


Whole Slide Image (WSI) classification in digital pathology presents several critical challenges due to the immense size and hierarchical nature of WSIs. WSIs contain billions of pixels and hence direct observation is computationally infeasible. Current strategies based on multiple instance learning (MIL) are effective in performance but considerably dependent on large amounts of bag-level annotated data, whose acquisition is troublesome, particularly in the case of rare diseases. Moreover, current strategies are strongly based on image insights and encounter generalization issues due to differences in the data distribution across hospitals. Recent improvements in Vision-Language Models (VLMs) introduce linguistic prior through large-scale pretraining from image-text pairs; however, current strategies fall short in addressing domain-specific insights related to pathology. Moreover, the computationally expensive nature of pretraining models and their insufficient adaptability with the hierarchical characteristic specific to pathology are additional setbacks. It is essential to transcend these challenges to promote AI-based cancer diagnosis and proper WSI classification.
MIL-based methods generally adopt a three-stage pipeline: patch cropping from WSIs, feature extraction with a pre-trained encoder, and patch-level to slide-level feature aggregation to make predictions. Although these methods are effective for pathology-related tasks like cancer subtyping and staging, their dependency on large annotated datasets and data distribution shift sensitivity renders them less practical to use. VLM-based models like CLIP and BiomedCLIP try to tap into language priors by utilizing large-scale image-text pairs gathered from online databases. These models, however, depend on general, handcrafted text prompts that lack the subtlety of pathological diagnosis. In addition, knowledge transfer from vision-language models to WSIs is inefficient owing to the hierarchical and large-scale nature of WSIs, which demands astronomical computational costs and dataset-specific fine-tuning.
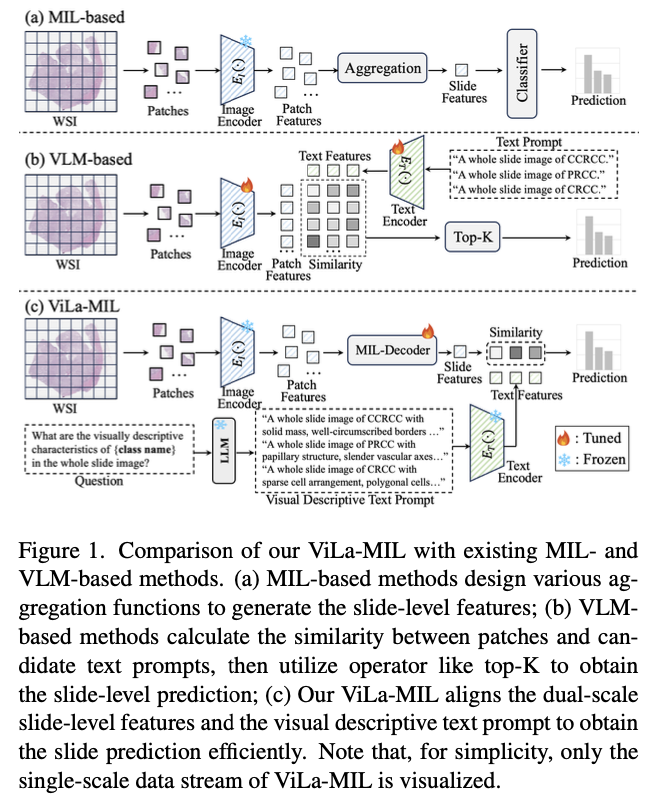
Researchers from Xi’an Jiaotong University, Tencent YouTu Lab, and Institute of High-Performance Computing Singapore introduce a dual-scale vision-language multiple instance learning model capable of efficiently transferring vision-language model knowledge to digital pathology through descriptive text prompts designed specifically for pathology and trainable decoders for image and text branches. In contrast to generic class-name-based prompts for traditional vision-language methods, the model utilizes a frozen large language model to generate domain-specific descriptions at two resolutions. The low-scale prompt highlights global tumor structures, and the high-scale prompt highlights finer cellular details, with improved feature discrimination. A prototype-guided patch decoder progressively accumulates patch features by clustering similar patches into learnable prototype vectors, minimizing computational complexity and improving feature representation. A context-guided text decoder further improves text descriptions by using multi-granular image context, facilitating a more effective fusion of visual and textual modalities.
