
Published on February 5, 2025 6:56 PM GMT
Introduction
In this short article, I will share my thoughts on why I believe greater efforts should be directed at solving the average case of AI Control, ultimately designing systems that resist adaptation to a certain harmful task. First, I will explain what I mean by AI Control and average-case. Then I will present some arguments noting why I think average-case control is a promising line of research to consider amid our race toward AI alignment.
I. Defining average-case AI Safety and Control
For me, AI Control means that, on average, we can control a deployed AI system—that is, we can develop defence mechanisms or methods that prevent it from acting in unintended ways in the future. The definition for average-case AI Control is partly motivated by its counterpart: AI Control in the “worst-case,” where the goal is to create defences or methods that are impossible to break or reverse. In contrast, solving average-case AI Control would mean finding defences or methods that are extremely difficult to break or almost always impossible to break.
The difficulty of breaking the defence is determined by two key factors: the resources and the expertise—or intellectual resources—needed to effectively do so. Successful defences are those that only a few groups of people could possibly break. What I mean by this is that the rupture of defences is not random; it does not occur with probability ε for any random user. Rather only certain users can rupture them due to their intellectual or compute resources. Intuitively, a defence is considered to solve AI Control in the average case if it leaves the system in a state where it cannot be repurposed to accomplish the task it was originally prevented from doing without significant resources. The resulting system has to be almost useless for someone trying to accomplish the prevented task. This definition suggests that AI Control, in some ways, takes precedence over alignment—since a well-controlled system would be difficult to align to the defended-against capability.
For example, let us suppose we control a general-purpose LLM agent, that is we generate a defence that both prevents it from outputting information on building chemical weaponry and resists repurposing of any kind (i.e., HFTs, Prompt Engineering, Jailbreaks) without significant resources. This agent would then only be useful to bad actors with the resources to adversarially repurpose it—entities that likely had the resources to develop a harmful model in the first place. As a result, deploying this agent would not introduce additional harm to society, beyond what could already be done by those capable of leveraging it.
The above definition is inspired by how control is defined in the “control/safety” literature, where it is implicitly assumed that with enough effort a user can eventually break the system. That literature focuses on ensuring the system does not break the rest of the time—a concern addressed here as well. Rather than aiming for “unbreakable” systems, we focus on systems that are extremely difficult to break.
As a first example, consider an agent that learns online—that is, one that continues learning while deployed. For such an agent to be controlled for harmlessness in the average case, a malicious actor would need to exert significant effort to make it learn harmful behavior. Another important example would be open-weight models. In this case, a controlled open-weight model designed for harmlessness would require significant effort from a malicious actor to prompt harmful behavior. This is extremely important and desirable, yet currently not the case–it simply suffices to fine-tune the model on harmful behavior. Thus, solving average-case AI control implies protection from basic attacks, such as harmful fine-tuning (HFT).
II. Why average-case control is important
As we can gather from the previous example, solving the average case of AI Control would mean placing the danger in the hands of a small group of people – those with the ability to revert the defence – who likely coincide with those capable of developing the dangerous capabilities in the first place. Thus, solving average-case AI control means releasing agents that do not improve malicious actors’ harmful capabilities more than their resources and expertise can provide. Following the last example, we could never take harmful capabilities away from OpenAI, because even if we control the models we deploy, they likely have the intellectual and compute resources to revert the defence, however, they are not more dangerous because of it. If they wanted to develop a harmful agent, they could –independently of our deployed models—because of their massive resources.
Hopefully, by now, it is clear why control and average-case control are a desirable property. I will now argue why they are at least as important as alignment–if not more—and why the goal should be to solve both. When we think about alignment, we think about aligning systems to our goals—which are hopefully somewhat close to the harmless, honest, and helpful triad. However, this is only one side of the story. Alignment is both a double-edged sword and a capability in its own right. Solving alignment means having the ability to direct the system toward a set of values or behaviors, both good and bad (i.e., harmless/helpful and harmful/dangerous) as detailed in the figure below. Conversely, control is about rendering the path from harmless/helpful models to harmful/dangerous models difficult.
