Translation plays an essential role in enabling companies to expand across borders, with requirements varying significantly in terms of tone, accuracy, and technical terminology handling. The emergence of sovereign AI has highlighted critical challenges in large language models (LLMs), particularly their struggle to capture nuanced cultural and linguistic contexts beyond English-dominant frameworks. As global communication becomes increasingly complex, organizations must carefully evaluate translation solutions that balance technological efficiency with cultural sensitivity and linguistic precision.In this post, we explore how LLMs can address the following two distinct English to Traditional Chinese translation use cases:Marketing content for websites: Translating technical text with precision while maintaining a natural promotional tone.Online training courses: Translating slide text and markdown content used in platforms like Jupyter Notebooks, ensuring accurate technical translation and proper markdown formatting such as headings, sections, and hyperlinks.These use cases require a specialized approach beyond general translation. While prompt engineering with instruction-tuned LLMs can handle certain contexts, more refined tasks like these often do not meet expectations. This is where fine-tuning Low-Rank Adaptation (LoRA) adapters separately on collected datasets specific to each translation context becomes essential.Implementing LoRA adapters for domain-specific translation For this project, we are using Llama 3.1 8B Instruct as the pretrained model and implementing two models fine-tuned with LoRA adapters using NVIDIA NeMo Framework. These adapters were trained on domain-specific datasets—one for marketing website content and one for online training courses. For easy deployment of LLMs with simultaneous use of multiple LoRA adapters on the same pretrained model, we are using NVIDIA NIM. Refer to the Jupyter Notebook to guide you through executing LoRA fine-tuning with NeMo.Optimizing LLM deployment with LoRA and NVIDIA NIMNVIDIA NIM introduces a new level of performance, reliability, agility, and control for deploying professional LLM services. With prebuilt containers and optimized model engines tailored for different GPU types, you can easily deploy LLMs while boosting service performance. In addition to popular pretrained models including the Meta Llama 3 family and Mistral AI Mistral and Mixtral models, you can integrate and fine-tune your own models with NIM, further enhancing its capabilities.LoRA is a powerful customization technique that enables efficient fine-tuning by adjusting only a subset of the model’s parameters. This significantly reduces required computational resources. LoRA has become popular due to its effectiveness and efficiency. Unlike full-parameter fine-tuning, LoRA adapter weights are smaller and can be stored separately from the pretrained model, providing greater flexibility in deployment. NVIDIA TensorRT-LLM has established a mechanism that can simultaneously serve multiple LoRA adapters on the same pretrained model. This multi-adapter mechanism is also supported by NIM. The following sections demonstrate the advantages of these features and application in multipurpose translation tasks.Step-by-step LoRA fine-tuning deployment with NVIDIA LLM NIMThis