
Caching for Performance: Virtual Masterclass (Sponsored)
Insider tips for navigating caching strategies and tradeoffs

This masterclass shares pragmatic caching strategies for latency-sensitive use cases. We’ll explore a variety of caching options – how they’re architected, how that impacts their “sweet spot” and tradeoffs, as well as tips for working with them.
After this free 2-hour masterclass, you will know how to:
Decide among common caching approaches for reducing application latency
Understand the architecture decisions behind different caching approaches and how that impacts performance
Measure, monitor, and optimize the performance impact of your caching approach
Spot and diagnose the manifestations of common caching mistakes
This is a great opportunity to learn how caching strategies are evolving and how to best take advantage of them.
Disclaimer: The details in this post have been derived from Instagram Engineering Blog and other sources. All credit for the technical details goes to the Instagram engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Instagram was launched in 2010 by Kevin Systrom and Mike Krieger as a simple photo-sharing app. The app allowed users to instantly upload, edit, and share photos, applying filters that gave images a professional touch. Unlike other social media platforms at the time, Instagram focused exclusively on visual storytelling, making it an instant hit among smartphone users.
The platform's simplicity and mobile-first approach led to rapid adoption. Within just two months, Instagram had gained 1 million users, a milestone that took Facebook nearly a year to achieve. The app grew exponentially, reaching 10 million users in one year and 30 million users by early 2012.
By April 2012, Instagram had reached 50 million users and was attracting serious investment interest. Facebook acquired Instagram for $1 billion, a shocking move at the time, as the company had just 13 employees. However, Mark Zuckerberg saw Instagram’s potential as a mobile-first social network and wanted to integrate it into Facebook’s ecosystem while allowing it to function independently.
At the time of the acquisition, Instagram was still operating on a relatively small-scale infrastructure hosted on Amazon Web Services (AWS). The app was experiencing major scalability challenges, such as server overloads, database scaling issues, and limited engineering resources.
After joining Facebook, Instagram migrated from AWS to Facebook’s data centers, preparing it for its next phase of hypergrowth. Under Facebook’s ownership, Instagram continued to scale at an unprecedented pace. By 2014, it had 300 million users, and by 2018, it had breached the billion-user mark.
To handle billions of daily interactions, Instagram had to adopt advanced scaling strategies, including distributed databases, caching, and multi-region infrastructure. In this article, we’ll look at how Instagram scaled its infrastructure to handle this massive scale.
Instagram’s Early Infrastructure Challenges
When Instagram first launched in 2010, it was a small company with limited engineering resources.
However, with time, Instagram grew into one of the most widely used social media platforms in the world. This rapid increase in user engagement placed an enormous strain on its infrastructure, requiring continuous optimization and scaling efforts.
Some key metrics highlighting Instagram’s scale (in 2017-2018) are as follows:
400 million daily active users that open Instagram multiple times a day, generating billions of interactions.
100 million media uploads per day. Every media file must be optimized for different devices, ensuring smooth playback while minimizing bandwidth usage.
4 billion likes per day where every like generates a database write operation, which must be efficiently managed to avoid overloading storage and query systems
The platform’s rapid growth exposed significant scalability challenges, forcing engineers to adopt temporary solutions to keep the system running. However, as user activity continued to increase exponentially, these short-term fixes became unsustainable, leading to the urgent need for automation and a scalable architecture.
Some challenges faced by Instagram in its early days are as follows:
Manual Server Scaling: In the early days, Instagram’s engineering team manually added servers before weekends to prevent system failures. Traffic spikes were common on Fridays and weekends when user engagement surged due to increased social activity. Engineers would monitor CPU loads and decide if additional servers needed to be provisioned to handle the expected load.
Unreliable Performance Due to Limited Infrastructure: Instagram initially operated on Amazon Web Services (AWS), using a small number of virtual machines. The infrastructure was not optimized for handling sudden surges in traffic, leading to slow response times and occasional outages. The backend services struggled to process requests efficiently, causing delays in content loading and interactions.
Database Overload: The increasing number of users posting photos, liking content, and following accounts placed a heavy burden on Instagram’s relational database. As data volume grew, the read and write operations on the database became slower, affecting the overall performance of the platform. Engineers had to manually optimize queries and shift loads across multiple database replicas, a time-consuming process.
Lack of Automated Monitoring: Since Instagram had a small engineering team, monitoring server performance was done manually, often requiring constant attention to avoid system failures. Engineers used basic dashboards and alerts to detect issues, but there was no real-time system in place to automatically respond to performance problems.
