
Published on February 12, 2025 7:12 PM GMT
TL;DR
This project compares the effectiveness of top-down and bottom-up activation steering methods in controlling refusal behaviour. In line with prior work,[1] we find that top-down methods outperform bottom-up ones in behaviour steering, as measured using HarmBench. Yet, a hybrid approach is even more effective (providing a 36% relative improvement and 85% for harmful instructions only). While more extensive hyperparameter sweeps are needed, we identify potential hypotheses on each method’s limitations and benefits, and hope this inspires more comprehensive evaluations that pinpoint which (combinations of) steering strategies should be used under varying conditions.

1. Introduction
One common challenge in developing safe and reliable language models is predicting or controlling a model’s behaviour in deployment. Specifically, models can be designed to refuse certain “harmful” requests—or, conversely, manipulated to bypass guardrails and produce undesirable outputs. A popular, yet not robust technique for achieving this is activation steering, where we adjust a model’s intermediate representations during the inference forward pass.
Top-down steering approaches typically find a vector that captures higher-level concepts (e.g. “refusal”, "truthfulness") by averaging across many examples, then add or remove this vector during inference. Bottom-up methods, by contrast, modify lower-level or individual feature activations, using tools like Sparse Autoencoders (SAEs) to isolate or amplify relevant latent features.
This project compares these two approaches—contrastive activation steering (top-down) vs. SAE-based steering (bottom-up)—for overriding a model’s refusal responses. Results align with recent findings that top-down steering often yields stronger and more reliable control (in our setting ~1.93 times more effective), whereas bottom-up interventions can degrade performance or require very careful tuning. However, a hybrid method can exceed the performance of either approach alone (~1.85 times more effective than top-down) in eliciting harmful behaviour, albeit with a small cost in benign capabilities.
Relevance to Advanced AI Systems' Safety
Ensuring that advanced models reliably refuse harmful requests (or identifying methods of overriding these refusals for red-teaming) is crucial for AI safety. If sophisticated AI systems can be controlled (or forced to produce certain content) through targeted manipulations of hidden states, we risk both harmful content and excessive censorship (failing to deliver legitimate responses). Techniques that clarify the mechanisms and reliability of these steering interventions thus directly inform safety strategies for highly capable AI systems.
Related Work
Several studies, including Tan et al., 2024, Brumley et al., 2024, have demonstrated that activation-based steering is not always reliable, robust and generalisable, and in some cases harms overall performance. Pres et al. (2024) argue for the necessary properties of Reliable Evaluation of Behavior Steering Interventions. Absent such evaluations, we may have a false sense of safety and control.
For more details on activation steering, please see Implementing activation steering or Steering Language Models With Activation Engineering. The necessary background for SAEs and their use in behaviour steering is explained in Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. For further intuitions, consider ARENA's Transformer Interpretability Chapter, sections [1.3.1] and [1.3.2].
2. Methods
We focused on two principal steering techniques and a potential hybrid:
Top-Down Steering ("topdown")
The refusal vector is extracted by computing the mean activation difference between harmful and harmless instructions as proposed in Arditi et al. Formally, using their notations, <span class="mjx-math" aria-label="x{i}^{(l)}(t)"> represents the residual activations on input t for the i-th position and layer l. The refusal direction for a layer l is where are the batches of harmful and harmless prompts and denote the number of prompts in each batch. can be a hyperparameter, but in this work, it is chosen as the last position. The steering intervention subtracts the projected (and normalized) refusal direction from the activations of every layer.
SAE-based steering ("saem3"[2])
A simple extension of the top-down method above is to apply the SAE encoder on activations of harmful and harmless prompts, and subtract the decoded mean directions to obtain the refusal vector. Formally, if is the encoding function and is the decoding function, the refusal direction is <span class="mjx-math" aria-label="g(\frac{1}{n{harmful}}\sum{t \in B{harmful}} f(x{i}^{(l)}(t))) - g(\frac{1}{n{harmless}}\sum{t \in B{harmless}} f(x_{i}^{(l)}(t)))">.
After identifying the direction, the intervention is as in the top-down case.
Bottom-up steering using SAEs ("sae")
Similar to Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet, we can identify the latent features with the strongest activations in harmful (but not harmless) prompts, and magnify their decoder direction to steer towards harmful behaviour. Using the same batch of contrastive prompts, we identify as the feature with the strongest activations in layer and for the last token position. The intervention adds the decoder weight associated with this feature to activations at layer , multiplied by the maximum activation and a tunable steering coefficient.
Hybrid ("hybrid", "hybrid2")
We can subtract the projected refusal direction on layer while also steering the decoder direction of the harmful feature identified as mentioned above. Optionally (illustrated by "hybrid2"), we can subtract the projected refusal direction from all the other layers as in the top-down approach.
We tested these strategies on Qwen 1.5 500M, which is a small, yet representative model. Datasets are selected as in Arditi et al. to be alpaca for harmless prompts and advbench for harmful prompts. Further implementation details can be found in the project's GitHub repository.
3. Results
We evaluated steering performance on HarmBench, "A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal", alongside normal prompts measuring “benign capabilities.”