section describes the three steps involved in LoRA fine-tuning deployment using NVIDIA LLM NIM.Step 1: Set up the NIM instance and LoRA modelsFirst, launch a computational instance equipped with two NVIDIA L40S GPUs as recommended in the NIM support matrix. Next, upload the two fine-tuned NeMo files to this environment. Detailed examples of LoRA fine-tuning using NeMo Framework are available in the official documentation and a Jupyter Notebook. To organize the environment, use the following command to create directories for storing the LoRA adapters:$ mkdir -p loras/llama-3.1-8b-translate-course$ mkdir -p loras/llama-3.1-8b-translate-web$ export LOCAL_PEFT_DIRECTORY=$(pwd)/loras$ chmod -R 777 $(pwd)/loras$ tree lorasloras├── llama-3.1-8b-translate-course│ └── course.nemo└── llama-3.1-8b-translate-web └── web.nemo2 directories, 2 filesStep 2: Deploy NIM and LoRA models Now, you can proceed to deploy the NIM container. Replace <NGC_API_KEY> with your actual NGC API token. Generate an API key if needed. Then run the following commands:$ export NGC_API_KEY=<NGC_API_KEY>$ export LOCAL_PEFT_DIRECTORY=$(pwd)/loras$ export NIM_PEFT_SOURCE=/home/nvs/loras$ export CONTAINER_NAME=nim-llama-3.1-8b-instruct$ export NIM_CACHE_PATH=$(pwd)/nim-cache$ mkdir -p "$NIM_CACHE_PATH"$ chmod -R 777 $NIM_CACHE_PATH$ echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin$ docker run -it --rm --name=$CONTAINER_NAME \ --runtime=nvidia \ --gpus all \ --shm-size=16GB \ -e NGC_API_KEY=$NGC_API_KEY \ -e NIM_PEFT_SOURCE \ -v $NIM_CACHE_PATH:/opt/nim/.cache \ -v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \ -p 8000:8000 \ nvcr.io/nim/meta/llama-3.1-8b-instruct:1.1.2After executing these steps, NIM will load the model. Once complete, you can check the health status and retrieve the model names for both the pretrained model and LoRA models using the following commands:# NIM health status$ curl http://<INSTANCE_URL>:8000/v1/health/ready# Get model names of the base model and LoRA models$ curl http://<INSTANCE_URL>:8000/v1/models | jq{ "data" : [ { "created" : 1725516389, "id" : "meta/llama-3.1-8b-instruct", "max_model_len" : 131072, "object" : "model", "owned_by" : "system", "parent" : null, "permission" : [ { "allow_create_engine" : false, "allow_fine_tuning" : false, "allow_logprobs" : true, "allow_sampling" : true, "allow_search_indices" : false, "allow_view" : true, "created" : 1725516389, "group" : null, "id" : "modelperm-2274791587e4456b9ce921621377becb", "is_blocking" : false, "object" : "model_permission", "organization" : "" } ], "root" : "meta/llama-3.1-8b-instruct" }, { "created" : 1725516389, "id" : "llama-3.1-8b-translate-course", "max_model_len" : null, "object" : "model", "owned_by" : "system", "parent" : null, "permission" : [ { "allow_create_engine" : false, "allow_fine_tuning" : false, "allow_logprobs" : true, "allow_sampling" : true, "allow_search_indices" : false, "allow_view" : true, "created" : 1725516389, "group" : null, "id" : "modelperm-cb8be2bce8db442d8347f259966e2c02", "is_blocking" : false, "object" : "model_permission", "organization" : "" } ], "root" : "meta/llama-3.1-8b-instruct" }, { "created" : 1725516389, "id" : "llama-3.1-8b-translate-web", "max_model_len" : null, "object" : "model", "owned_by" : "system", "parent" : null, "permission" : [ { "allow_create_engine" : false, "allow_fine_tuning" : false, "allow_logprobs" : true, "allow_sampling" : true, "allow_search_indices" : false, "allow_view" : true, "created" : 1725516389, "group" : null, "id" : "modelperm-8e404c4d9f504e5fae92bf6caf04e93c", "is_blocking" : false, "object" : "model_permission", "organization" : "*" } ], "root" : "meta/llama-3.1-8b-instruct" } ], "object" : "list"}The output will display details of the models available for deployment.Step 3: Evaluate translation quality of fine-tuned LoRA modelsWith NIM running, you can use it to perform English to Traditional Chinese translation, specifying the appropriate LoRA model name in the request body. Fine-tuning results and performance metricsWe evaluated the translation quality of two test datasets using the pretrained model and the two fine-tuned LoRA models. The BLEU and COMET scores from these evaluations are shown in Figures 1 and 2. Figure 1. BLEU scores (higher is better) of different test datasets using the base model and two LoRA fine-tuned models
Figure 1. BLEU scores (higher is better) of different test datasets using the base model and two LoRA fine-tuned models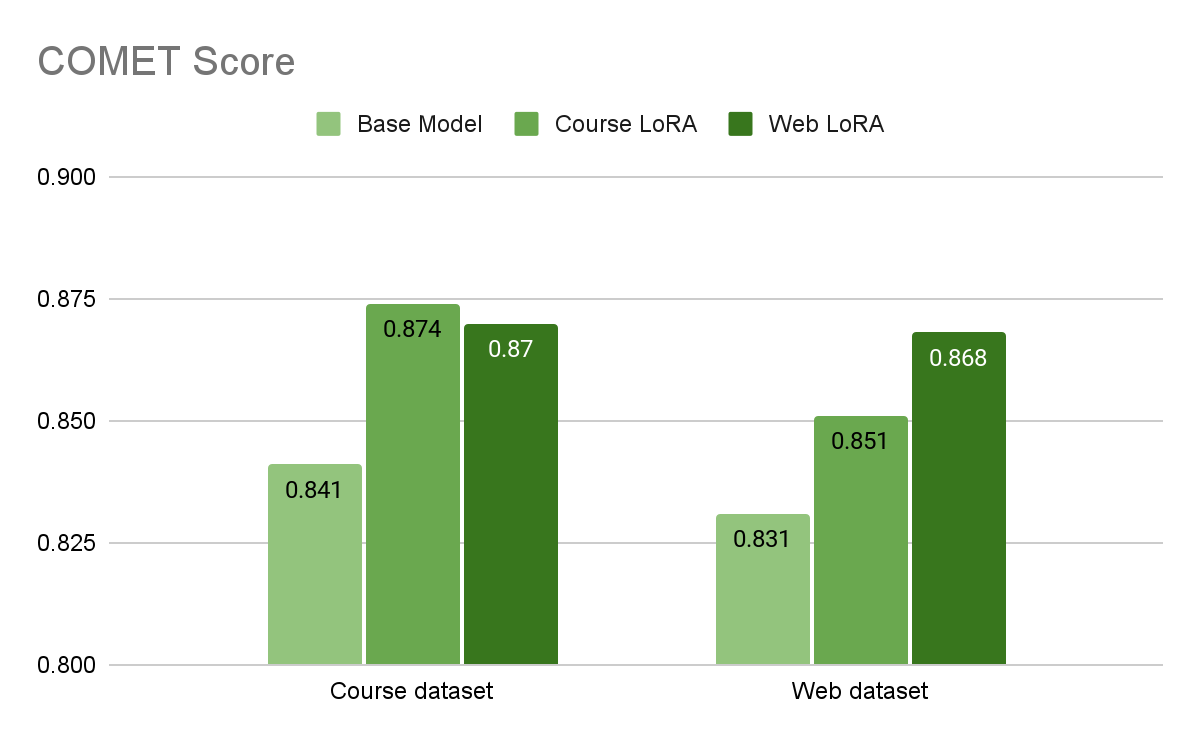 Figure 2. COMET scores (higher is better) of different test datasets using the base model and two LoRA modelsThese results demonstrate that fine-tuning specific datasets using the LoRA mechanism significantly enhances translation quality within their respective domains. To achieve the best performance, domain-specific datasets should leverage their corresponding fine-tuned LoRA models.The LoRA model fine-tuned on the web dataset demonstrated a more noticeable improvement in evaluation scores for web-related translations. Table 1 provides a comparison of translation examples.Source TextPretrained Model OutputLoRA Fine-Tuned Model (on Web Dataset) Output NVIDIA extends lead on MLPerf inference benchmark for computer vision, conversational AI, and recommender workloads.NVIDIA 在計算視覺、對話式人工智慧和建議系統工作負載方面,領先於 MLPerf 推理基準。NVIDIA 在電腦視覺、對話式人工智慧和推薦系統工作負載的 MLPerf 推論基準中擴大領先地位。Built on NVIDIA Omniverse, NVIDIA RTX Remix enables modders to easily capture game assets, automatically enhance materials with generative AI tools, and quickly create stunning RTX remasters with full ray tracing and DLSS 3.在 NVIDIA Omniverse 上建立,RTX Remix 允許模組開發者輕鬆捕捉遊戲資源、自動使用生成 AI 工具增強材質,並快速創建具有全實時光線追蹤和 DLSS 3 的 RTX 重製版。RTX Remix 是以 NVIDIA Omniverse 為基礎,讓模組玩家能輕鬆擷取遊戲素材、使用生成式人工智慧工具自動增強材質,並快速創造出充分採用全光線追蹤技術和 DLSS 3 的令人驚豔的 RTX 重製版。Note that the prompt template is as follows:<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an AI assistant who translates an English context to traditional Chinese. The context will be given after a prompt “Translate the following input text to traditional Chinese”. Never respond text other than translation results.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nTranslate the following input text to traditional Chinese.\n\n{English Text}.