Lack of Load Balancing: Load balancing across multiple servers was not fully automated, leading to uneven traffic distribution and bottlenecks.
Engineering Bottlenecks: Since infrastructure management was largely manual, engineers had to spend significant time scaling and maintaining servers instead of focusing on product development. As the team was small, scaling efforts often delayed feature releases and made it difficult to introduce new functionalities.
The Three Dimensions of Scaling at Instagram
As Instagram’s user base grew exponentially, the company had to develop scalable infrastructure to handle billions of daily interactions.
Scaling is not just about adding more hardware. It also involves optimizing resources and ensuring that the engineering team can operate efficiently. Instagram approached scalability in three key dimensions:
1 - Scaling Out: Expanding Infrastructure with More Servers
Scaling out refers to adding more hardware (servers, storage, and computing power) to handle increased traffic.
Some new strategies were adopted:
Instagram migrated from AWS to Facebook’s data centers, allowing horizontal scaling by distributing the workload across multiple servers. They expanded to multiple geographically distributed data centers, ensuring high availability and redundancy.
Instead of relying on a few powerful machines, Instagram distributed workloads across multiple servers and data centers.
Load balancing systems were implemented to distribute user requests across different data centers.
Instead of a single monolithic database, Instagram adopted a distributed database system, using PostgreSQL and Cassandra for high availability.
Migrating to Facebook’s data centers allowed Instagram to take advantage of Facebook’s existing tools and infrastructure, such as:
TAO: A highly efficient distributed database system for social data.
Scuba: A real-time analytics and monitoring tool for debugging performance issues.
Tupperware: Facebook’s containerized deployment system for managing large-scale applications.
However, the migration was quite challenging. Instagram needed to migrate petabytes of media files, user data, and metadata from AWS to Facebook’s data centers. Instead of a single "big bang" migration, data was incrementally copied and synchronized across both systems to ensure consistency. Facebook’s Haystack storage system was used to optimize media storage and retrieval.
Instagram’s backend services were initially built to run on AWS’s Elastic Compute Cloud (EC2). To optimize performance, these services were re-engineered to run on Facebook’s Tupperware containerization system, allowing for better resource utilization and auto-scaling.
2 - Scaling Up: Optimizing Efficiency of Each Server
Scaling up means improving the performance of existing infrastructure rather than adding more hardware. This involved reducing CPU load, optimizing queries, and using caching mechanisms to maximize server efficiency.
In Instagram’s case, adding more servers was not a sustainable long-term solution due to cost and resource limitations. Each request from a user (loading a feed, liking a post, adding a comment) resulted in multiple database queries, slowing down response times. Inefficient memory usage and unoptimized Python code caused unnecessary resource consumption.
The Instagram engineering team implemented some solutions to deal with these issues:
Optimized database queries by reducing redundant operations and batching requests.
Used Memcached and Cassandra to cache frequently accessed data, reducing direct database queries.
Profiled Python code to identify inefficient functions and replaced them with C++ implementations for better performance.
Improved server memory management, enabling a more efficient use of RAM.
3 - Scaling the Engineering Team
Scaling the engineering team means ensuring that developers can continue to work efficiently as the company grows. This involves better deployment strategies, automation, and minimizing bottlenecks in the development process.
Instagram grew from a small startup to a company with hundreds of engineers, leading to challenges in code management and deployment. More engineers working on the same codebase increased merge conflicts, regressions, and debugging complexity.
To handle these problems, the Instagram engineering team embraced continuous deployment. Instead of periodic large updates, they shifted to a rolling release model, deploying code changes 40+ times per day. This ensured that small updates could be tested, monitored, and rolled back quickly if needed.
New features were deployed gradually to a small subset of users before being rolled out globally. Engineers could monitor performance metrics and detect bugs early, preventing widespread failures. They also implemented real-time monitoring tools to detect performance regressions.
Instagram’s Backend Architecture
As Instagram grew into a platform handling billions of interactions daily, it required a robust, scalable, and efficient backend architecture.