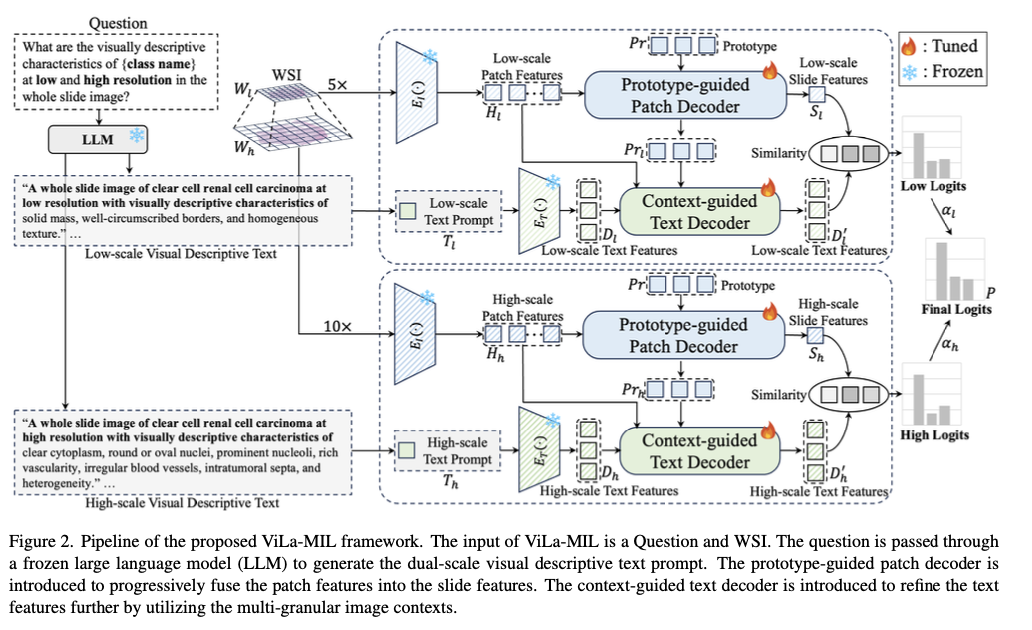
The model proposed relies on CLIP as its underlying model and utilizes several additions to adapt it for pathology tasks. Whole-slide images are patchily segmented at the 5× and 10× magnification levels, while feature extraction uses a frozen ResNet-50 image encoder. A frozen large GPT-3.5 language model is also used to generate class-specific descriptive prompts for two scales with learnable vectors to facilitate effective feature representation. Progressive feature agglomeration is supported using a set of 16 learnable prototype vectors. The patch and prototype multi-granular features also help support the text embeddings, hence improved cross-modal alignment. Optimizing training makes use of the cross-entropy loss with equally weighted low- and high-scale similarity scores for robust classification support.
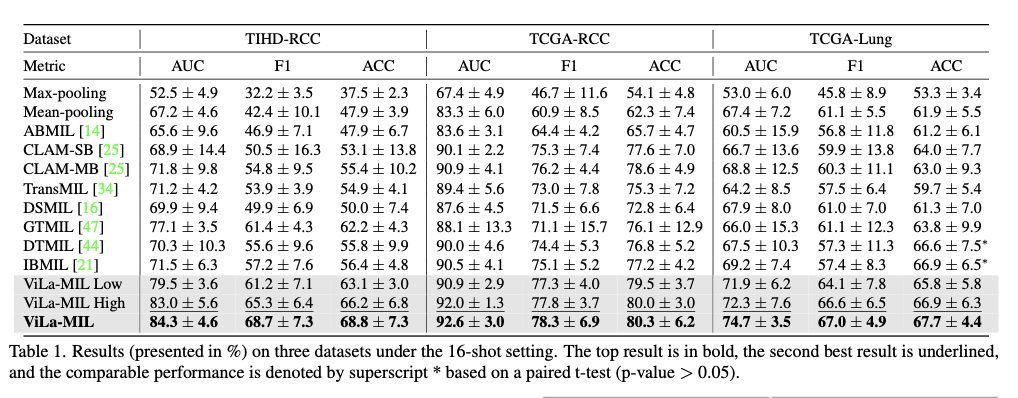
This method demonstrates better performance on various subtyping datasets of cancer significantly outperforming current MIL-based and VLM-based methods in few-shot learning scenarios. The model records impressive gains in AUC, F1 score, and accuracy over three diverse datasets—TIHD-RCC, TCGA-RCC, and TCGA-Lung—demonstrating the model’s solidity in tests executed in both single-center and multi-center setups. In comparison to state-of-the-art approaches, significant gains in classification accuracy are observed with rises of 1.7% to 7.2% in AUC and 2.1% to 7.3% in F1 score. The employment of dual-scale text prompts with a prototype-guided patch decoder and context-guided text decoder aids the framework in its ability to learn effective discriminative morphological patterns despite the presence of few training instances. Moreover, excellent generalization abilities across multiple datasets suggest enhanced adaptability toward domain shift during cross-center testing. These observations demonstrate the merits of fusing vision-language models with pathology-specialized advances toward whole slide image classification.
Through the development of a new dual-scale vision-language learning framework, this research makes a substantial contribution to WSI classification with the utilization of large language models to prompt text and prototype-based feature aggregation. The method enhances few-shot generalization, decreases computational cost, and promotes interpretability, solving core pathology AI challenges. By building on the successful vision-language model transfer to digital pathology, this research is a valuable contribution to cancer diagnosis with AI, with the potential to generalize to other medical image tasks.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post ViLa-MIL: Enhancing Whole Slide Image Classification with Dual-Scale Vision-Language Multiple Instance Learning appeared first on MarkTechPost.
