


Large Language Models (LLMs) have revolutionized natural language processing (NLP) but face significant challenges in practical applications due to their large computational demands. While scaling these models improves performance, it creates substantial resource constraints in real-time applications. Current solutions like MoE Mixture of Experts (MoE) enhance training efficiency through selective parameter activation but suffer slower inference times due to increased memory access requirements. Another solution, Product Key Memory (PKM) maintains consistent memory access with fewer value embeddings but delivers subpar performance compared to MoE. MoE models, despite having 12 times more parameters than dense models, operate 2 to 6 times slower during inference.
Various approaches have emerged to address the computational challenges in LLMs. Researchers have focused on enhancing MoE’s gating functions through improved token choice mechanisms and expert selection strategies to combat expert imbalance. Recent developments involve slicing experts into smaller segments while activating multiple experts per token. PKM represents another approach, implementing the smallest possible expert configuration, with subsequent improvements including parallel operation with MLPs and modified value activation methods. Lastly, tensor decomposition techniques have been explored to break down large tensors into smaller components, with product quantization enabling vector reconstruction using fewer sub-vectors to reduce model parameters.
A team from Seed-Foundation-Model at ByteDance has proposed UltraMem, a novel architecture that revolutionizes the implementation of large-scale memory layers in language models. It is built upon the foundation of PKM while introducing ultra-sparse memory layers that dramatically improve computational efficiency and reduce inference latency. UltraMem achieves superior performance compared to both PKM and MoE models at equivalent scales, making it particularly suitable for resource-constrained environments. UltraMem demonstrates remarkable scaling capabilities, outperforming MoE in inference speed by up to 6 times under common batch sizes, while maintaining computational efficiency comparable to dense models.
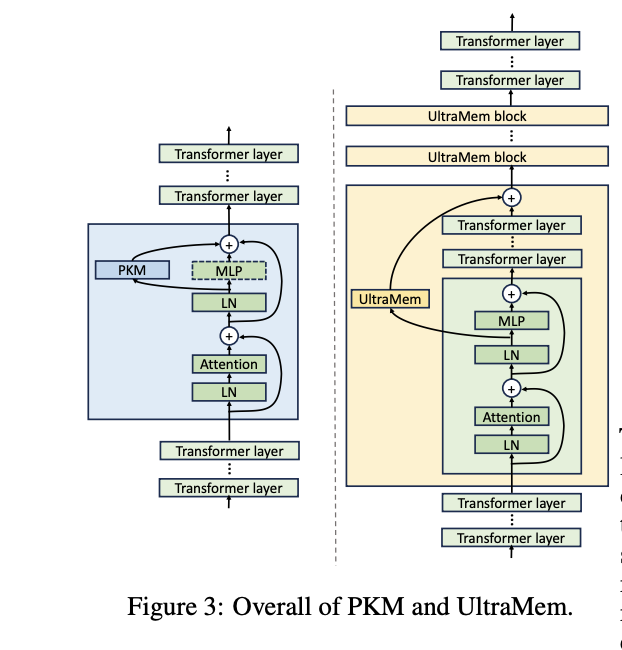
UltraMem adopts a Pre-LayerNorm Transformer architecture with significant modifications to address the limitations of traditional PKM structures. The architecture distributes multiple smaller memory layers at fixed intervals throughout the transformer layers, replacing the single large memory layer used in PKM. This distribution tackles the difficulty in finding correct values when value size increases and the unbalanced computation across multiple GPUs during large-scale training. The design also addresses the inherent bias in product key decomposition, where traditional top-k retrieval is constrained by row and column positions. Moreover, the skip-layer structure optimizes the memory-bound operations during training and improves overall computational efficiency.
The performance evaluation of UltraMem across various model sizes shows impressive results against existing architectures. With equivalent parameters and computation costs, UltraMem outperforms PKM and MoE models as capacity increases. UltraMem model with 12 times the parameters matches the performance of a 6.5B dense model while maintaining the computational efficiency of a 1.6B dense model. Scaling experiments reveal that UltraMem maintains stable inference times even with exponential parameter growth, provided the activated parameters remain constant. This contrasts sharply with MoE models, which show significant performance degradation, highlighting UltraMem’s superior efficiency in managing sparse parameters.
This paper introduces UltraMem which represents a significant advancement in LLM architecture, showing superior performance characteristics compared to existing approaches. It achieves up to six times faster processing speeds than MoE models while maintaining minimal memory access requirements. UltraMem exhibits enhanced scaling capabilities as model capacity increases, outperforming MoE models with equivalent parameters and computational resources. These impressive results establish UltraMem as a promising foundation for developing more efficient and scalable language models, revolutionizing the field of NLP by enabling the creation of more powerful models while maintaining practical resource requirements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post ByteDance Introduces UltraMem: A Novel AI Architecture for High-Performance, Resource-Efficient Language Models appeared first on MarkTechPost.