The system needed to process a huge number of user requests, including media uploads, likes, comments, and notifications while maintaining high availability and low latency. The main components of the backend architecture are as follows:
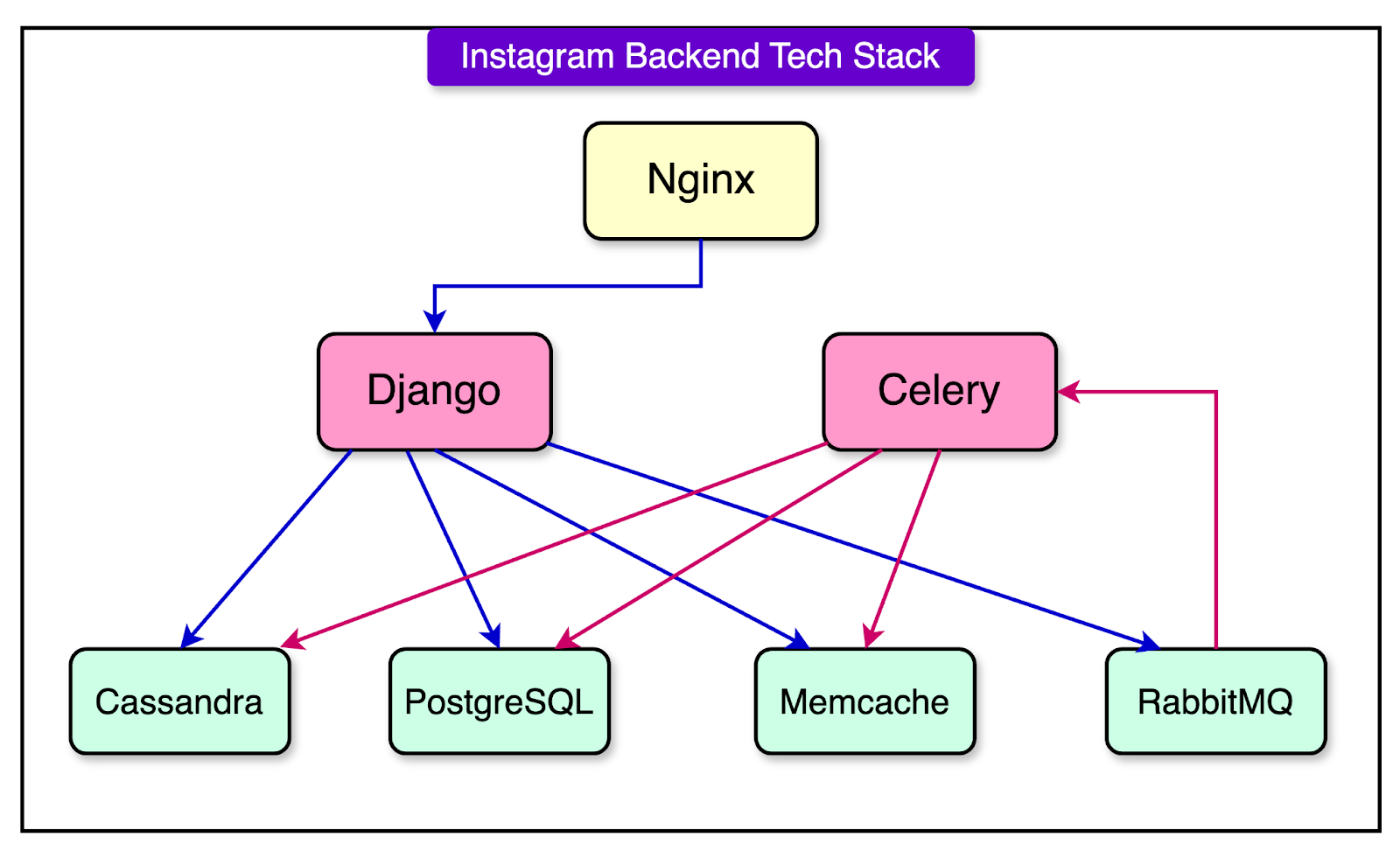
1 - Django - The Core Web Framework
Django, a high-level Python web framework, serves as the foundation of Instagram’s backend. It provides the core structure for handling HTTP requests, user authentication, database interactions, and API endpoints.
The main advantages of Django are as follows:
Rapid development: Pre-built components allow engineers to quickly iterate on features.
Scalability: Supports ORM (Object-Relational Mapping), enabling efficient database queries.
Security: Built-in protections against common vulnerabilities like SQL injection and cross-site scripting.
2 - RabbitMQ - Message Broker
RabbitMQ acts as a message broker, facilitating communication between different services. Instead of handling everything in a single request, RabbitMQ enables asynchronous task execution, improving performance and reliability.
Instagram uses RabbitMQ to decouple components and allow different services to interact without being directly dependent on each other. It handles spikes in traffic and manages message persistence even if one part of the system temporarily fails.
3 - Celery for Async Task Processing
Celery is a distributed task queue system that works alongside RabbitMQ to execute background tasks. It ensures that long-running processes do not slow down real-time user interactions.