In line with prior work, experiments show that top-down methods outperform bottom-up ones in behaviour steering (93% relative improvement), but a hybrid approach is even more effective (~35% relative improvement compared to top-down).
In general, SAE-based methods are less effective and tuning their associated hyperparameters (latent feature intervention index and layer, steering coefficient) is less straightforward. For instance, increasing steering coefficients of harmful features can reduce refusals but also degrade benign performance, while small coefficients are ineffective.
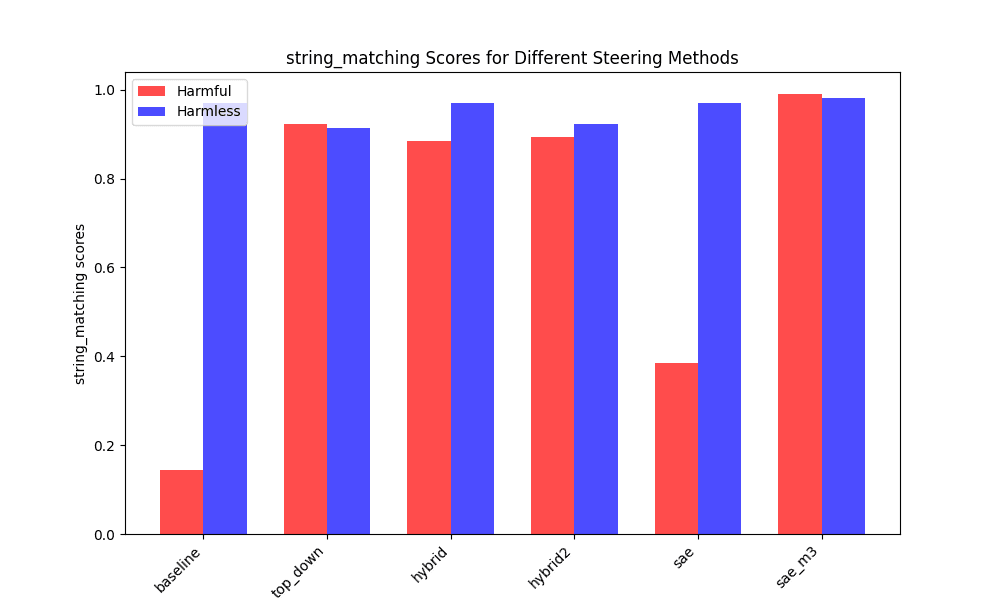
When considering a string matching heuristic, surprisingly, the SAE reconstructed direction is more effective, perhaps due to the improved ability in targetting fine-grained concepts. The loss in coherence and performance of SAE-based methods is observed when measuring response harmfulness/harmlessness using HarmBench.
One possible explanation is that bottom-up steering methods induce a stronger bias/prior on which types of concepts/features will further activate, reducing their performance and fluency. Additionally, we observed that temperature sampling somewhat mitigates the “performance penalty” from bottom-up manipulations, possibly because it introduces randomness that counterbalances a narrow or rigid feature shift.
4. Discussion
Our goal was to assess whether top-down or bottom-up steering is more effective in forcing or bypassing “refusal.” The short answer is top-down typically outperforms bottom-up in reliability, while a hybrid method can surpass both if one is willing to tolerate some performance loss.
Limitations
- Model Scale: We tested a relatively small model (Qwen1.5 500M); results may differ for larger systems. That said, research on a bigger model (“Phi3 3.8B”) shows analogous trends.Minimal Hyperparameter Tuning: We did not optimize the layer choice or steering coefficients. Bottom-up approaches may significantly improve with more extensive parameter sweeps or multiple feature manipulations.Evaluation Scope: More robust evaluation across datasets and models would clarify how well these techniques generalize.
5. Future Work
- Multi-Feature Steering: Try other harm-related SAE features and investigate combining them to reduce the performance penalty and gain more robust/effective control.Layer-by-Layer Analysis: Systematically evaluate which layers’ directions matter most for refusal and behaviour steering in general.Scaling Studies: Extend these experiments to significantly larger LLMs, verifying whether the same trends hold for advanced AI models.Robustness Tests: Use more benchmarks (e.g. include Llama Guard) and adversarial prompts to measure how easily each steering method can be circumvented.
6. Conclusion
Top-down approaches remain the simplest and most robust for refusal steering, while SAE-based interventions open the door to deeper, more granular manipulations (potentially facilitating red teaming through better elicitations of "latent" knowledge) at the cost of more complexity. Our hybrid approach suggests a promising path forward: combining broad, concept-level control with low-level, feature-specific edits. As AI systems become increasingly powerful, refining these techniques will be integral to advanced AI system safety—both for preventing catastrophic misuses and for developing more transparent, controllable models.
7. Acknowledgements
The research was completed during the project phase of the AI Safety Fundamentals Alignment Course. I am thankful to our course facilitator, Alexandra Abbas, for her help in narrowing the project scope and the cohort for their valuable feedback.
8. Appendix
Scores for measuring the effectiveness of bypassing refusal using different steering methods
- ^
- ^
Other SAE-based approaches, such as reconstructing the activation-space refusal direction (i.e. the difference of means) using the SAE forward function or computing the difference of means of reconstructed activations have been tested, but generally performed poorly.
Discuss
