
What's up friends, Alex here, back with another ThursdAI hot off the presses.
Hold onto your hats because this week was another whirlwind of AI breakthroughs, mind-blowing demos, and straight-up game-changers. We dove deep into OpenAI's new "Deep Research" agent – and let me tell you, it's not just hype, it's legitimately revolutionary. You also don't have to take my word for it, a new friend of the pod and a scientist DR Derya Unutmaz joined us to discuss his experience with Deep Research as a scientist himself! You don't want to miss this conversation!
We also unpack Google's Gemini 2.0 release, including the blazing-fast Flash Lite model. And just when you thought your brain couldn't handle more, ByteDance drops OmniHuman-1, a human animation model that's so realistic, it's scary good.
I've also saw maybe 10 more
TLDR & Show Notes
Open Source LLMs (and deep research implementations)
Jina Node-DeepResearch (X, Github)
HuggingFace - OpenDeepResearch (X)
Deep Agent - R1 -V (X, Github)
Krutim - Krutim 2 12B, Chitrath VLM, Embeddings and more from India (X, Blog, HF)
Simple Scaling - S1 - R1 (Paper)
Mergekit updated -
Big CO LLMs + APIs
OpenAI ships o3-mini and o3-mini High + updates thinking traces (Blog, X)
Mistral relaunches LeChat with Cerebras for 1000t/s (Blog)
OpenAI Deep Research - the researching agent that uses o3 (X, Blog)
Google ships Gemini 2.0 Pro, Gemini 2.0 Flash-lite in AI Studio (Blog)
Anthropic Constitutional Classifiers - announced a universal jailbreak prevention (Blog, Try It)
Cloudflare to protect websites from AI scraping (News)
HuggingFace becomes the AI Appstore (link)
This weeks Buzz - Weights & Biases updates
AI Engineer workshop (Saturday 22)
Tinkerers Toronto workshops (Sunday 23 , Monday 24)
We released a new Dataset editor feature (X)
Audio and Sound
AI Art & Diffusion & 3D
ByteDance OmniHuman-1 - unparalleled Human Animation Models (X, Page)
Pika labs adds PikaAdditions - adding anything to existing video (X)
Google added Imagen3 to their API (Blog)
Tools & Others
Mistral Le Chat has ios an and adroid apps now (X)
CoPilot now has agentic workflows (X)
Replit launches free apps agent for everyone (X)
Karpathy drops a new 3 hour video on youtube (X, Youtube)
OpenAI canvas links are now shareable (like Anthropic artifacts) - (example)
Show Notes & Links
Guest of the week - Dr Derya Umnutaz - talking about Deep Research
He's examples of Ehlers-Danlos Syndrome (ChatGPT), (ME/CFS) Deep Research, Nature article about Deep Reseach with Derya comments
Hosts
Alex Volkov - AI Evangelist & Host @altryne
Wolfram Ravenwolf - AI Evangelist @WolframRvnwlf
Nisten Tahiraj - AI Dev at github.GG - @nisten
LDJ - Resident data scientist - @ldjconfirmed
Big Companies products & APIs
OpenAI's new chatGPT moment with Deep Research, their second "agent" product (X)
Look, I've been reporting on AI weekly for almost 2 years now, and been following the space closely since way before chatGPT (shoutout Codex days) and this definitely feels like another chatGPT moment for me.
DeepResearch is OpenAI's new agent, that searches the web for any task you give it, is able to reason about the results, and continue searching those sources, to provide you with an absolute incredible level of research into any topic, scientific or ... the best taqueria in another country.
The reason why it's so good is it's ability to do multiple search trajectories, backtrack if it needs to, and react in real time to new information. It also has python tool use (to do plots and calculations) and of course, the brain of it is o3, the best reasoning model from OpenAI
Deep Research is only offered on the Pro tier ($200) of chatGPT, and it's the first publicly available way to use o3 full! and boy, does it deliver!
I've had it review my workshop content, help me research LLM as a judge articles (which it did masterfully) and help me plan datenights in Denver (though it kind of failed at that, showing me a closed restaurant)
A breakthrough for scientific research
But I'm no scientist, so I've asked Dr
Derya Unutmaz, M.D.
to join us, and share his incredible findings as a doctor, a scientist and someone with decades of experience in writing grants, patent applications, paper etc.
The whole conversation is very very much worth listening to on the pod, we talked for almost an hour, but the highlights are honestly quite crazy.
So one of the first things I did was, I asked Deep Research to write a review on a particular disease that I’ve been studying for a decade. It came out with this impeccable 10-to-15-page review that was the best I’ve read on the topic
— Dr. Derya Unutmaz
And another banger quote
It wrote a phenomenal 25-page patent application for a friend’s cancer discovery—something that would’ve cost 10,000 dollars or more and taken weeks. I couldn’t believe it. Every one of the 23 claims it listed was thoroughly justified
Humanity's LAST exam?