Instagram uses Celery to handle asynchronous tasks such as sending emails or processing large media files. Celery also has fault tolerance where a task failure results in automatic retries. Celery workers can be distributed across multiple servers, handling high workloads efficiently.
How the Components Work Together?
Instagram’s backend components operate in a coordinated manner, ensuring efficiency. Let’s understand the process when a user likes a post:
User Action: The user taps the “Like” button on a post.
Django Processes the Request: The request is sent to Django’s web server. Django updates the like count in the PostgreSQL database.
Caching and Asynchronous Processing: If the post has been liked before, the like count is retrieved from Memcached instead of querying the database. Django sends a task to RabbitMQ to notify the post owner about the like.
RabbitMQ Queues the Notification Task: Instead of handling the notification immediately, RabbitMQ queues it for later processing.
Celery Worker Sends the Notification: A Celery worker retrieves the task from RabbitMQ, generates the notification, and sends it to the recipient.
Storage Services in Instagram’s Architecture
Storage services are responsible for persisting user data, media files, and metadata across multiple distributed databases.
Instagram employs a combination of structured and distributed storage solutions to manage different types of data efficiently.
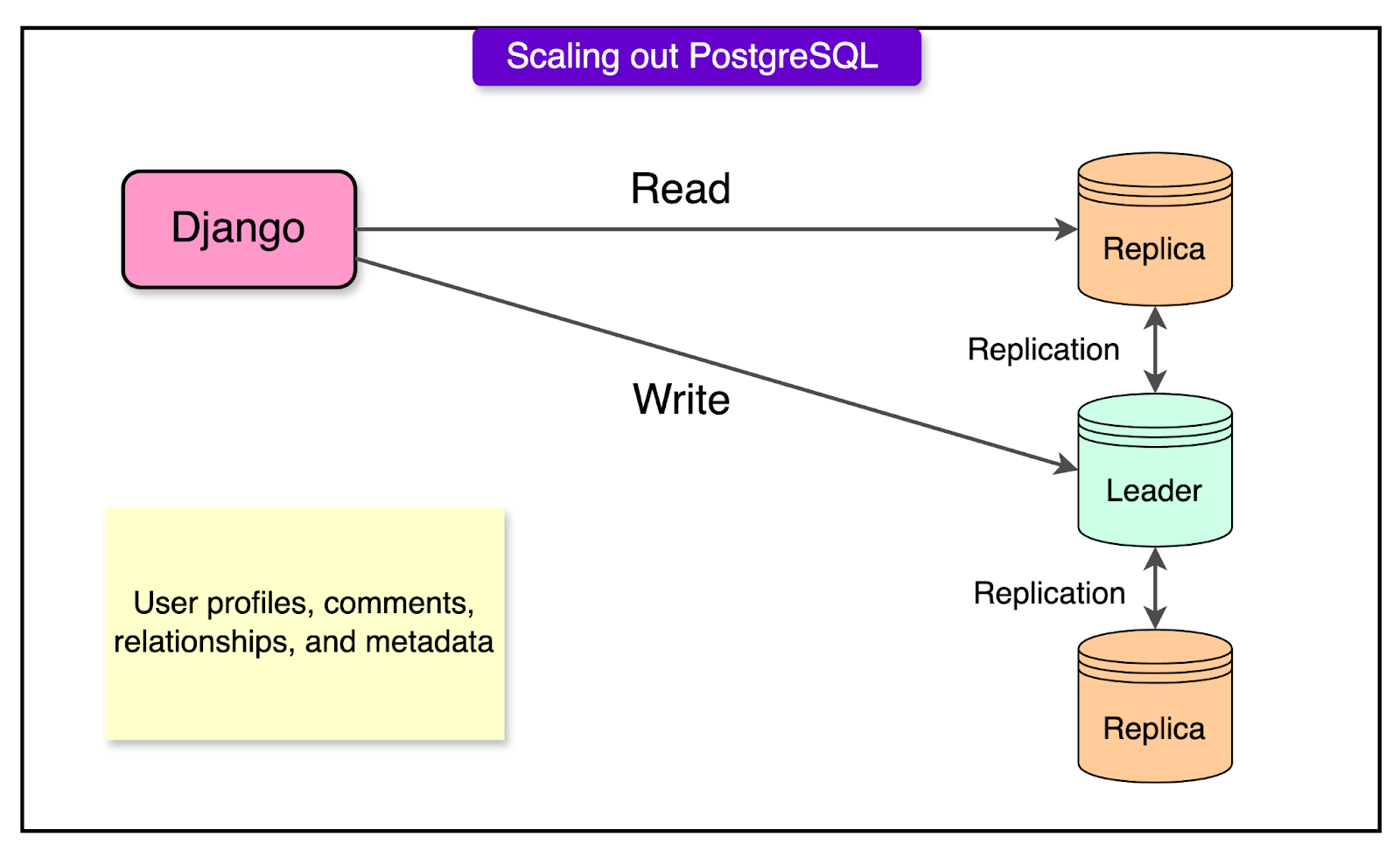
PostgreSQL: Stores structured data such as user profiles, comments, relationships, and metadata. It follows a master-replica architecture to ensure high availability and scalability. PostgreSQL also supports ACID compliance.
