


Artificial intelligence has made significant strides, yet developing models capable of nuanced reasoning remains a challenge. Many existing models struggle with complex problem-solving tasks, particularly in mathematics, coding, and scientific reasoning. These difficulties often arise due to limitations in data quality, model architecture, and the scalability of training processes. The need for open-data reasoning models that perform at a high level is increasingly important, especially as proprietary models continue to lead the field.
OpenThinker-32B is an open-data reasoning model developed by the Open Thoughts team to address these challenges. Fine-tuned from Qwen2.5-32B-Instruct using the OpenThoughts-114k dataset, the model demonstrates strong performance across a range of reasoning tasks, including those in mathematics, coding, and scientific inquiry.
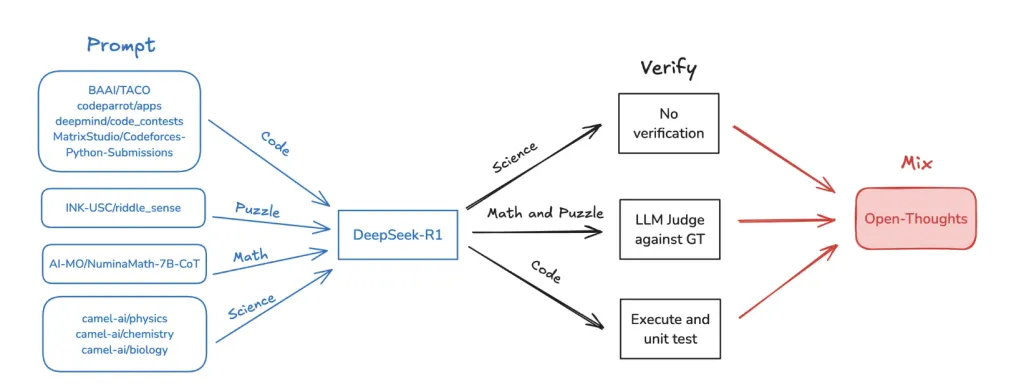

From a technical perspective, OpenThinker-32B features 32.8 billion parameters and supports a context length of 16,000 tokens, allowing it to process complex tasks requiring extended context. The model was trained over three epochs using the LLaMa-Factory framework, employing a learning rate of 1e-5 with a cosine learning rate scheduler. Training was conducted on AWS SageMaker across four nodes, each equipped with eight H100 GPUs, over approximately 90 hours. This training setup enhances the model’s ability to manage intricate reasoning processes efficiently.
Performance evaluations show that OpenThinker-32B outperforms other open-data reasoning models across multiple benchmarks. It achieves an accuracy of 90.6 on the MATH500 benchmark and a score of 61.6 on the GPQA-Diamond benchmark, indicating strong general problem-solving capabilities. These results reflect the model’s ability to handle a diverse set of reasoning challenges effectively.
In summary, OpenThinker-32B presents a well-rounded contribution to the field of AI reasoning models. By utilizing a carefully curated dataset and a rigorous training process, it addresses many of the limitations of earlier models. Its strong benchmark performance suggests it is a valuable tool for researchers and practitioners working in artificial intelligence. As an open-source model, OpenThinker-32B encourages further exploration and innovation in reasoning-based AI systems.
Check out the Model on Hugging Face and Technical details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Meet OpenThinker-32B: A State-of-the-Art Open-Data Reasoning Model appeared first on MarkTechPost.
