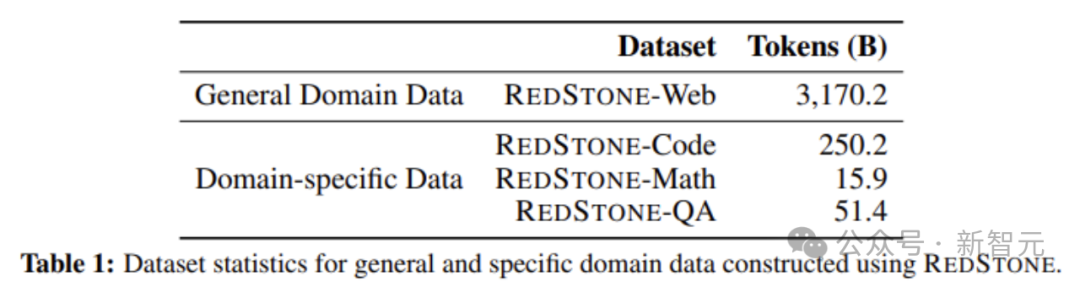
图3 数据集规模
为了验证各个数据集的质量,作者分别使用这些数据对模型进行训练,并与开源数据集比较。如图4所示。RedStone-Web在大部分任务中都显著高于其他所有开源数据集,并且在平均分指标上得到了第一的成绩。这说明RedStone-Web可以显著提升模型性能,并且使得模型的训练更为高效。
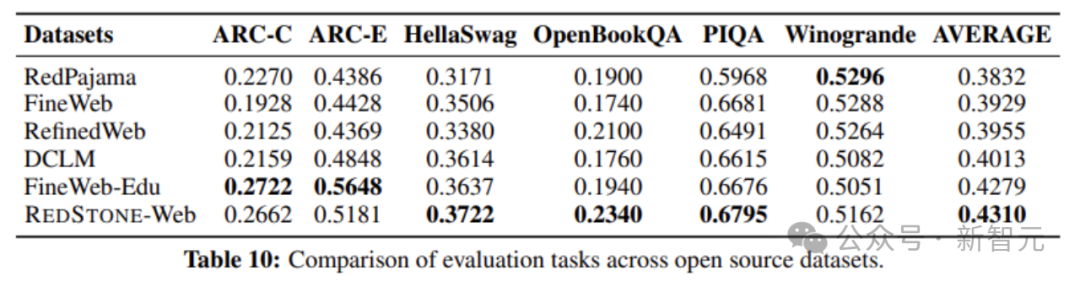
图4 RedStone-Web与开源预训练数据集的比较

图5 RedStone-Code结果展示
考虑到RedStone-Code是来源于网页,数据是文本与代码交错的形式,目前社区中并无此类数据集开源,因此在RedStone-Web基础上增加RedStone-Code进行了实验。
可以看到在并没有显示添加例如github等纯代码的数据情况下,所有数据均只来自网页,RedStone-Code同样可以显著提升模型在代码方面的能力,说明RedStone-Code能够给模型注入足够的代码知识,对于代码数据已经被耗尽的社区来说,这是一个能显著进一步扩展代码领域数据的数据集。
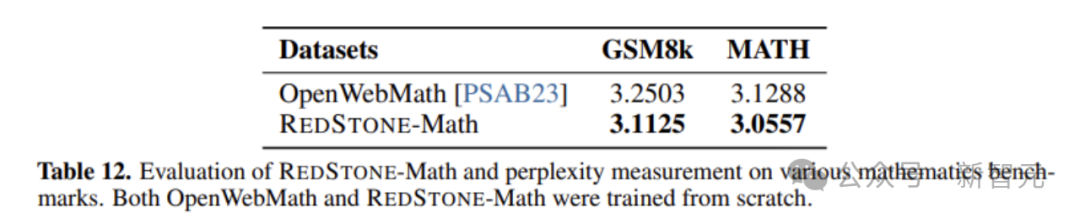
图6 RedStone-Web与开源数据比较
图6展示了RedStone-Math与社区开源数据OpenWebMath的比较,结果显示在同样的设置和步数下,RedStone-Math在得分上高于OpenWebMath,尽管OpenWebMath同样来源于网络,但得益于构建了更好的过滤器,最终能够得到更高的数据质量。
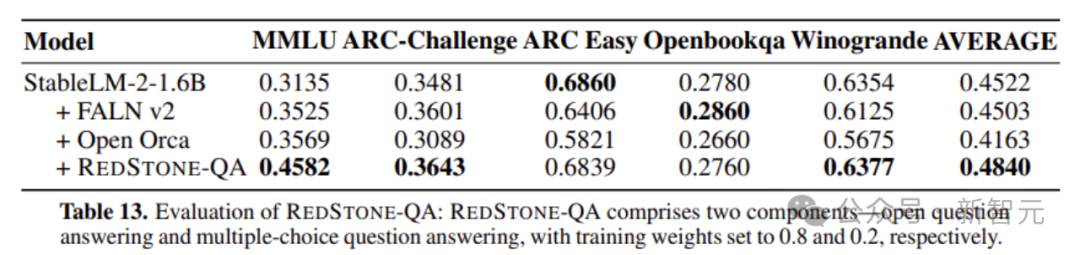
图7 RedStone-QA与开源数据比较
在没有依赖更多的QA数据下,只从网络中爬取QA对,RedStone-QA就可以让模型相对与其他开源QA数据集得到显著的提升(例如MMLU提升了大约10个点),这更说明了网络是一个蕴含丰富宝藏的矿藏之地。
除了以上这些领域外,RedStone的使用几乎不受领域的限制,任何人都可以使用开源代码对特定领域进行爬取。
通过图4至图7的结果可以看到,RedStone构建的数据在LLM预训练以及后训练中展现了有前景的能力,使其成为构建LLM各类训练数据的多功能、实用pipeline。



内容中包含的图片若涉及版权问题,请及时与我们联系删除