\n<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nTable 1. Sentence translation comparison for the web datasetExplore further with NVIDIA NIM and LoRA fine-tuningFine-tuning LoRA adapters separately on marketing content from websites and online training course datasets significantly improved translation quality. This demonstrates that domain-specific datasets achieve better results when paired with their own LoRA models, which efficiently adjust the weights of pretrained models to enhance performance. Deploying these fine-tuned models within a single NVIDIA NIM instance provides a GPU-efficient solution for serving multiple specialized tasks simultaneously. Ready to take it further? Explore how NVIDIA NIM microservices can help you deploy and fine-tune LLMs for your specific tasks. With NVIDIA NeMo, you can fine-tune popular models such as Llama 3, Mistral, and Phi using LoRA adapters, unlocking greater development efficiency and enhancing the performance of your applications.
Figure 2. COMET scores (higher is better) of different test datasets using the base model and two LoRA modelsThese results demonstrate that fine-tuning specific datasets using the LoRA mechanism significantly enhances translation quality within their respective domains. To achieve the best performance, domain-specific datasets should leverage their corresponding fine-tuned LoRA models.The LoRA model fine-tuned on the web dataset demonstrated a more noticeable improvement in evaluation scores for web-related translations. Table 1 provides a comparison of translation examples.Source TextPretrained Model OutputLoRA Fine-Tuned Model (on Web Dataset) Output NVIDIA extends lead on MLPerf inference benchmark for computer vision, conversational AI, and recommender workloads.NVIDIA 在計算視覺、對話式人工智慧和建議系統工作負載方面,領先於 MLPerf 推理基準。NVIDIA 在電腦視覺、對話式人工智慧和推薦系統工作負載的 MLPerf 推論基準中擴大領先地位。Built on NVIDIA Omniverse, NVIDIA RTX Remix enables modders to easily capture game assets, automatically enhance materials with generative AI tools, and quickly create stunning RTX remasters with full ray tracing and DLSS 3.在 NVIDIA Omniverse 上建立,RTX Remix 允許模組開發者輕鬆捕捉遊戲資源、自動使用生成 AI 工具增強材質,並快速創建具有全實時光線追蹤和 DLSS 3 的 RTX 重製版。RTX Remix 是以 NVIDIA Omniverse 為基礎,讓模組玩家能輕鬆擷取遊戲素材、使用生成式人工智慧工具自動增強材質,並快速創造出充分採用全光線追蹤技術和 DLSS 3 的令人驚豔的 RTX 重製版。Note that the prompt template is as follows:<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an AI assistant who translates an English context to traditional Chinese. The context will be given after a prompt “Translate the following input text to traditional Chinese”. Never respond text other than translation results.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nTranslate the following input text to traditional Chinese.\n\n{English Text}.\n<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nTable 1. Sentence translation comparison for the web datasetExplore further with NVIDIA NIM and LoRA fine-tuningFine-tuning LoRA adapters separately on marketing content from websites and online training course datasets significantly improved translation quality. This demonstrates that domain-specific datasets achieve better results when paired with their own LoRA models, which efficiently adjust the weights of pretrained models to enhance performance. Deploying these fine-tuned models within a single NVIDIA NIM instance provides a GPU-efficient solution for serving multiple specialized tasks simultaneously. Ready to take it further? Explore how NVIDIA NIM microservices can help you deploy and fine-tune LLMs for your specific tasks. With NVIDIA NeMo, you can fine-tune popular models such as Llama 3, Mistral, and Phi using LoRA adapters, unlocking greater development efficiency and enhancing the performance of your applications.