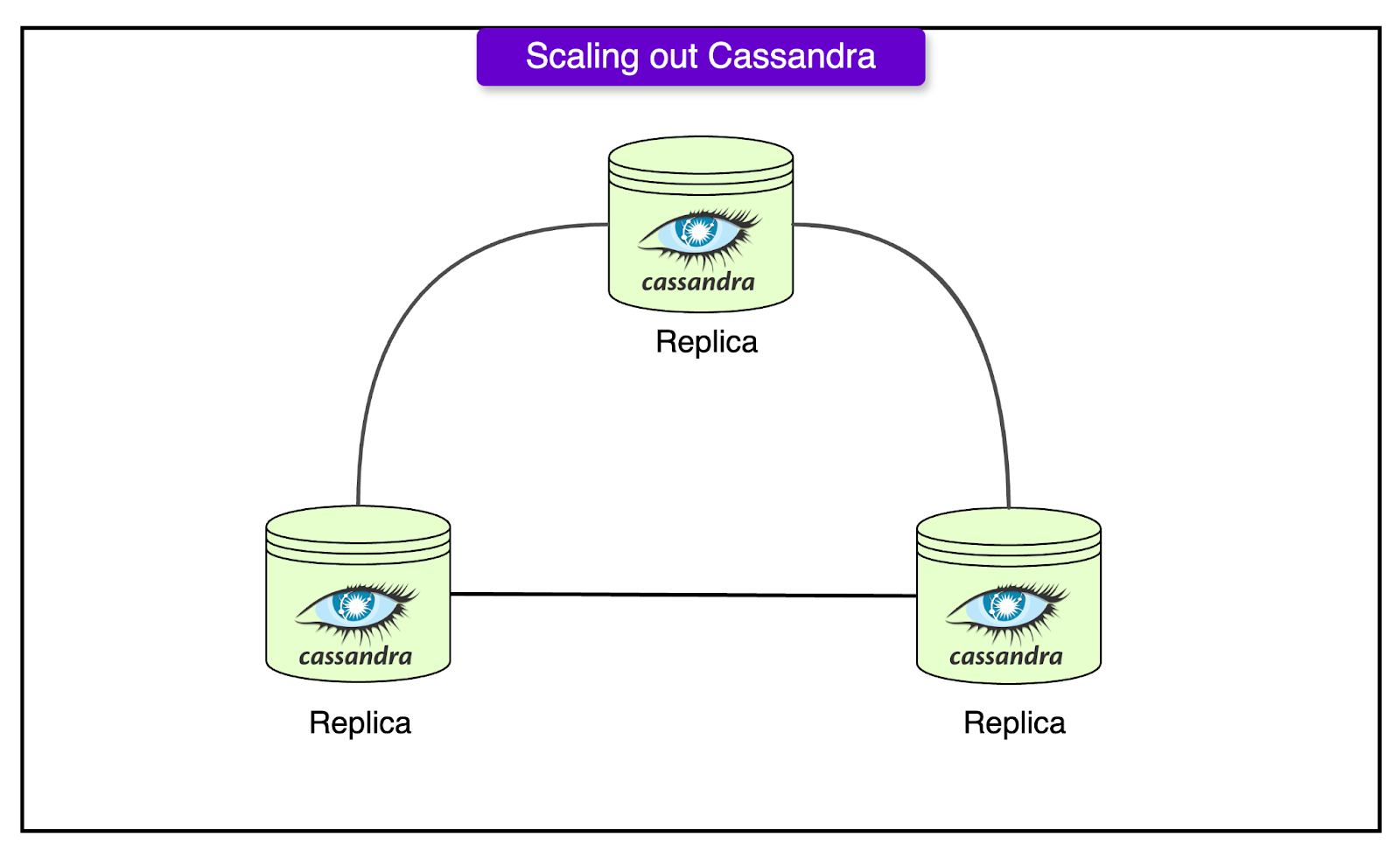
Cassandra: Used for storing highly distributed data, such as user feeds, activity logs, and analytics data. Unlike PostgreSQL, Cassandra follows an eventual consistency model, meaning data updates may take time to propagate across different regions. It provides high write throughput, making it ideal for operations like logging and real-time analytics.