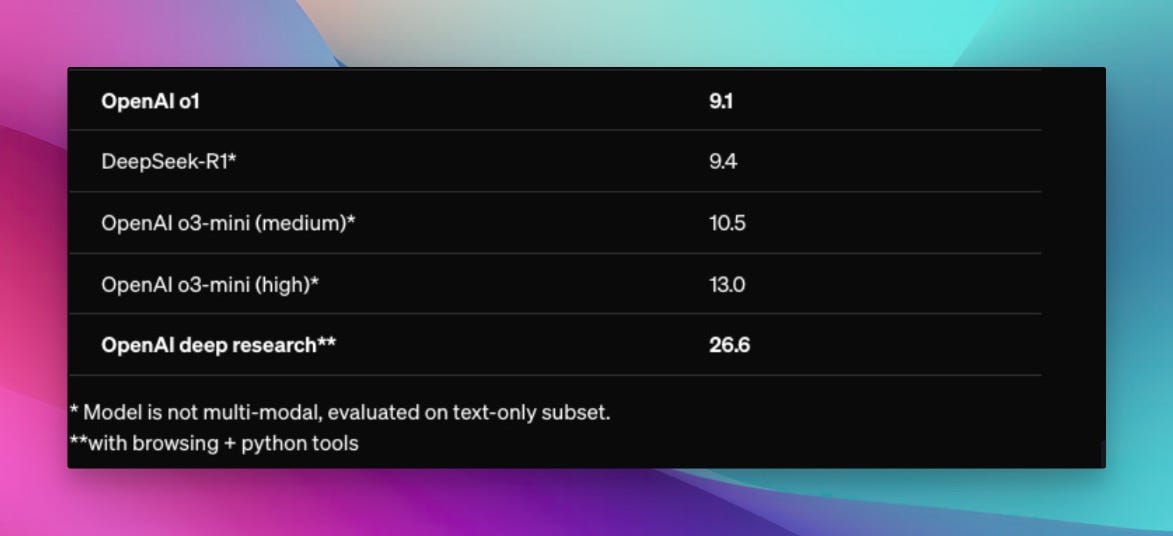
OpenAI announced Deep Research and have showed that on HLE (Humanity's Last Exam) benchmark that was just released a few weeks ago, it scores a whopping 26.6 percent! When HLE was released (our coverage here) all the way back at ... checks notes... January 23 or this year! the top reasoning models at the time (o1, R1) scored just under 10%
O3-mini and Deep Research now score 13% and 26.6% respectively, which means both that AI is advancing like crazy, but also.. that maybe calling this "last exam" was a bit premature? ??
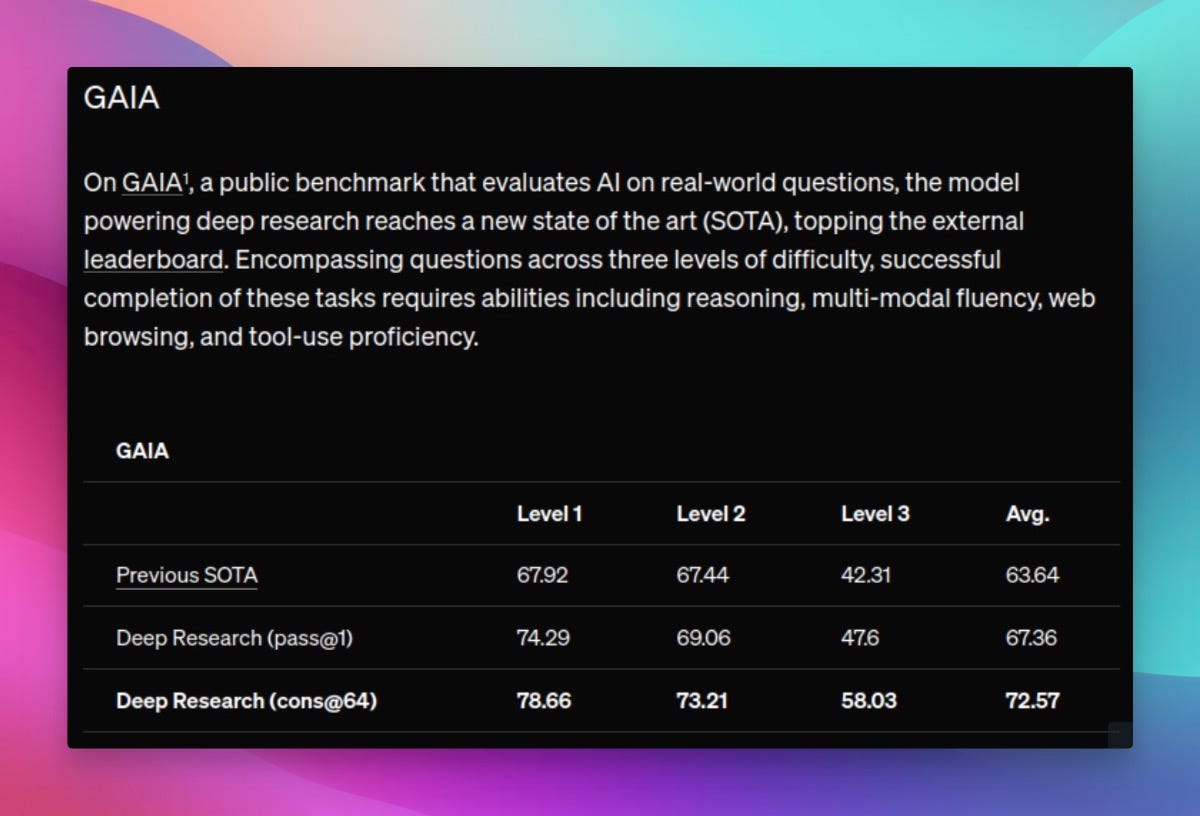
Deep Research is now also SOTA holder on GAIA, a public benchmark on real world questions, though Clementine (one of GAIA authors) throws a bit of shade on the result since OpenAI didn't really submit their results. Incidently, Clementine is also involved in HuggingFace attempt at replicating Deep Research in the open (with OpenDeepResearch)
OpenAI releases o3-mini and o3-mini high
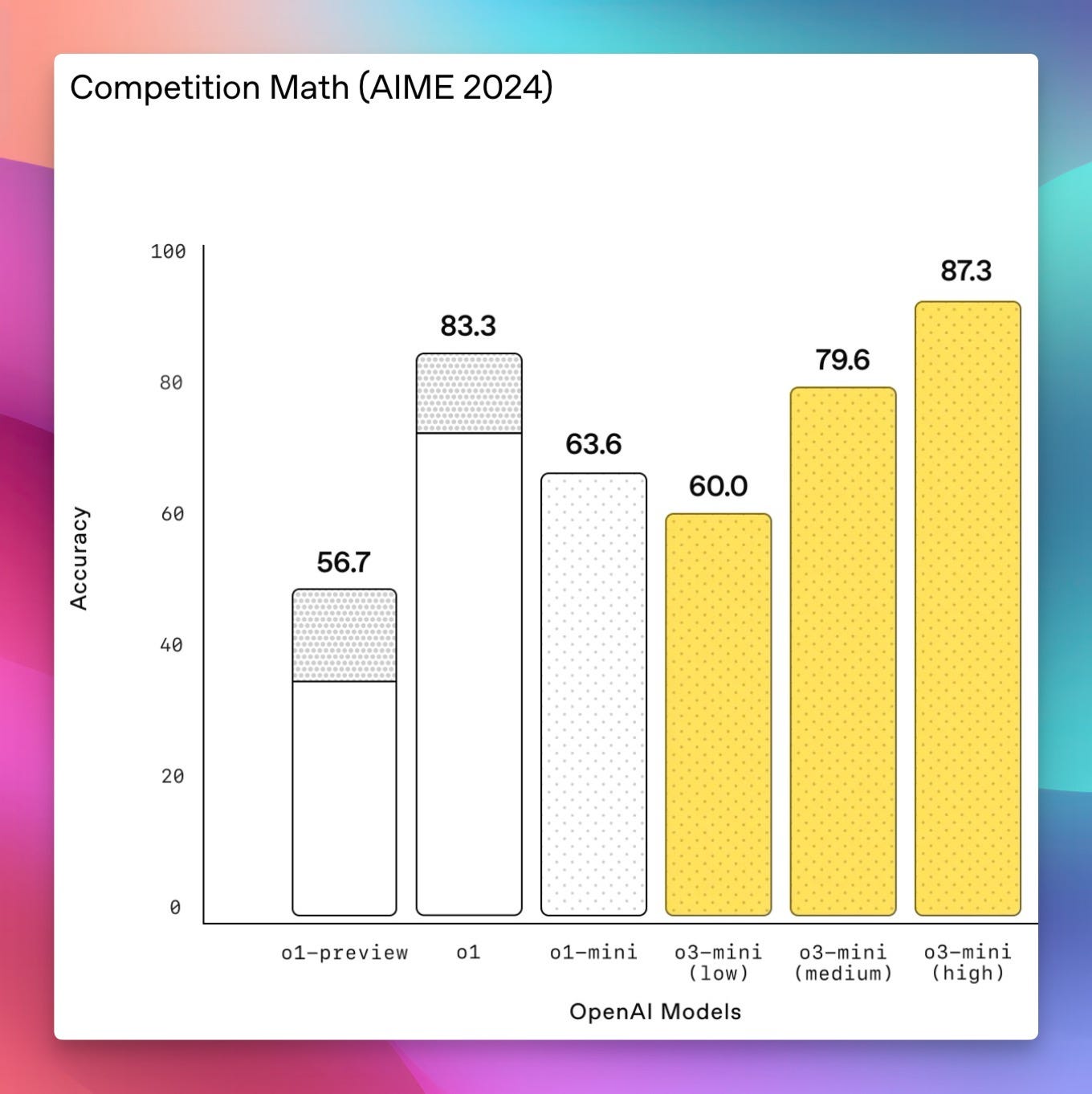
This honestly got kind of buried with the Deep Research news, but as promised, on the last day of January, OpenAI released their new reasoning model, which is significantly fast and much cheaper than o1, while matching it on most benchmarks!
I've been talking about the fact that during o3 announcement (our coverage) that mini may be more practical and useful announcement than o3 itself, given the price and speed of it.
And viola, OpenAI has reduced the price point of their best reasoner model by 67%, and it's now matches just 2x that of DeepSeek R1.
Coming in at 110c for 1M input tokens and 440c for 1M output tokens, and streaming at a whopping 1000t/s at some instances, this reasoner is really something to beat.
Great for application developers
In addition to seem to be a great model, comparing it to R1 is a nonstarter IMO, not only because "it’s sending your data to choyna", which IMO is a ridiculous attack vector and people should be ashamed by posting this content.
o3-mini supports all of the nice API things that OpenAI has, like tool use, structured outputs, developer messages and streaming. The ability to set the reasoning effort is also interesting for applications!
Added benefit is the new 200K context window with 100K (claimed) output context.
It's also really really fast, while R1 availability grows, as it gets hosted on more and more US based providers, none of them are offering the full context window at these token speeds.
o3-mini-high?!
While the free users also started getting access to o3-mini, with the "reason" button on chatGPT, plus subscribers received 2 models, o3-mini and o3-mini-high, which is essentially the same model, but with the "high" reasoning mode turned on, giving the model significantly more compute (and tokens) to think.
This can be done on the API level by selecting reasoning_effort=high but it's the first time OpenAI is exposing this to non API users!