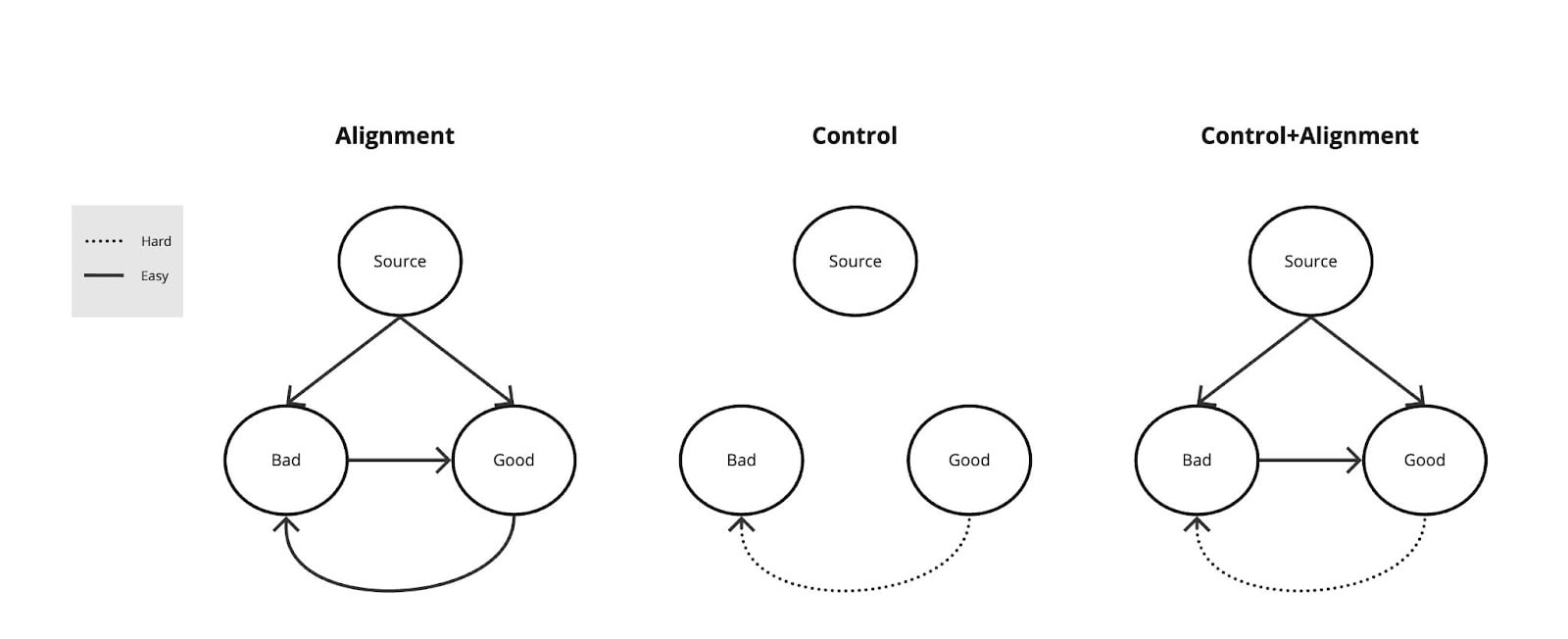
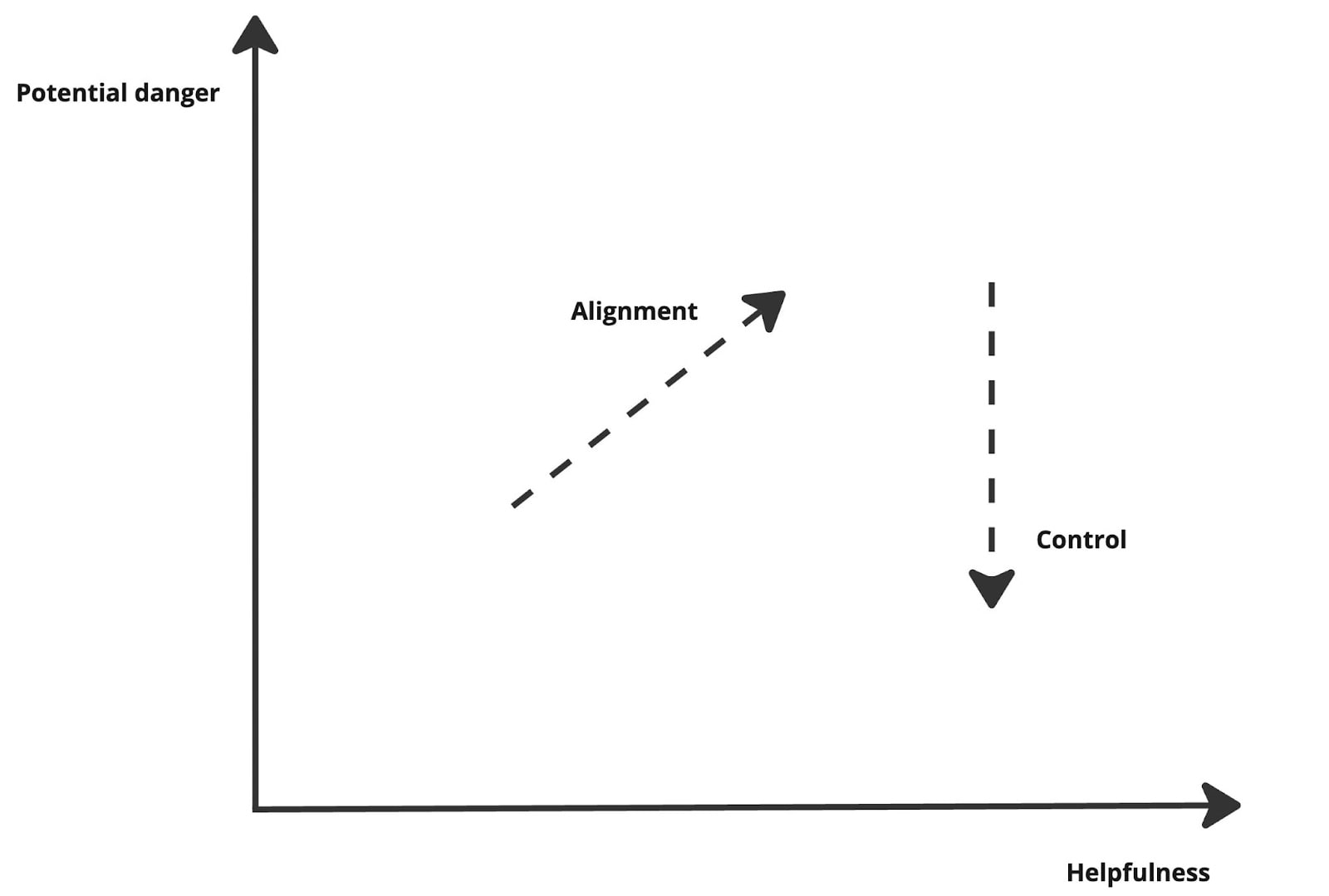
Now, suppose we can solve alignment and average-case control. In that case, we can release models that are controlled against harmful behavior while remaining fine-tunable to any harmless distribution of our choice. This is why alignment and control are complementary in the ideal scenario. Yet, given the current race, I believe our priority should first be on control rather than alignment. Alignment advances us closer to useful/helpful agents by allowing fine-tuning to useful distributions. Control, however, does not bring us closer or further from capabilities, rather, it protects what we can do with the model. In a 2D plane where usefulness/helpfulness and potential danger are the two orthogonal components, alignment would be a vector that has non-zero components in both directions, and control would be a vector virtually orthogonal to the helpfulness direction. This is detailed in the plot below.
III. The Nuclear analogy: a case for control amid the alignment race
To finish, I want to discuss the limitations of control, along with some scenarios and their implications. If we successfully solve control, this means that (destructive) power will be concentrated in the small group of entities capable of either designing powerful harmful agents or equivalently breaking through the defences of controlled AI systems. This is reminiscent of the Nuclear scenario, where only a small group of entities –in this case, countries—have access to destructive power. Now, that luckily puts them in a game-theoretic equilibrium, and even though it is not perfect –as we have seen historically, namely during the Cold War—it provides certain guarantees assuming rational agents and “perfect play”. Initially, this does not seem like a desirable scenario. However, it should be compared to the finish line of the alignment race, where access to potentially harmful models is mainstream. In the latter case, many people have their own “nuclear red button”, which is obviously undesirable. Assuming quasi-rational agents that behave optimally with a probability (therefore press the “nuclear button” with probability ), the chance of a disaster (any person pressing the nuclear button) is , which is approximately , and hence the chance of disaster grows linearly in the number of agents with access to potentially harmful systems (with a very small ).
Conclusion
Average-case AI control is therefore a practical and desirable goal and one that should be worked for in parallel to the alignment problem, with hopes of making progress on solving it before we get too powerful aligned systems. The arguments in this article involve many simplifications, one of which is that systems are “easy” to align resource-wise–computationally and intellectually speaking—if significant progress is made in the alignment problem. Another important simplification is the difference in the gradient between scenarios in the nuclear and the advanced AI agent case: the difference between non-nuclear and use of nuclear is very high, whereas we could envision an incremental use of an advanced AI agent.
I would like to thank Sabrina Nelson, Jonathan Lee and Otto Tutzauer for their invaluable help in writing this post.
Discuss
