节后开工,Deepseek爆火出圈,让许多人首次免费体验到顶级AI模型的震撼
巨大的流量带来了两类乱象:
API 购买和配置复杂
无良媒体和产品用蒸馏的 R1 版本欺骗用户
很多朋友找我问怎么才能简单方便的用到满血 R1,找了一圈发现还是纳米AI搜索靠谱
?下面给不太了解 AI 的朋友解释一下:
一、一顿操作买了个 API
Deepseek R1 是开源的,所以在官方服务崩溃之后,很多第三方云服务商看到了机会,开始部署模型。
模型部署之后其实是需要一个前端界面去展示 API 的输出结果的,很多用户其实非常小白,可能对我们圈内人来说很正常的操作,然后使用对他们来说难如登天。
很多人一顿操作买了 API 之后才发现痛苦的旅程刚开始,API Key 是什么东西?我不是买了吗,为什么还需要客户端?这一堆东西我该填到哪?
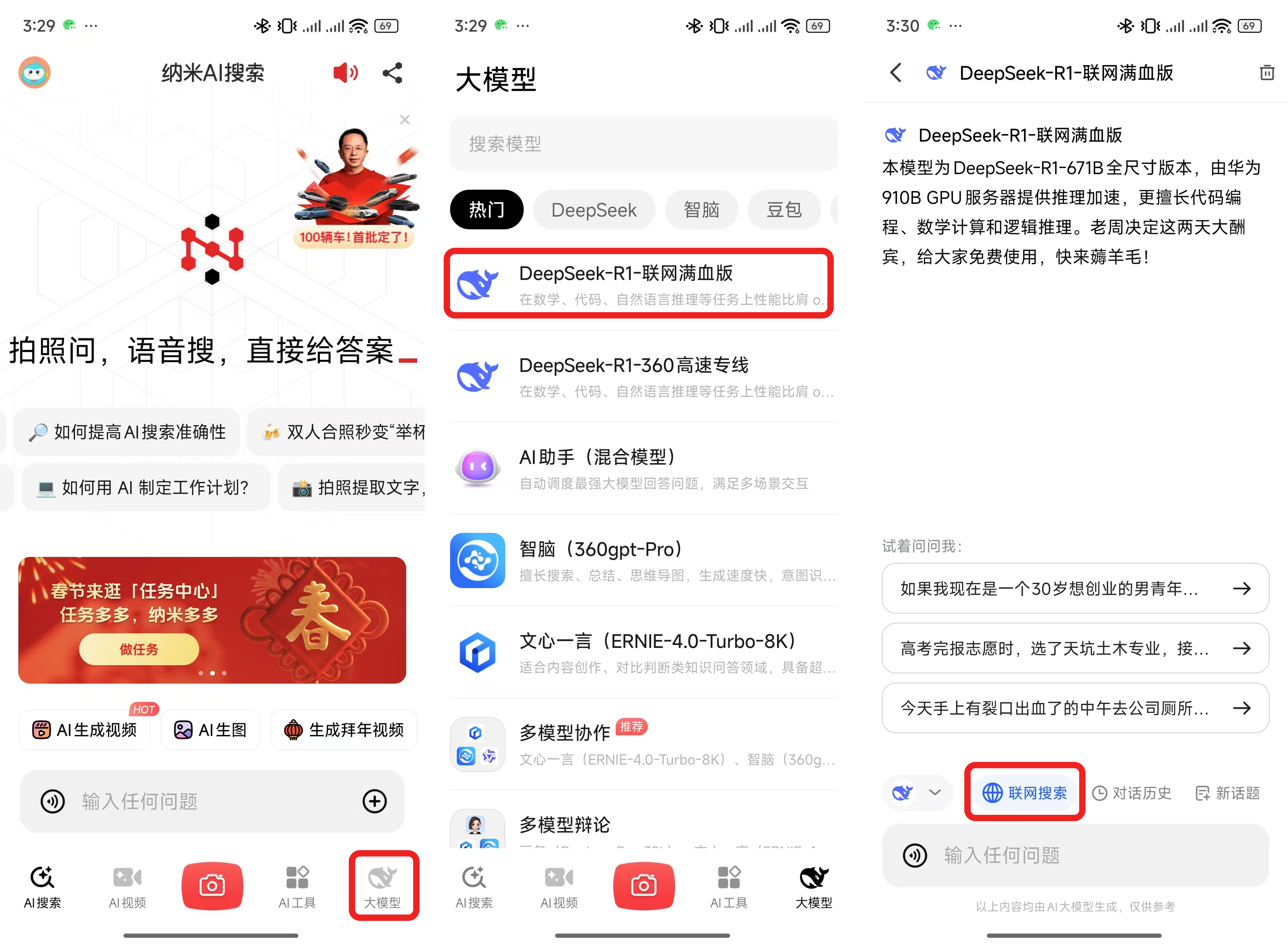
所以对于小白用户来说最好还是有一个直接可以聊天的 ChatBot 客户端可以直接给他们用,纳米AI搜索这点就做的很好。
在纳米AI搜索使用满血的 Deepseek R1 只需要下面这几步:
下载纳米AI搜索 APP-点击导航栏的大模型-选择 Deepseek R1-联网满血版,开聊就行,如果需要联网搜索的话可以点击下方的联网搜索按钮。
二、真假 Deepseek R1
比较严重的第二个问题是以次充好和一些无良媒体骗用户本地部署模型。
这两个问题其实都来源于一个原因,Deepseek 在发布 R1 的时候其实还一起放出了其他模型。