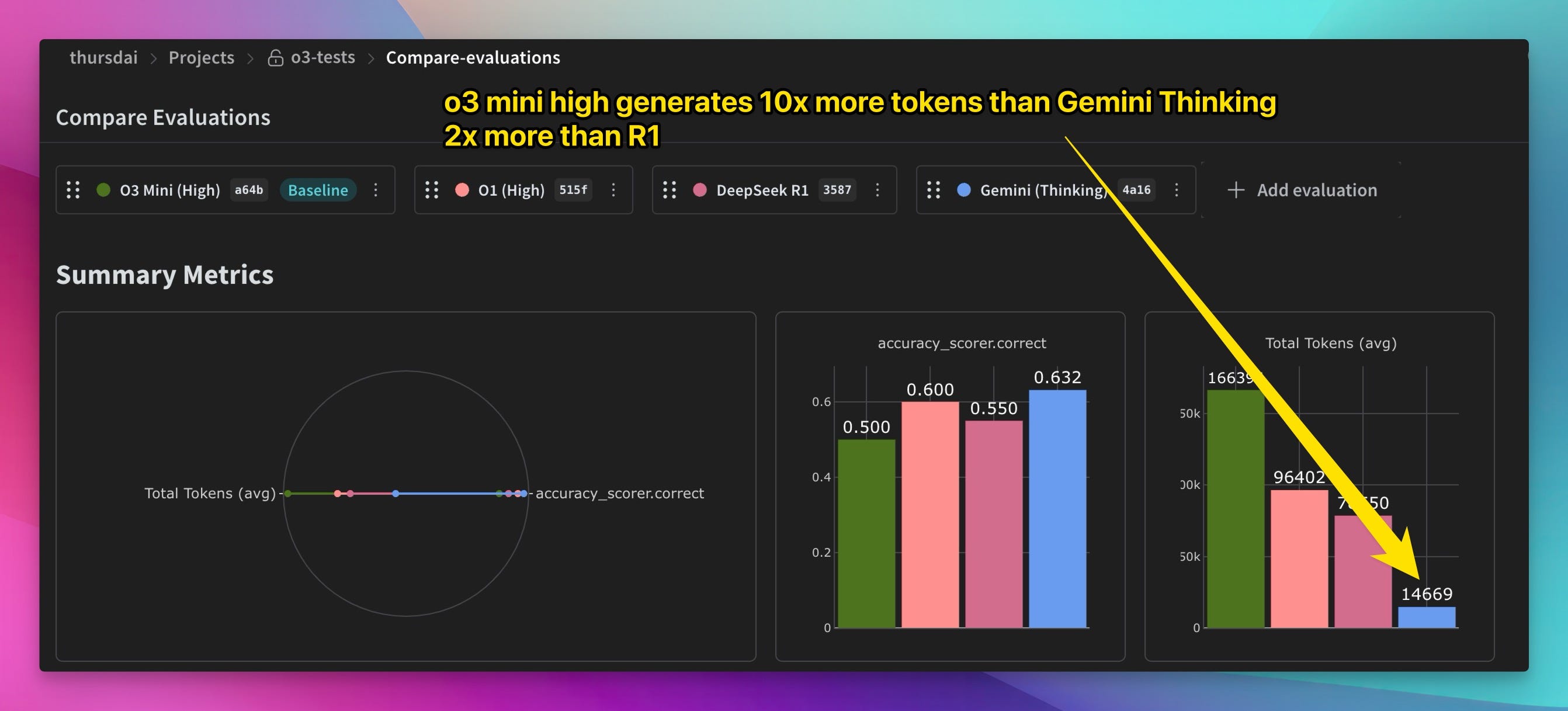
One highlight for me is, just how MANY tokens o3-mini high things through. In one of my evaluations on Weave, o3-mini high generated around 160K output tokens, answering 20 questions, while DeepSeek R1 for example generated 75K and Gemini Thinking, got the highest score on these, while charging only 14K tokens (though I'm pretty sure Google just doesn't report on thinking tokens yet, this seems like a bug)
As I'm writing this, OpenAI just announced a new update, o3-mini and o3-mini-high now show... "updated" reasoning traces!
