


Large-scale language models (LLMs) have advanced the field of artificial intelligence as they are used in many applications. Although they can almost perfectly simulate human language, they tend to lose in terms of response diversity. This limitation is particularly problematic in tasks requiring creativity, such as synthetic data generation and storytelling, where diverse outputs are essential for maintaining relevance and engagement.
One of the major challenges in language model optimization is the reduction in response diversity due to preference training techniques. Post-training methods like reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) tend to concentrate probability mass on a limited number of high-reward responses. This results in models generating repetitive outputs for various prompts, restricting their adaptability in creative applications. The decline in diversity hinders the potential of language models to function effectively in fields that require broad-ranging outputs.

Previous methods for preference optimization primarily emphasize aligning models with high-quality human preferences. Supervised fine-tuning and RLHF techniques, while effective at improving model alignment, inadvertently lead to response homogenization. Direct Preference Optimization (DPO) selects highly rewarded responses while discarding low-quality ones, reinforcing the tendency for models to produce predictable outputs. Attempts to counteract this issue, such as adjusting sampling temperatures or applying KL divergence regularization, have failed to significantly enhance diversity without compromising output quality.
Researchers from Meta, New York University, and ETH Zurich have introduced Diverse Preference Optimization (DivPO), a novel technique designed to enhance response diversity while maintaining high quality. Unlike traditional optimization methods prioritizing the highest-rewarded response, DivPO selects preference pairs based on quality and diversity. This ensures that the model generates outputs that are not only human-aligned but also varied, making them more effective in creative and data-driven applications.