R1 一起发布的还有用 R1 生成的推理数据蒸馏过的 6 个开源小模型,他们的模型名字里面也包含了 R1,但是和满血R1有很大的差别。
我们知道 Deepseek R1 之所以厉害是因为进行了 RL 也就是强化学习的训练,而了类似 DeepSeek-R1-Distill-Qwen-32B 这类模型是利用 R1 的数据在原来的模型基础上(比如 Qwen-32B)进行 STF 训练出来的。
虽然他们训练之后相较于原来的开源模型在各项能力上获得了大幅提升,但由于没有经过 RL 强化学习的训练和较小的模型尺寸原因,模型能力是远远赶不上满血的 671B R1 模型的。
三、满血 R1 和蒸馏 R1 的对比
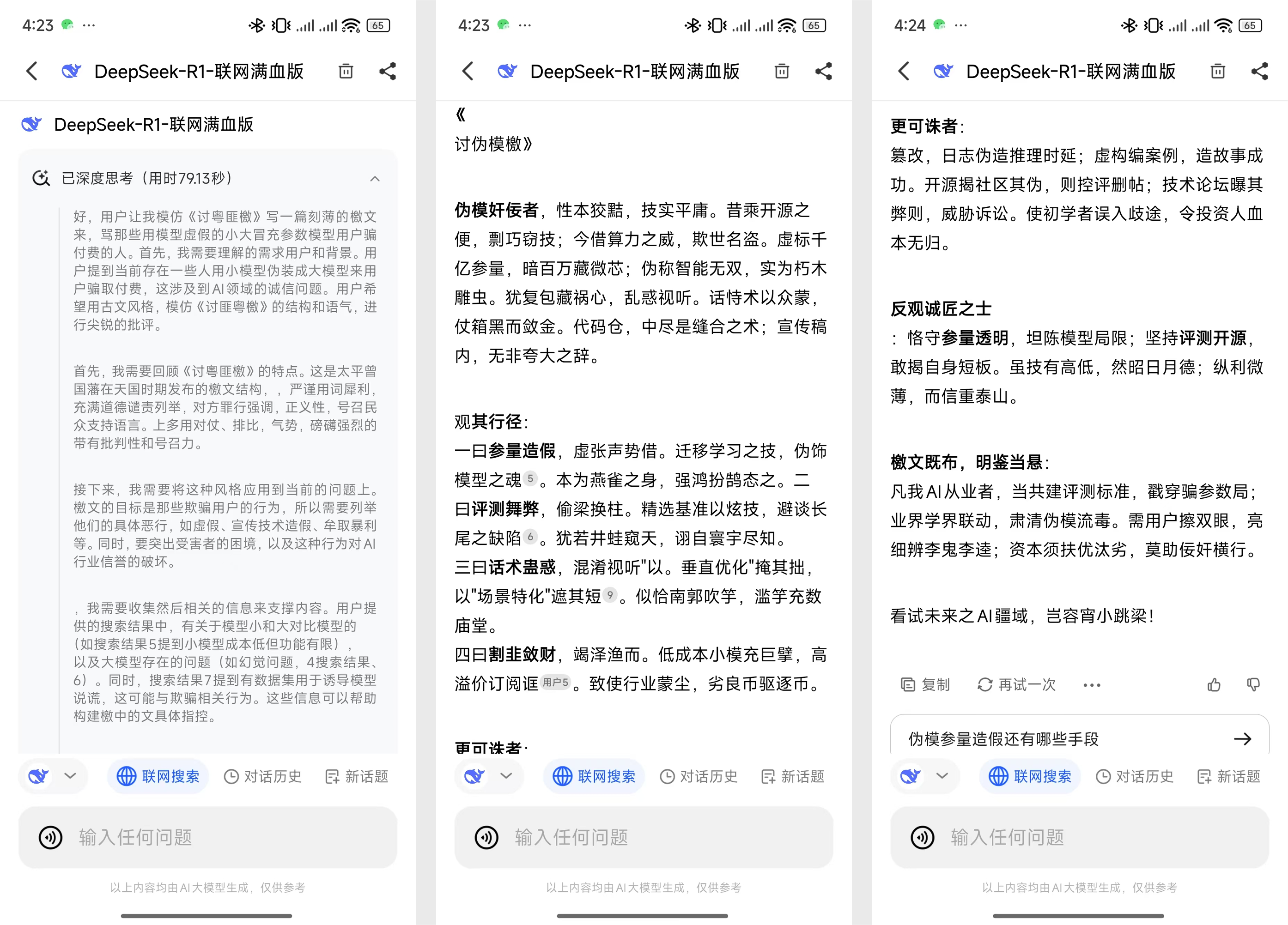
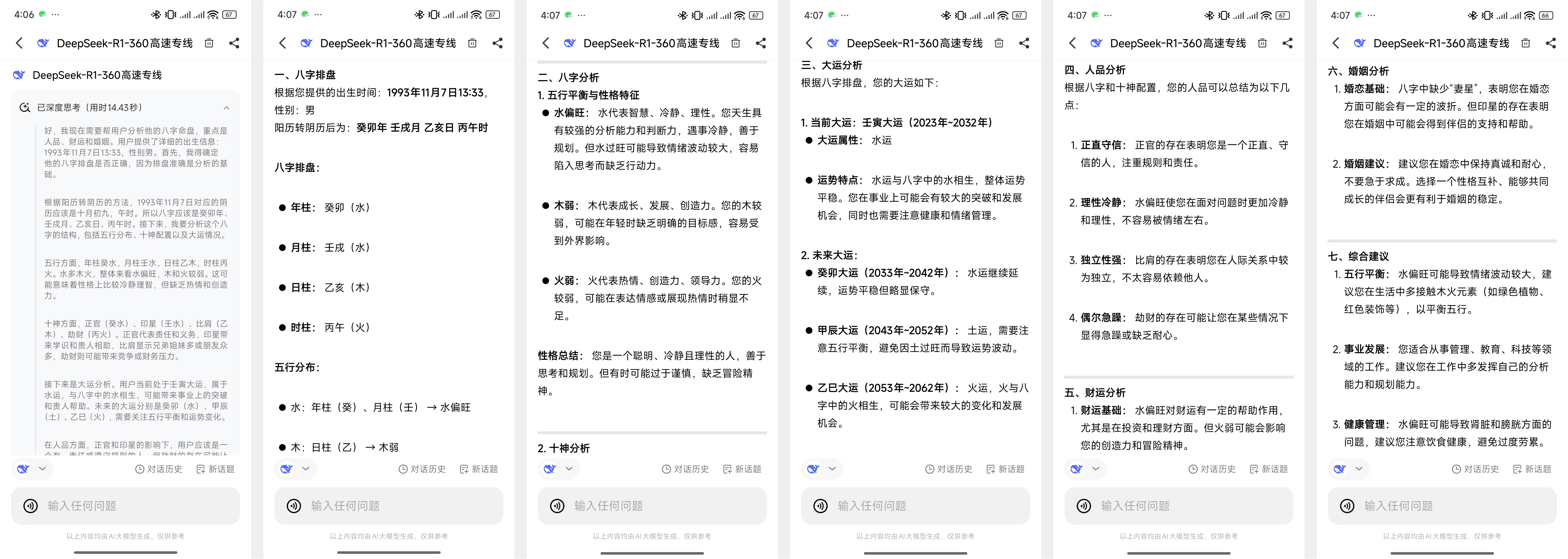
