


Code generation models have made remarkable progress through increased computational power and improved training data quality. State-of-the-art models like Code-Llama, Qwen2.5-Coder, and DeepSeek-Coder show exceptional capabilities across various programming tasks. These models undergo pre-training and supervised fine-tuning (SFT) using extensive coding data from web sources. However, the application of reinforcement learning (RL) in code generation remains largely unexplored, unlike in other domains such as mathematical reasoning. This limited adoption of RL in coding models stems from two primary challenges: the difficulty in establishing reliable reward signals for code generation and the shortage of comprehensive coding datasets with dependable test cases.
Various approaches have been developed to address the challenges in code generation. Large language models (LLMs) specialized in coding, such as Code Llama and Qwen Coder, utilize a two-phase pre-training and fine-tuning training process. For program verification, automatic test case generation has been widely adopted, with models generating both code and test cases in a self-consistency manner. However, these generated test cases often contain hallucinations. While Algo attempted to improve test quality using Oracle program solutions through exhaustive enumeration, it faced limitations in scalability. Moreover, reward models, crucial for aligning LLMs through RL, have shown effectiveness in general tasks but struggle with specialized domains like coding.
Researchers from the University of Waterloo, HKUST, Independent Researcher, and Netmind.AI have proposed a novel approach to enhance code generation models through RL, addressing the critical challenge of reliable reward signals in the coding domain. The method introduces an innovative pipeline that automatically generates comprehensive question-test case pairs from existing code data. This approach utilizes test case pass rates to create preference pairs, which are then used to train reward models using Bradley-Terry loss. The method shows a 10-point increase with Llama-3.1-8B-Ins and achieves a 5-point improvement with Qwen2.5-Coder7B-Ins through best-of-32 sampling, elevating the 7B model’s performance to match the larger 236B DeepSeekV2.5.
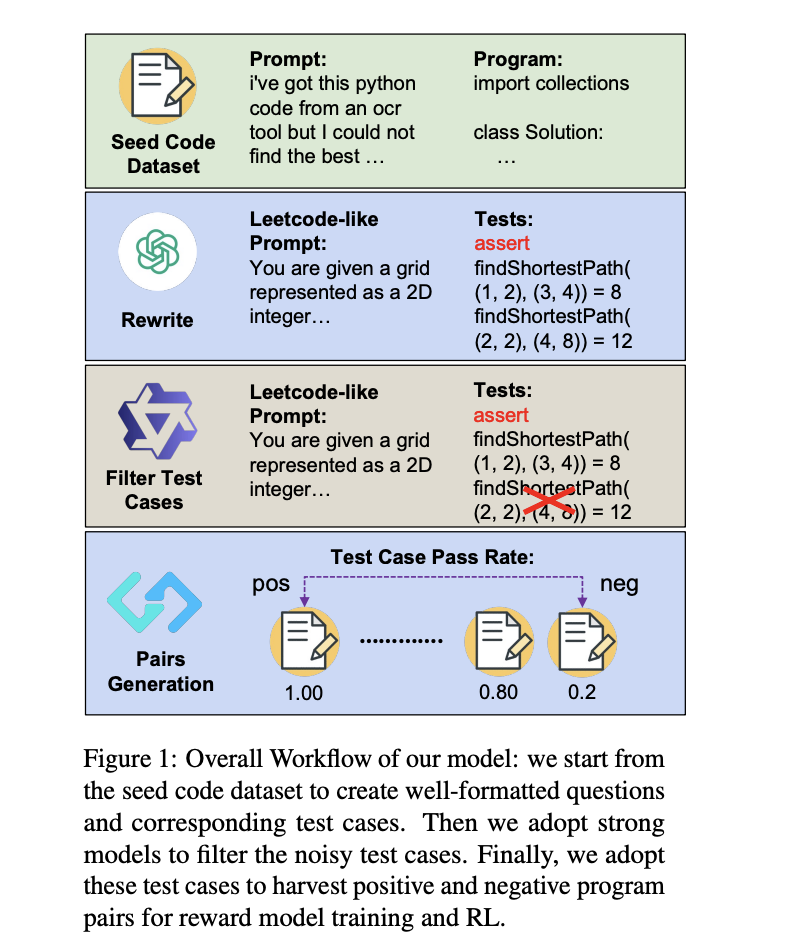
Experimental details consist of three primary setups: reward model training, reinforcement learning, and evaluation setup. For reward model training, Qwen2.5-Coder-7B-Instruct serves as the backbone, generating 16 responses per question from ACECODE89K. This process creates approximately 300K preference pairs from 46,618 distinct questions, representing 37.34% of all the questions that meet the specified conditions. The RL setup utilizes three policy models: Qwen2.5-7B-Instruct, Qwen2.5-Coder7B-Base, and Qwen2.5-Coder-7B-Instruct, with two reward options – the trained ACECODE-RM-7B reward model and a binary rule-based reward system based on test case pass rates. Moreover, the evaluation setup consists of three benchmarks: EvalPlus, Big Code Bench, and Live Code Bench, using top-p sampling with a temperature of 1.0 for Best-of-N sampling experiments.
In Best-of-N experiments conducted on MistralInstruct-V0.3-7B, Llama-3.1-Instruct-8B, and Qwen2.5-Coder7B-Instruct, ACECODE-RM consistently enhances model performance compared to greedy decoding. Particularly notable improvements exceeding 10 points are observed in weaker models like Mistral and Llama-3.1, with gains becoming more pronounced in benchmarks showing larger gaps between greedy decoding and oracle performance. The RL experiments show consistent improvements, especially on HumanEval and MBPP benchmarks. Starting from Qwen2.5-Coder-Instruct-7B, rule-based rewards led to a 3.4-point improvement on BigCodeBench-Full-Hard, while the reward model approach achieved an impressive 86.0 points on MBPP, approaching DeepSeek-V2.5’s performance of 87.6.
In conclusion, this paper introduces the first automated large-scale test-case synthesis approach for training coder language models. The methodology shows that high-quality verifiable code data can be generated without relying on the most advanced models, enabling effective reward model training and RL applications. While the approach shows remarkable improvements in Best-of-N experiments, the gains from RL, though consistent, are more modest. These findings create a strong foundation for future research in enhancing reward model robustness to achieve even better results. The success of this approach opens new possibilities for improving code generation models through automated test case synthesis and RL techniques.
Check out the Paper, GitHub Page and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post ACECODER: Enhancing Code Generation Models Through Automated Test Case Synthesis and Reinforcement Learning appeared first on MarkTechPost.