Memcached: Used to reduce database load by caching frequently accessed data. It stores temporary copies of user profiles, posts, and like counts to prevent repeated queries to PostgreSQL or Cassandra. This helps optimize API response times
Haystack: Stores images and videos efficiently, minimizing the number of file system operations required to fetch content. It improves media loading times by serving cached versions of files through CDNs.
See the diagram below for PostgreSQL scaling out with leader-follower replication.
Also, the diagram below shows Cassandra scaling.
Since Instagram’s storage services are distributed across multiple data centers and geographic regions, maintaining data consistency is a major challenge.
The key data consistency challenges are as follows:
Replication Latency: In a distributed system, database replicas take time to sync, leading to temporary inconsistencies. For example, a user likes a post, but another user may not immediately see the updated like count because data replication has not been completed.
Eventual Consistency in NoSQL Systems: Cassandra uses an eventual consistency model, meaning updates propagate asynchronously across different database nodes. While this improves scalability, it can cause temporary discrepancies where different users see different versions of the same data.
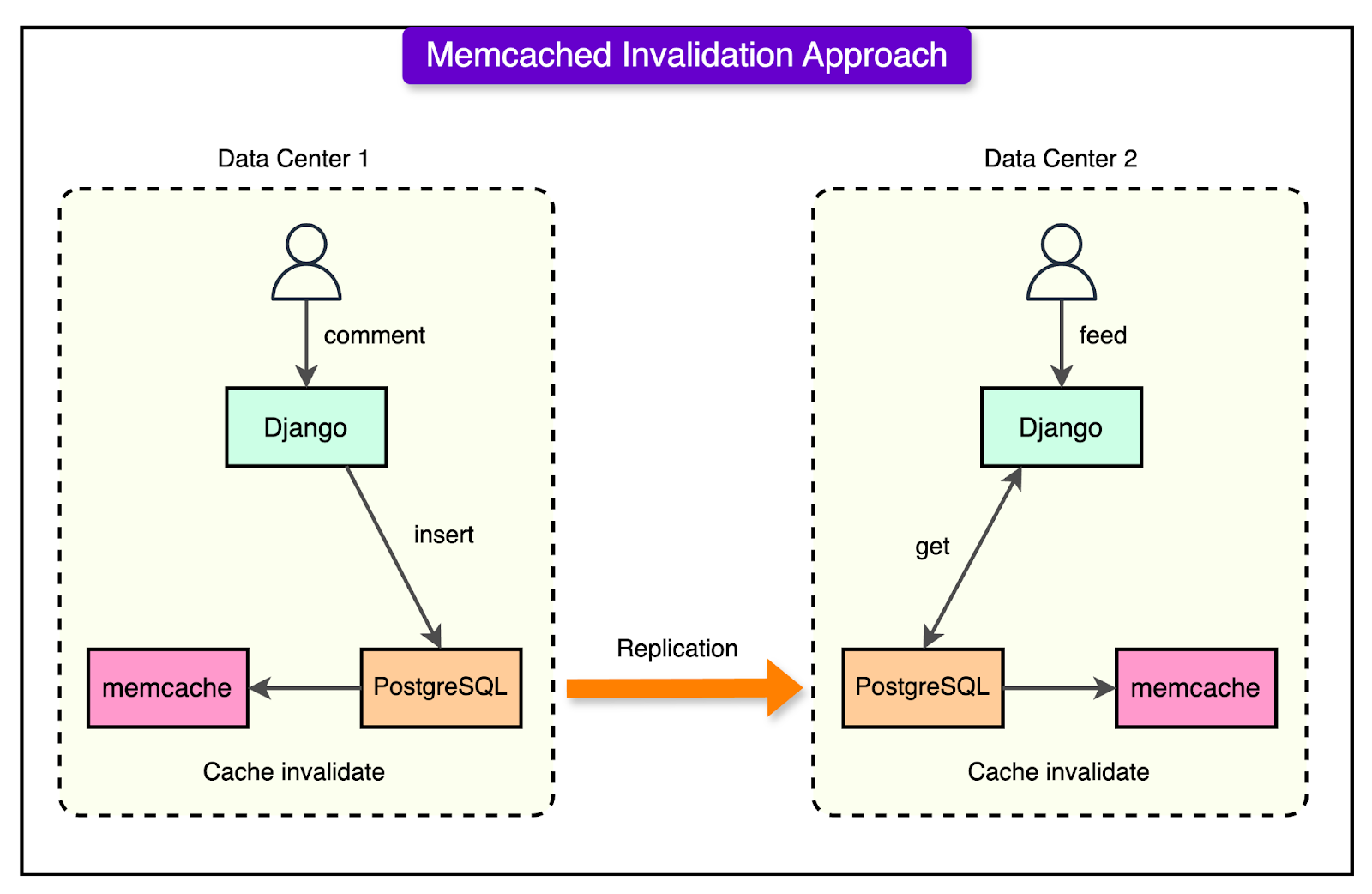
Cache Invalidation Issues: Memcached accelerates read operations, but if an update is made to the database, the cached data must be invalidated to reflect the latest changes. For example, if a user changes their profile picture, but the cached version is not updated immediately, they may see an outdated version of their profile.