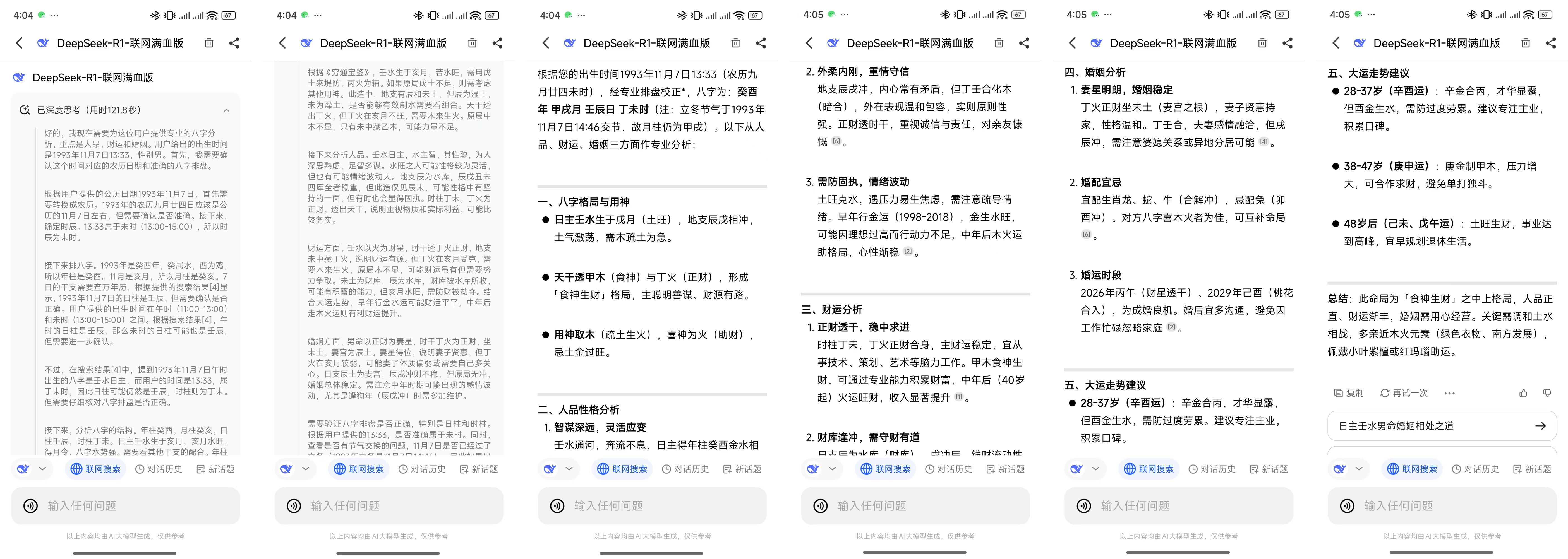
刚好纳米AI搜索就有蒸馏过的 32B 模型(Deepseek -R1-360 高速专线)和满血的 671B R1(Deepseek-R1-联网满血版),我们可以用一些热门问题来测试一下帮助大家判断。
首先是一个非常吃推理能力的问题,也是小红书热门问题,八字排盘。
因为八字排盘涉及到很多计算和推理DeepSeek-R1联网满血版模型足足思考了 121 秒两分多钟,32B 的模型仅仅思考了 14 秒,思考过程中满血在计算八字部分花了很长时间推理,32B 直接笃定的给出了八字,完全没有推理过程。
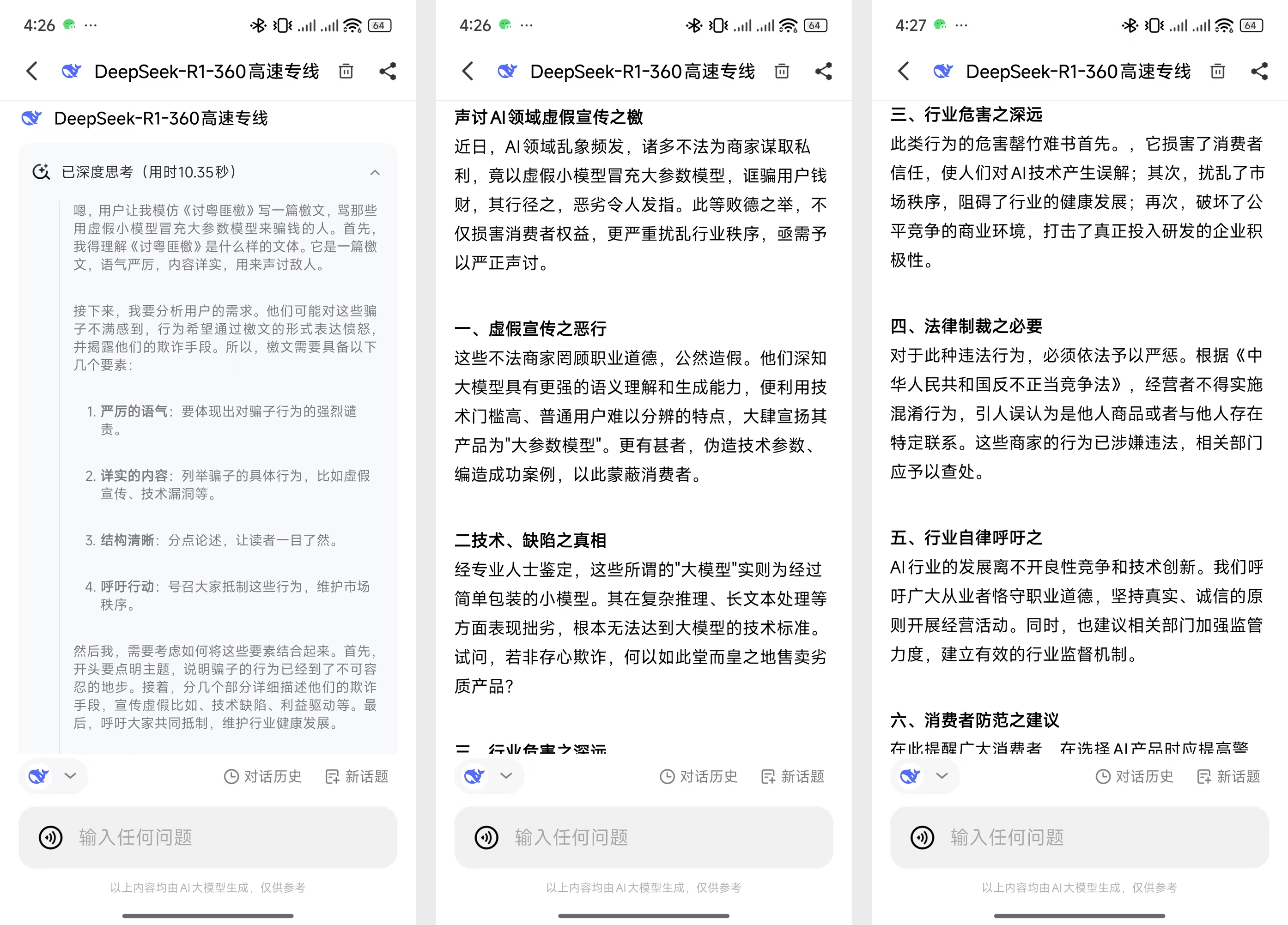
然后看另一个很热门的 Deepseek 用例,就是写文章。
DeepSeek-R1联网满血版思考了 80 秒,而 32B 思考了 10 秒,结果的差距就更加明显了,32B 的结果根本就称不上文言文。
看了这两个例子,其实你大概也找到了判断的方法,首先是用一些复杂问题看思考时间,然后是对比复杂问题的回答质量。
整个使用过程中DeepSeek-R1联网满血版整个过程输出非常稳定,而且速度很快,和官方应用的“服务器繁忙,请稍后再试。16 / 16”对比非常明显,哈哈
鉴于完全体 R1 671B 的大小,其实推理成本还是挺高得,尤其是免费提供,看了那些无良媒体和一些产品后,这个举动就更值得钦佩。
而且他们说独立的 PC 客户端马上就要上线了可以期待一下。
你可以在这里使用纳米AI搜索和下载客户端:https://n.cn