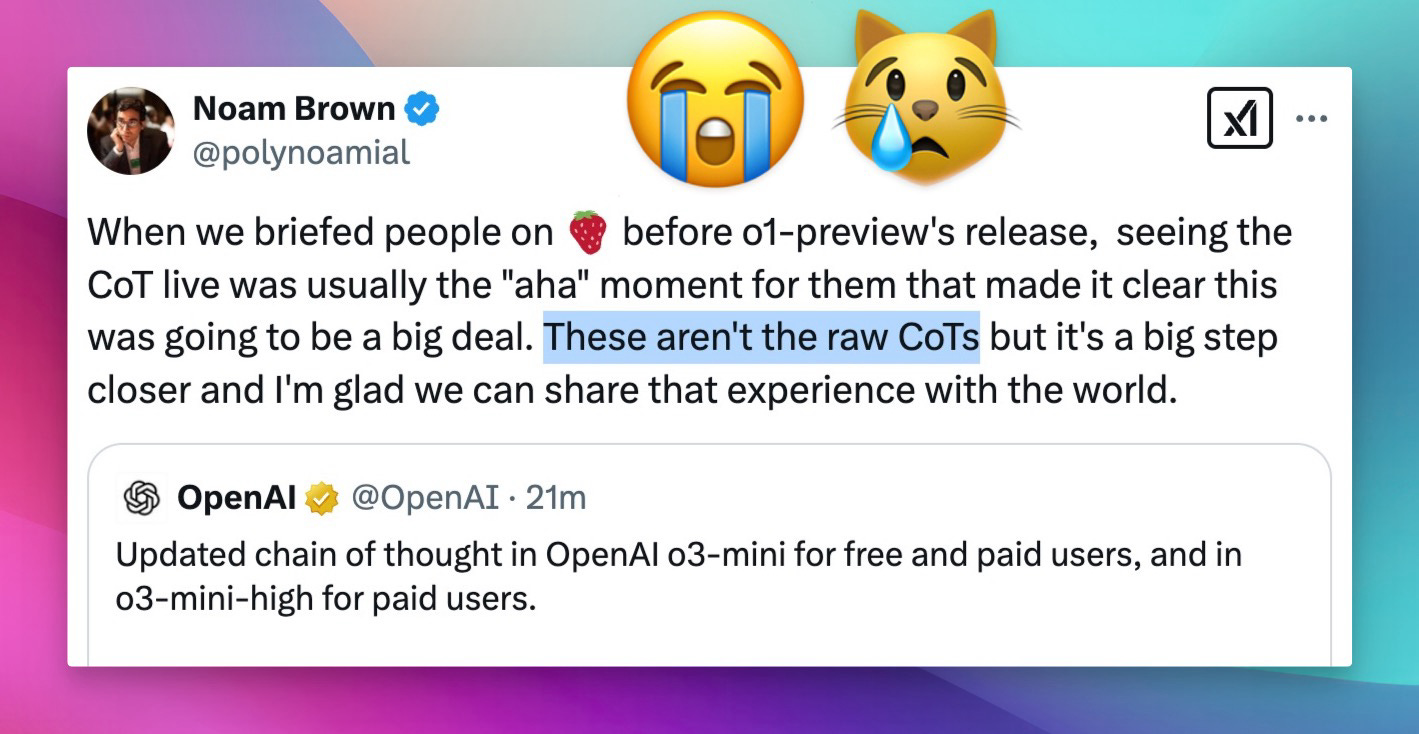
These definitely "feel" more like the R1 reasoning traces (remember, previously OpenAI had a different model summarizing the reasoning to prevent training on them?) but they are not really the RAW ones (confirmed)
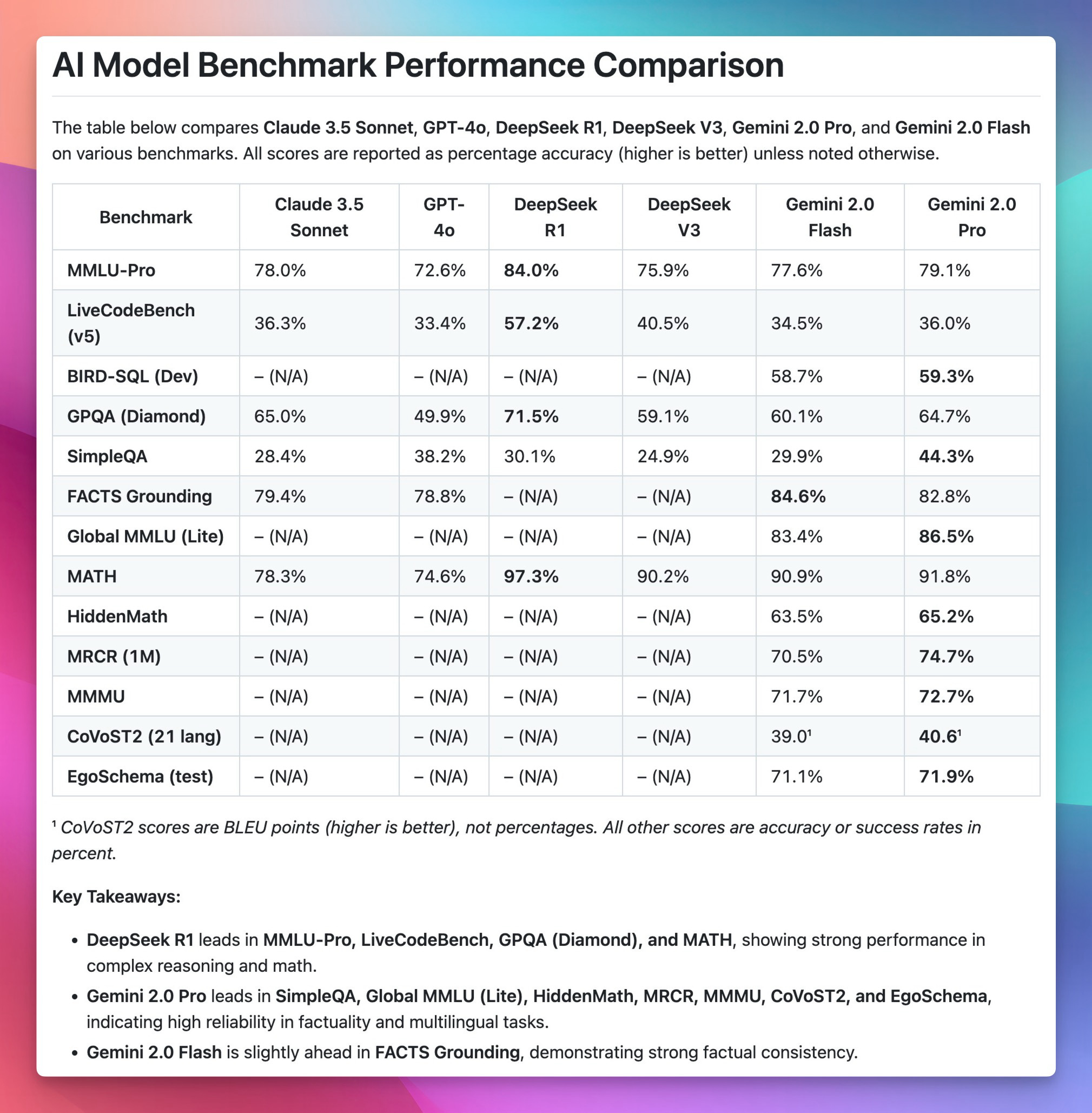
Google ships Gemini 2.0 Pro, Gemini 2.0 Flash-lite in AI Studio (X, Blog)
Congrats to our friends at Google for 2.0 ? Google finally put all the experimental models under one 2.0 umbrella, giving us Gemini 2.0, Gemini 2.0 Flash and a new model!