Cross-Region Data Synchronization: Since Instagram operates multiple data centers, data must be synchronized across different geographic locations. Network failures or delays in replication can lead to inconsistencies between regions.
The Instagram engineering team uses several strategies to address these consistency challenges.
For example, PostgreSQL is used for critical transactions, such as financial transactions, user authentication, and content moderation, where strong consistency is required. On the other hand, Cassandra is used for highly scalable workloads, such as activity feeds, where slight delays in consistency are acceptable. Memcached entries are automatically invalidated when new data is written to PostgreSQL or Cassandra, preventing outdated information from being served.
See the diagram below that shows how cache invalidation is handled.
Memcache Lease Mechanism
As Instagram scaled to handle billions of daily interactions, it encountered a major challenge known as the thundering herd problem.
The issue occurs for frequently accessed data (like counts, user feeds, and comments), which is stored in Memcached for fast retrieval. When a cached value expires or is invalidated due to an update, multiple web servers request the same data from the database. If thousands or millions of users request the same piece of data at the same moment, the database gets overloaded with duplicate queries.
To mitigate this, Instagram implemented the Memcache Lease mechanism, which helps prevent multiple redundant database queries by controlling how cache misses are handled.
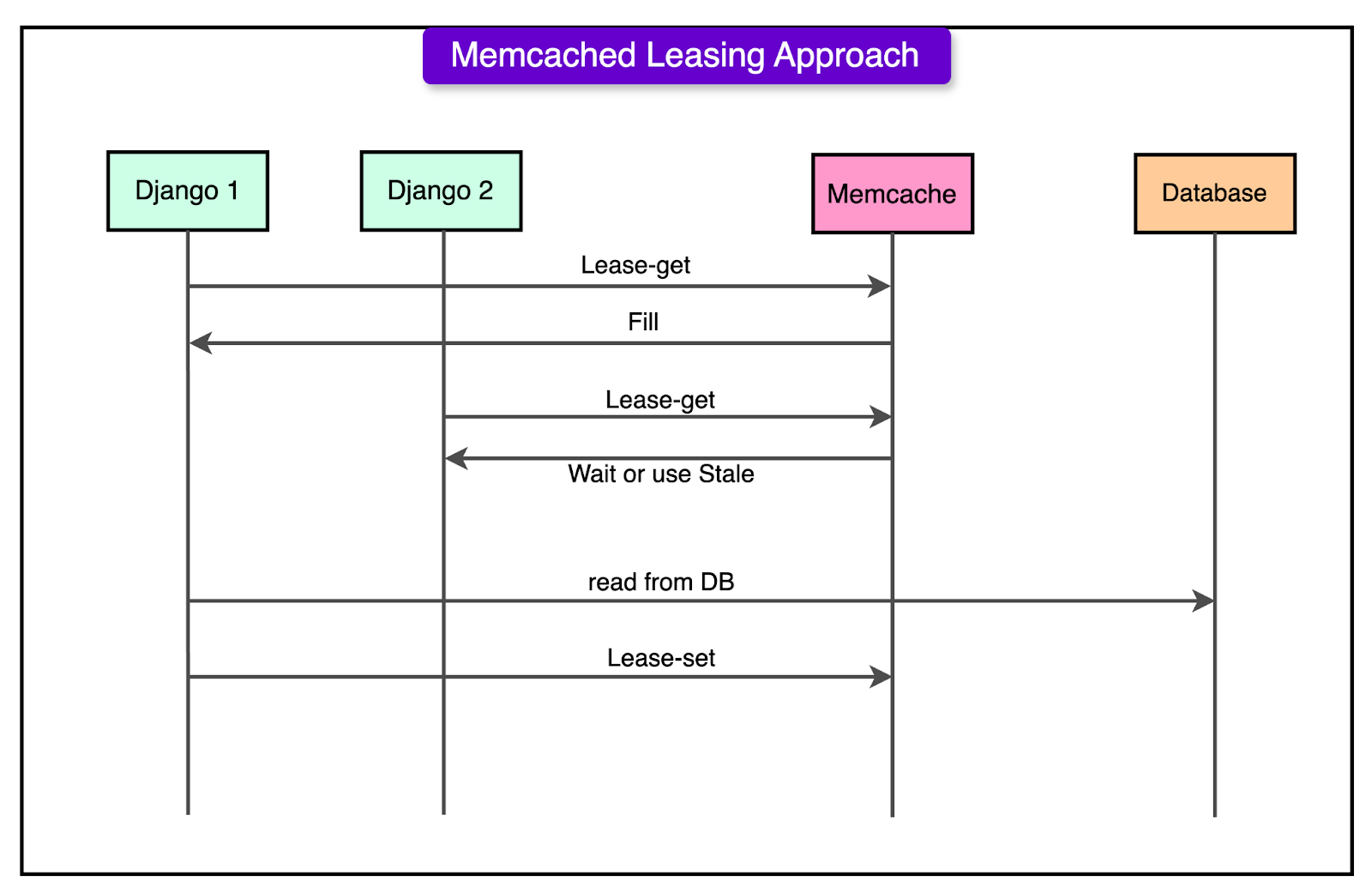
Here’s how it works:
A user requests an Instagram feed. For each post in the feed, there is associated data such as the like counts, comments, and media metadata.
The application first checks Memcached to retrieve this data.
If the requested data is not found in Memcached, instead of immediately querying the database, the server sends a lease request to Memcached. The first server to request the data is granted a lease token, meaning it is responsible for fetching fresh data from the database.
Other servers that request the same data do not query the database. Instead, they receive a stale value from Memcached or are told to wait. This ensures that only one server fetches the updated data from the database, while the rest hold back.
The server holding the lease token queries the database and fetches the fresh data. It also updates the Memcached entry.
The first server returns the fresh data to users while the rest wait until the cache is repopulated, avoiding a direct hit to the database.
Instagram’s Deployment Model
