


Large language models (LLMs) have demonstrated exceptional problem-solving abilities, yet complex reasoning tasks—such as competition-level mathematics or intricate code generation—remain challenging. These tasks demand precise navigation through vast solution spaces and meticulous step-by-step deliberation. Existing methods, while improving accuracy, often suffer from high computational costs, rigid search strategies, and difficulty generalizing across diverse problems. In this paper researchers introduced a new framework, ReasonFlux that addresses these limitations by reimagining how LLMs plan and execute reasoning steps using hierarchical, template-guided strategies.
Recent approaches to enhance LLM reasoning fall into two categories: deliberate search and reward-guided methods. Techniques like Tree of Thoughts (ToT) enable LLMs to explore multiple reasoning paths, while Monte Carlo Tree Search (MCTS) decomposes problems into steps guided by process reward models (PRMs). Though effective, these methods scale poorly due to excessive sampling and manual search design. For instance, MCTS requires iterating through thousands of potential steps, making it computationally prohibitive for real-world applications. Meanwhile, retrieval-augmented generation (RAG) methods like Buffer of Thought (BoT) leverage stored problem-solving templates but struggle to integrate multiple templates adaptively, limiting their utility in complex scenarios.
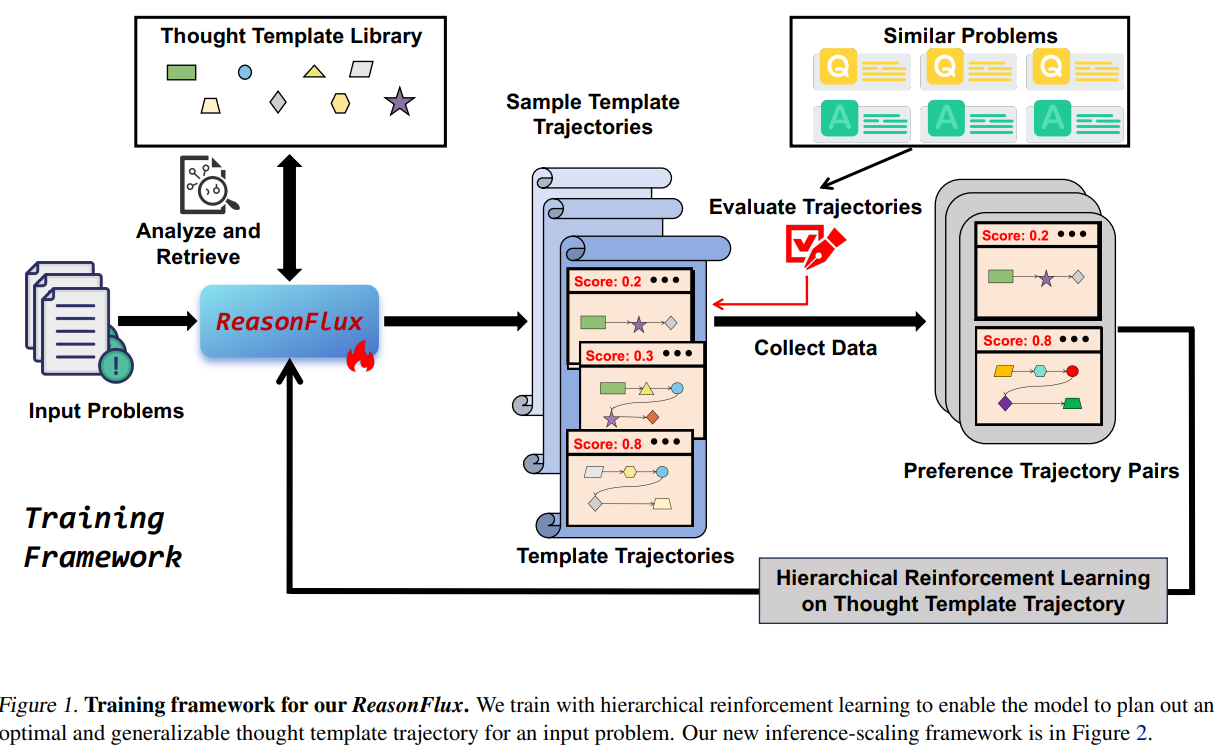
ReasonFlux introduces a structured framework that combines a curated library of high-level thought templates with hierarchical reinforcement learning (HRL) to dynamically plan and refine reasoning paths. Instead of optimizing individual steps, it focuses on configuring optimal template trajectories—sequences of abstract problem-solving strategies retrieved from a structured knowledge base. This approach simplifies the search space and enables efficient adaptation to sub-problems. The framework consists of three main components:
- Structured Template Library: The research team constructed a library of 500 thought templates, each encapsulating a problem-solving strategy (e.g., “Trigonometric Substitution for Integral Optimization”). Templates include metadata—names, tags, descriptions, and application steps—enabling efficient retrieval. For example, a template tagged “Irrational Function Optimization” might guide an LLM to apply specific algebraic substitutions.
- Hierarchical Reinforcement Learning:
- Structure-Based Fine-Tuning: A base LLM (e.g., Qwen2.5-32B) is fine-tuned to associate template metadata with their functional descriptions, ensuring it understands when and how to apply each template. Template Trajectory Optimization: Using preference learning, the model learns to rank template sequences by their effectiveness. For a given problem, multiple trajectories are sampled, and their success rates on similar problems determine rewards. This trains the model to prioritize high-reward sequences, refining its planning capability.
- Adaptive Inference Scaling: During inference, ReasonFlux acts as a “navigator,” analyzing the problem to retrieve relevant templates and dynamically adjusting the trajectory based on intermediate results. For instance, if a step involving “Polynomial Factorization” yields unexpected constraints, the system might pivot to a “Constraint Propagation” template. This iterative interplay between planning and execution mirrors human problem-solving, where partial solutions inform subsequent steps.

ReasonFlux was evaluated on competition-level benchmarks like MATH, AIME, and OlympiadBench, outperforming both frontier models (GPT-4o, Claude) and specialized open-source models (DeepSeek-V3, Mathstral). Key results include:
- 91.2% accuracy on MATH, surpassing OpenAI’s o1-preview by 6.7%. 56.7% on AIME 2024, exceeding DeepSeek-V3 by 45% and matching o1-mini. 63.3% on OlympiadBench, a 14% improvement over prior methods.
Moreover, the structured template library demonstrated strong generalization: when applied to variant problems, it boosted smaller models (e.g., 7B parameters) to outperform larger counterparts using direct reasoning. Additionally, ReasonFlux achieved a superior exploration-exploitation balance, requiring 40% fewer computational steps than MCTS and Best-of-N on complex tasks (Figure 5).
In summary, ReasonFlux redefines how LLMs approach complex reasoning by decoupling high-level strategy from step-by-step execution. Its hierarchical template system reduces computational overhead while improving accuracy and adaptability, addressing critical gaps in existing methods. By leveraging structured knowledge and dynamic planning, the framework sets a new standard for efficient, scalable reasoning—proving that smaller, well-guided models can rival even the largest frontier systems. This innovation opens avenues for deploying advanced reasoning in resource-constrained environments, from education to automated code generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post ReasonFlux: Elevating LLM Reasoning with Hierarchical Template Scaling appeared first on MarkTechPost.