They also introduced Gemini 2.0 Flash-lite, a crazy fast and cheap model that performs similarly to Flash 1.5. The rate limits on Flash-lite are twice as high as the regular Flash, making it incredibly useful for real-time applications.
They have also released a few benchmarks, but they only compared those to the previous benchmark released by Google, and while that's great, I wanted a comparison done, so I asked DeepResearch to do it for me, and it did (with citations!)
Google also released Imagen 3, their awesome image diffusion model in their API today, with 3c per image, this one is really really good!
Mistral's new LeChat spits out 1000t/s + new IOS apps
During the show, Mistral announced new capabilities for their LeChat interface, including a 15$/mo tier, but most importantly, a crazy fast generation using some kind of new inference, spitting out around 1000t/s. (Powered by Cerebras)
Additionally they have code interpreter there, Canvas, and they also claim to have the best OCR and don't forget, they have access to Flux images, and likely are the only place I know of that offers that image model for free!
Finally, they've released native mobile apps! (IOS, Android)
* from my quick tests, the 1000t/s is not always on, my first attempt was instant, it was like black magic, and then the rest of them were pretty much the same speed as before ? Maybe they are getting hammered in traffic...
This weeks Buzz (What I learned with WandB this week)
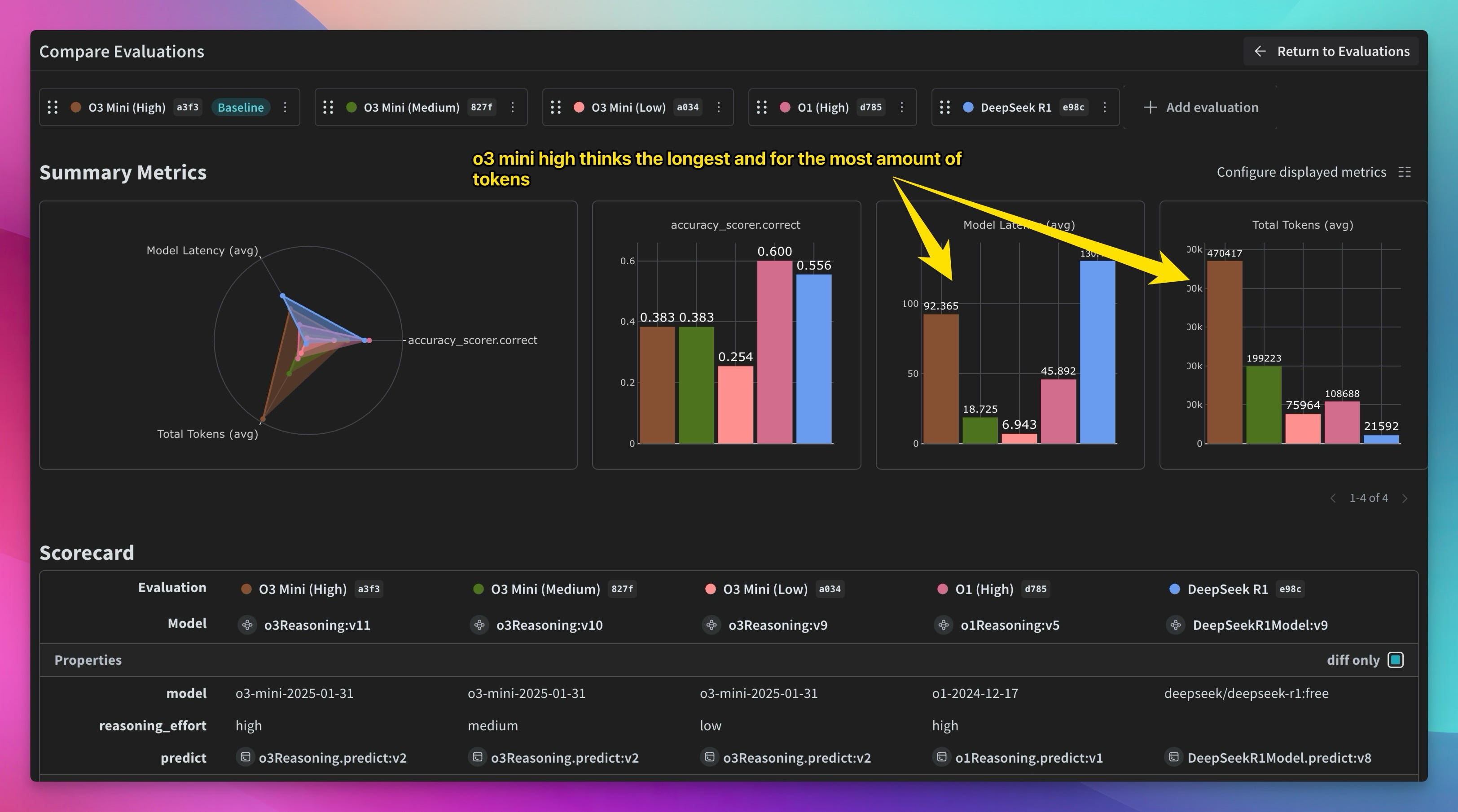
I got to play around with O3-Mini before it was released (perks of working at Weights & Biases!), and I used Weave, our observability and evaluation framework, to analyze its performance. The results were… interesting.