Instagram operates on a continuous deployment model, meaning new code is pushed to production multiple times per day. This approach allows Instagram to iterate quickly, fix issues promptly, and introduce new features without causing major disruptions.
Instagram’s deployment pipeline includes code review, automated testing, canary testing, and real-time monitoring to ensure that new changes do not introduce performance regressions.
Engineers submit changes through code review to ensure quality and maintainability. Every code change must pass unit tests, integration tests, and performance benchmarks before being merged into the main branch. Once code is merged, it is automatically tested in staging environments to identify functional or security issues.
Also, instead of deploying changes to all users at once, Instagram first deploys updates to a small subset of production servers (canary servers). Engineers monitor key performance metrics (CPU usage, memory consumption, error rates) to ensure the new code does not introduce regressions.
Lastly, Instagram also monitors and optimizes CPU usage.
It uses Linux-based profiling tools to track CPU usage at the function level. Engineers analyze which parts of the codebase consume the most CPU cycles and optimize them for better efficiency. They also use profiling tools and replace CPU-intensive Python functions with optimized C++ implementations for better performance.
Conclusion
Instagram’s ability to scale while maintaining high performance and reliability is proof of its well-designed infrastructure and deployment strategies.
By leveraging Django, RabbitMQ, Celery, PostgreSQL, and Cassandra, Instagram ensures seamless processing of billions of daily interactions It has separated computing and storage services to support efficient resource utilization and minimize database load. The implementation of techniques like Memcache leasing prevents the thundering herd problem, reducing redundant queries and improving system stability.
The platform’s continuous deployment model enables rapid innovation while minimizing risk through canary testing, feature gating, and automated rollbacks. Furthermore, real-time CPU tracking, performance regression testing, and automated monitoring allow engineers to detect and resolve inefficiencies before they impact users.
These strategies have positioned Instagram as one of the most resilient and scalable social media platforms, allowing it to support millions of concurrent users, high-traffic workloads, and rapid feature development without compromising performance or stability.
References:
Scaling Instagram Infrastructure
Instagration Part 2: Scaling Infrastructure to Multiple Data Centers
What powers Instagram: Hundreds of Instances, Dozens of Technologies
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