DivPO operates by sampling multiple responses for a given prompt and scoring them using a reward model. Instead of selecting the single highest-rewarded response, the most diverse, high-quality response is chosen as the preferred output. Simultaneously, the least varied response that does not meet the quality threshold is selected as the rejected output. This contrastive optimization strategy allows DivPO to learn a broader distribution of responses while ensuring that each output retains a high-quality standard. The approach incorporates various diversity criteria, including model probability, word frequency, and an LLM-based diversity judgment, to assess each response’s distinctiveness systematically.
Extensive experiments were conducted to validate the effectiveness of DivPO, focusing on structured persona generation and open-ended creative writing tasks. The results demonstrated that DivPO significantly increased diversity without sacrificing quality. Compared to standard preference optimization methods, DivPO led to a 45.6% increase in persona attribute diversity and a 74.6% rise in story diversity. The experiments also showed that DivPO prevents models from generating a small subset of responses disproportionately, ensuring a more even distribution of generated attributes. A key observation was that models trained using DivPO consistently outperformed baseline models in diversity evaluations while maintaining high quality, as assessed by the ArmoRM reward model.
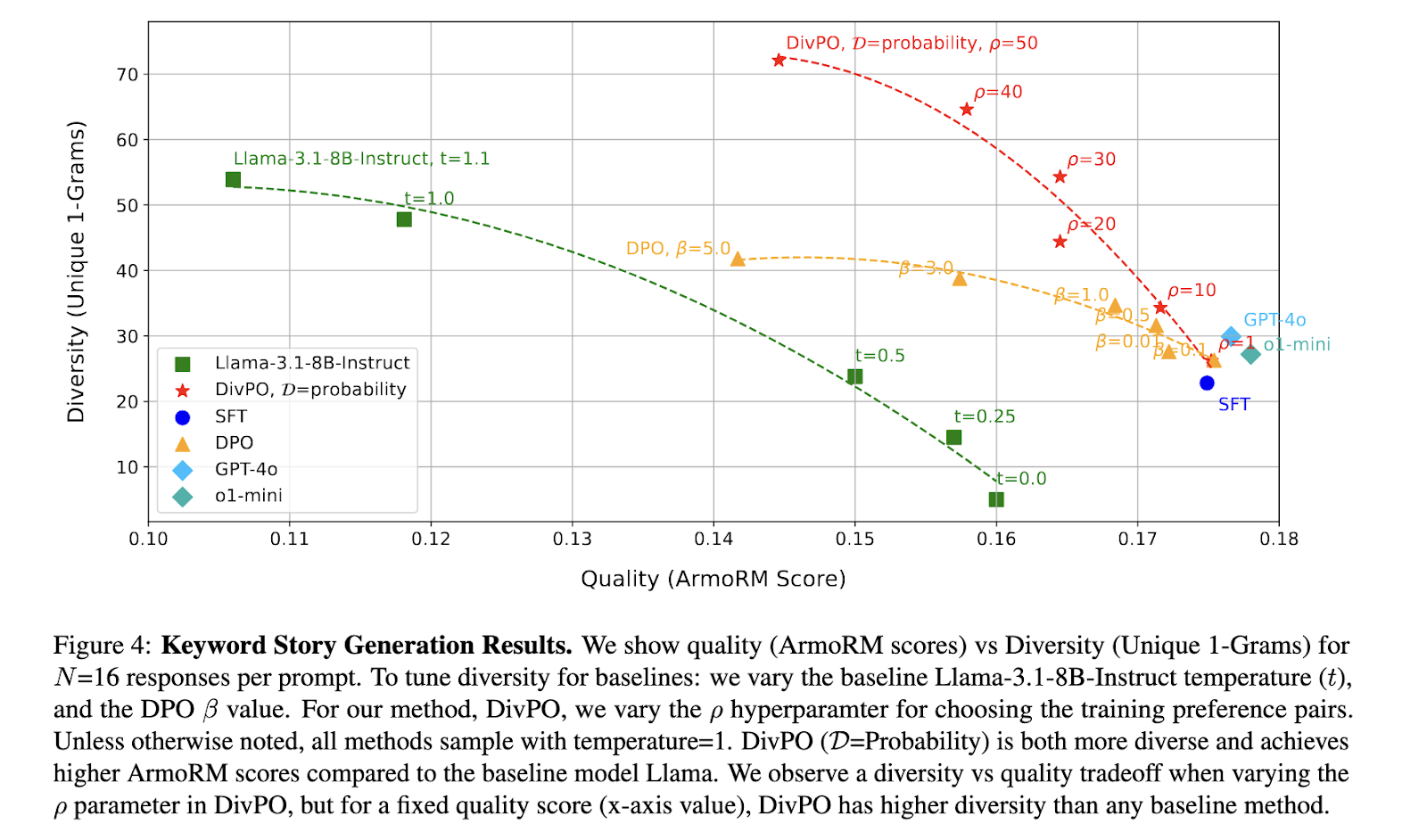
Further analysis of persona generation revealed that traditional fine-tuned models, such as Llama-3.1-8B-Instruct, failed to produce varied persona attributes, often repeating a limited set of names. DivPO rectified this issue by expanding the generated attribute range, leading to a more balanced and representative output distribution. The structured persona generation task demonstrated that online DivPO with word frequency criteria improved diversity by 30.07% compared to the baseline model while maintaining a comparable level of response quality. Similarly, the keyword-based creative writing task showed a substantial improvement, with DivPO achieving a 13.6% increase in diversity and a 39.6% increase in quality relative to the standard preference optimization models.
These findings confirm that preference optimization methods inherently reduce diversity, challenging language models designed for open-ended tasks. DivPO effectively mitigates this issue by incorporating diversity-aware selection criteria, enabling language models to maintain high-quality responses without limiting variability. By balancing diversity with alignment, DivPO enhances the adaptability and utility of LLMs across multiple domains, ensuring they remain useful for creative, analytical, and synthetic data generation applications. The introduction of DivPO marks a significant advancement in preference optimization, offering a practical solution to the long-standing problem of response collapse in language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.

The post This AI Paper from Meta Introduces Diverse Preference Optimization (DivPO): A Novel Optimization Method for Enhancing Diversity in Large Language Models appeared first on MarkTechPost.
