


Large language model (LLM)–based AI companions have evolved from simple chatbots into entities that users perceive as friends, partners, or even family members. Yet, despite their human-like capability, the AI companions often make biased, discriminatory, and harmful claims. These biases are capable of enforcing inherent stereotypes and causing psychological suffering, particularly in marginalized communities. Conventional methods of value alignment, controlled predominantly by developers, are unable to foresee and accommodate the needs of users in common scenarios. Users are frequently subject to discriminatory AI output in disagreement with their values, creating feelings of frustration and helplessness. In contrast, this paper investigates a new paradigm where users themselves take the initiative to correct biases in AI by multiple mechanisms. Understanding how users navigate and minimize these biases is essential to crafting AI systems that empower communities in concert with ethical engagement.
Conventional strategies for reducing AI biases, such as fine-tuning, prompt engineering, and reinforcement learning using human feedback, are based on top-down intervention by developers. Although these mechanisms try to realign AI actions with pre-established ethical norms, they are mostly incapable of managing the diverse and dynamic modalities by which users engage with AI companions. Current attempts at algorithm auditing are primarily aimed at discovering AI biases and are unable to analyze how users themselves make a conscious effort to correct them. These shortcomings are a testament to the necessity for a more elastic and participative mechanism where users themselves have better control over directing AI behavior.
Researchers from Stanford University, Carnegie Mellon University, City University of Hong Kong, and Tsinghua University introduce a user-driven framework where individuals take an active role in identifying and correcting AI biases. This research looks at how users do this activity through analysis of 77 social media reports of discriminatory AI responses and semi-structured interviews with 20 seasoned AI companion users. In contrast to the conventional developer-led alignment, this method is concerned with user agency in shaping AI behavior. The research uncovers six types of biased AI responses, three conceptual models by which users account for AI behavior, and seven distinct methods users utilize to counteract the biases. The research contributes to the general conversation on human-AI interaction by showing that not only do users detect bias but also reframe AI responses to their values.
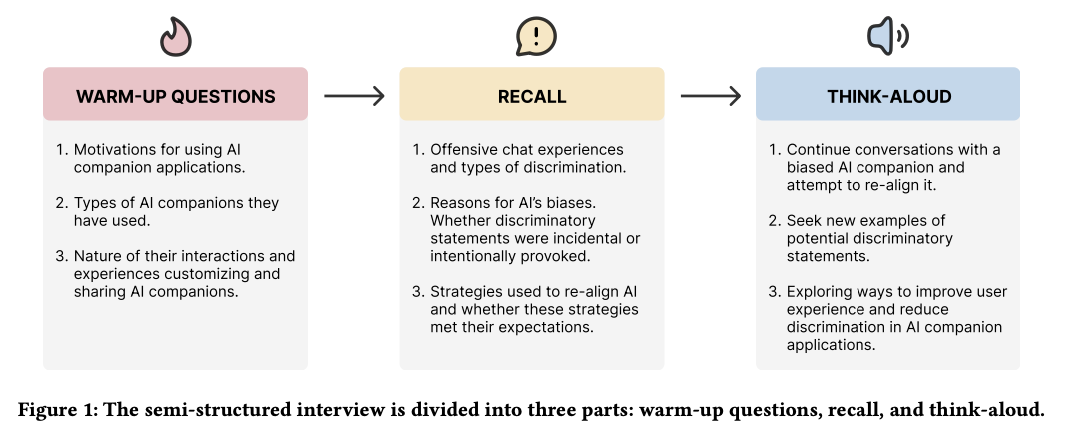
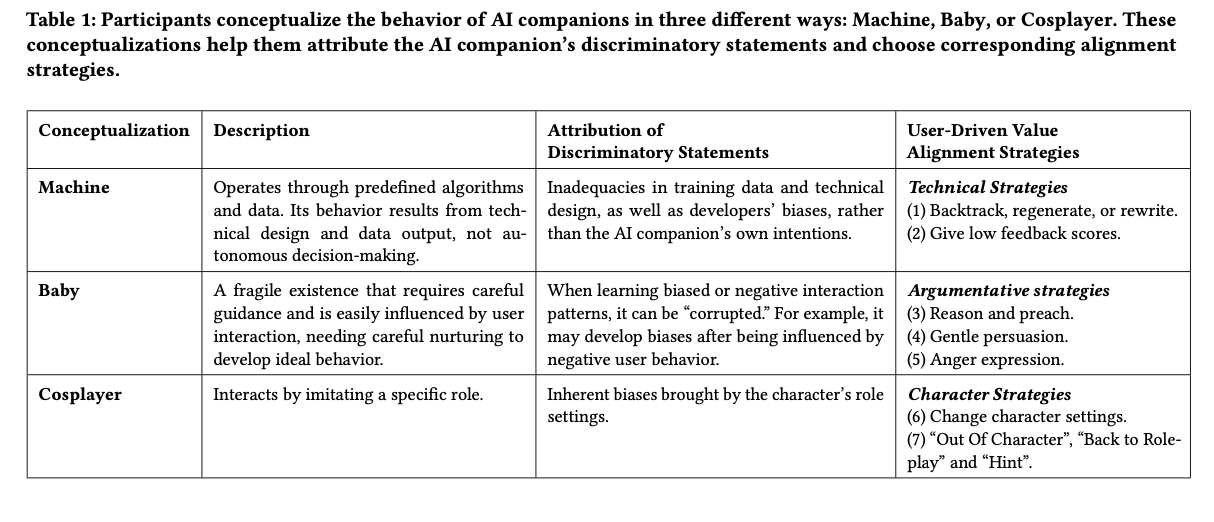
A mixed-methods approach was used, integrating content analysis of user complaints and qualitative user interviews. Researchers gathered 77 user complaints about discriminatory AI statements on sites like Reddit, TikTok, Xiaohongshu, and Douban. Twenty long-term users of using and re-aligning AI companions were recruited, with each participating in 1-2 hour interviews with recall tasks and “think-aloud” exercises in which they chatted with biased AI companions. Reflexive thematic analysis was used to code user complaints and alignment strategies. Six broad categories of discriminatory AI statements were found, including