Latency and Token Count: O3-Mini High's latency was six times longer than O3-Mini Low on a simple reasoning benchmark (92 seconds vs. 6 seconds). But here's the kicker: it didn't even answer more questions correctly! And the token count? O3-Mini High used half a million tokens to answer 20 questions three times. That's… a lot.
Weave Leaderboards: Nisten got super excited about using Weave's leaderboard feature to benchmark models. He realized it could solve a real problem in the open-source community – providing a verifiable and transparent way to share benchmark results. (really, we didnt' rehearse this!)
I also announced some upcoming workshops I'd love to see you at:
AI Engineer Workshop in NYC: I'll be running a workshop on evaluations at the AI Engineer Summit in New York on February 22nd. Come say hi and learn about evals!
AI Tinkerers Workshops in Toronto: I'll also be doing two workshops with AI Tinkerers in Toronto on February 23rd and 24th.
ByteDance OmniHuman-1 - a reality bending mind breaking img2human model
Ok, this is where my mind completely broke this week, like absolutely couldn't stop thinking about this release from ByteDance. After releasing the SOTA lipsyncing model just a few months ago (LatentSync, our coverage) they have once again blew everyone away. This time with a img2avatar model that's unlike anything we've ever seen.
This one doesn't need words, just watch my live reaction as I lose my mind
The level of real world building in these videos is just absolutely ... too much? The piano keys moving, there's a video of a woman speaking in the microphone, and behind her, the window has reflections of cars and people moving!
The thing that most blew me away upon review was the Niki Glazer video, with shiny dress and the model almost perfectly replicating the right sources of light.
Just absolute sorcery!
The authors confirmed that they don't have any immediate plans to release this as a model or even a product, but given the speed of open source, we'll get this within a year for sure! Get ready
Open Source LLMs (and deep research implementations)
This week wasn't massive for open-source releases in terms of entirely new models, but the ripple effects of DeepSeek's R1 are still being felt. The community is buzzing with attempts to replicate and build upon its groundbreaking reasoning capabilities. It feels like everyone is scrambling to figure out the "secret sauce" behind R1's "aha moment," and we're seeing some fascinating results.
Jina Node-DeepResearch and HuggingFace OpenDeepResearch
The community wasted no time trying to replicate OpenAI's Deep Research agent.
Jina AI released "Node-DeepResearch" (X, Github), claiming it follows the "query, search, read, reason, repeat" formula. As I mentioned on the show, "I believe that they're wrong" about it being just a simple loop. O3 is likely a fine-tuned model, but still, it's awesome to see the open-source community tackling this so quickly!
Hugging Face also announced "OpenDeepResearch" (X), aiming to create a truly open research agent. Clementine Fourrier, one of the authors behind the GAIA benchmark (which measures research agent capabilities), is involved, so this is definitely one to watch.
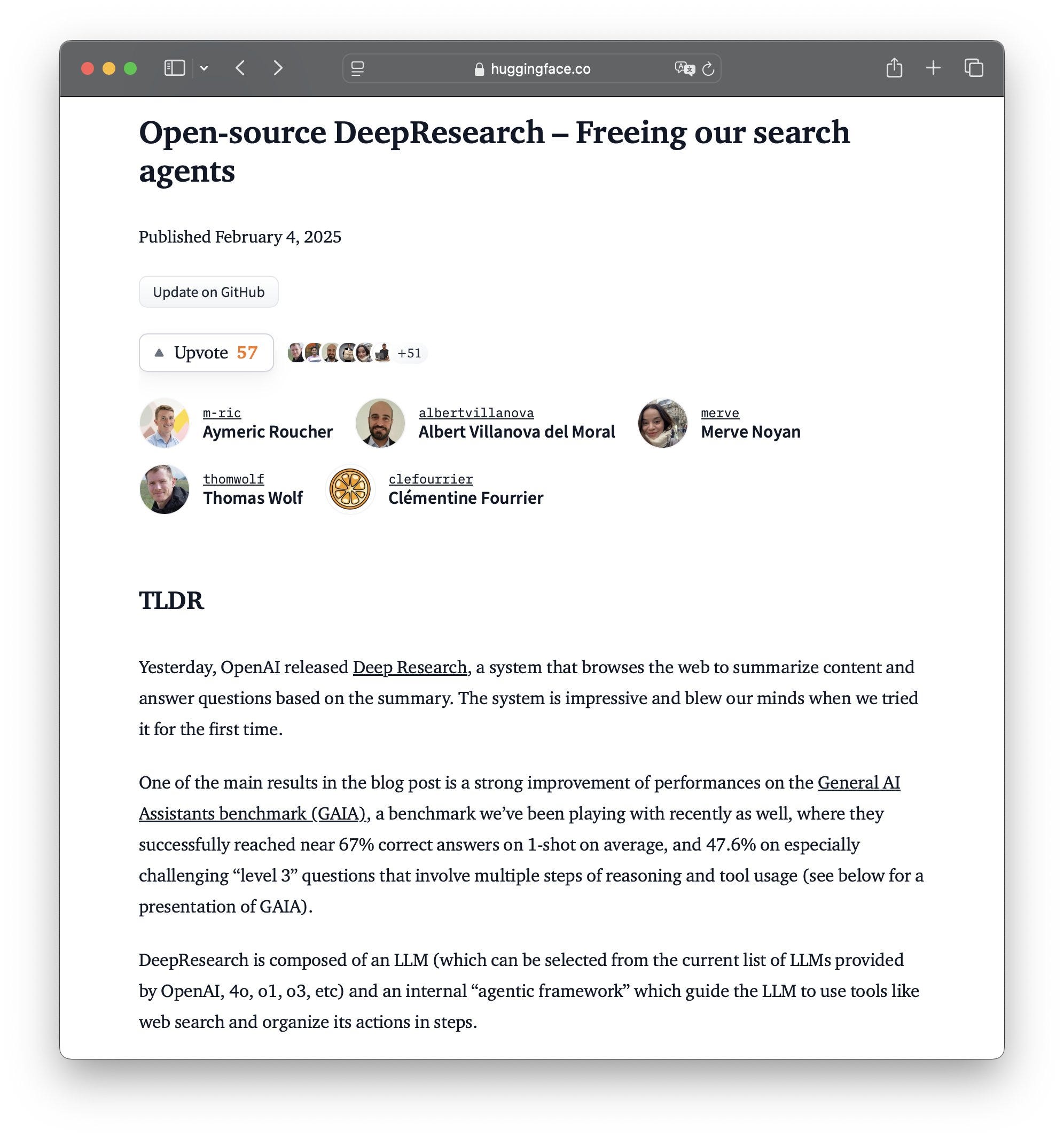
Deep Agent - R1 -V: These folks claim to have replicated DeepSeek R1's "aha moment" – where the model realizes its own mistakes and rethinks its approach – for just $3! (X, Github)
As I said on the show, "It's crazy, right? Nothing costs $3 anymore. Like it's half a coffee in Starbucks." They even claim you can witness this "aha moment" in a VLM. Open source is moving fast.
Krutim - Krutim 2 12B, Chitrath VLM, Embeddings and more from India: This Indian AI lab released a whole suite of models, including an improved LLM (Krutim 2), a VLM (Chitrarth 1), a speech-language model (Dhwani 1), an embedding model (Vyakhyarth 1), and a translation model (Krutrim Translate 1). (X, Blog, HF) They even developed a benchmark called "BharatBench" to evaluate Indic AI performance.
However, the community was quick to point out some… issues. As Harveen Singh Chadha pointed out on X, it seems like they blatantly copied IndicTrans, an MIT-licensed model, without even mentioning it. Not cool, Krutim. Not cool.
AceCoder: This project focuses on using reinforcement learning (RL) to improve code models. (X) They claim to have created a pipeline to automatically generate high-quality, verifiable code training data.
They trained a reward model (AceCode-RM) that significantly boosts the performance of Llama-3.1 and Qwen2.5-coder-7B. They even claim you can skip SFT training for code models by using just 80 steps of R1-style training!
Simple Scaling - S1 - R1: This paper (Paper) showcases the power of quality over quantity. They fine-tuned Qwen2.5-32B-Instruct on just 1,000 carefully curated reasoning examples and matched the performance of o1-preview!
They also introduced a technique called "budget forcing," allowing the model to control its test-time compute and improve performance. As I mentioned, Niklas Mengenhoff, who worked at Allen and was previously on the show, is involved. This is one to really pay attention to – it shows that you don't need massive datasets to achieve impressive reasoning capabilities.
Unsloth reduces R1 type reasoning to just 7GB VRAM (blog)

Deepseek R1-zero was autonimously learned reasoning in what they DeepSeek researchers called the "aha moment"
Unsloth adds another attempt at replicating this "aha moment" and claims they got it down to less than 7B VRAM, and it can see it for free, in a google colab!
This magic could be recreated through GRPO, a RL algorithm that optimizes responses efficiently without requiring a value function, unlike Proximal Policy Optimization (PPO) which relies on a value function
How it works:
1. The model generates groups of responses.
2. Each response is scored based on correctness or another metric created by some set reward function rather than an LLM reward model.
3 . The average score of the group is computed.
4. Each response's score is compared to the group average.
5. The model is reinforced to favor higher-scoring responses.
Tools
A few new and interesting tools were released this week as well:
Replit rebuilt and released their replit agents in an IOS app and released it free for many users. It can now build mini apps for you on the fly! (Replit)
Mistral has ios / android apps with the new release of LeChat (X)
Molly Cantillon released RPLY, which sits on your mac, and drafts replies to your messages. I installed it during writing this newsletter, and I did not expect it to hit this hard, it reviewed and summarized my texting patterns to "sound like me" and the models sit on device as well. Very very well crafted tool and the best thing it runs models on device if you want!
Github Copilot announced agentic workflows and next line editing, which are cursor features. To try them out you have to download VSCode insiders. They also added Gemini 2.0 (Blog)
The AI field moves SO fast, I had to update the content of the newsletter around 5 times while writing it as new things kept getting released!
This was a Banger week that started with o3-mini and deep research, continued with Gemini 2.0 and OmniHuman and "ended" with Mistral x Cerebras, Github copilot agents, o3-mini updated COT reasoning traces and a bunch more!
AI doesn't stop, and we're here weekly to cover all of this, and give you guys the highlights, but also go deep!
Really appreciate Derya's appearance on the show this week, please give him a follow and see you guys next week!