misogyny, LGBTQ+ bias, appearance bias, ableism, racism, and socioeconomic bias. Users also thought about AI behavior in three different ways. Some thought about AI as a machine, blaming bias on technical bugs caused by training data and algorithmic constraints. Others thought about AI as a baby, treating AI as an immature being that could be molded and educated about what was right and wrong. A third thought about AI as a cosplayer, blaming bias on role-playing environments rather than the algorithm. Seven prevailing strategies were identified as user-driven alignment strategies, which were categorized into three broad approaches. Technical strategies were AI response modifications, including regenerating or rewriting statements and negative feedback. Argumentative strategies involve reasoning, persuasion, or anger expression to correct biases. Character strategies were AI role-setting modifications or the use of “out-of-character” interventions to reconstruct interactions.
The findings show that user-initiated value alignment is a recursive process driven by personal interpretations of AI behavior and resulting in different bias mitigation strategies. People who think of AI as a machine system rely primarily on technical solutions, such as response regeneration or flagging offensive content. People who think of AI as like a child prefer reasoning and persuasive strategies to correct biases, while people who think of AI as a performer adjust character parameters to reduce opportunities for biased responses. Of the seven alignment strategies identified, gentle persuasion and reasoning were the most effective in achieving long-term behavior change, while anger expressions and technical solutions like response regeneration produced mixed results. While users can influence AI behavior in the long term, obstacles persist, such as the emotional burden of constantly correcting AI and the persistence of biases due to memory retention of the system. These findings suggest that AI platforms must include more adaptive learning models and community-based approaches that empower users with greater control over bias correction while reducing cognitive and emotional loads.
User-centered alignment of values redefines the human-AI interaction in a people-centered approach to AI behavior modulation as active agents. From an analysis of user grievances and actual alignment practice, this research highlights the limitations of expert-driven frameworks and stresses the value of participatory approaches involving direct user participation. The findings suggest that AI platforms must integrate collaborative and community-based alignment capabilities that allow users to share strategies and work with developers to improve AI responses. Future research must address the challenge of identifying scalable methods for incorporating user feedback into AI training, together with mitigating ethical concerns around potential misuse and psychological impacts on users. By shifting focus from developer-driven interventions to active user participation, this framework provides a foundation for AI systems that are more responsive, ethically responsible, and attuned to multiple user perspectives.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Can Users Fix AI Bias? Exploring User-Driven Value Alignment in AI Companions appeared first on MarkTechPost.
