

许多类型的现实世界数据都可以自然地表示为图(graphs),例如社交网络、交易网络和生物分子。这凸显了对有效图表示以支持各种任务的需求。近年来,图神经网络 (GNN) 在从图中提取信息和实现与图相关的任务方面取得了显著的成功。然而,它们在解决现实世界问题时仍然面临一系列挑战,包括标记数据稀缺、可扩展性问题、潜在偏差等。这些挑战源于领域特定问题和 GNN 固有的局限性。本论文介绍了应对这些挑战并增强 GNN 执行现实世界任务能力的各种策略。
对于领域特定挑战,在本文中,我们特别关注化学(chemistry)领域的挑战,它在药物发现(drug discovery)过程中起着关键作用。考虑到通过湿实验室实验进行标记所需的大量资源,化学领域的人工智能面临着标记数据集稀缺的困境。为了解决这个问题,我们提出了一套全面的策略,涵盖基于模型和基于数据的策略以及混合方法。这些方法巧妙地利用数据、模型和分子表示的多样性来弥补单个数据集中标签的不足。对于固有的挑战,本论文介绍了克服两个主要挑战的策略:可扩展性和基于度的问题,特别是在链接预测任务的背景下。这两个挑战都源于 GNN 的机制,该机制涉及迭代聚合相邻节点的信息以更新每个中心节点。对于可扩展性问题,我们的工作不仅保留了 GNN 的预测性能,而且显著提高了推理速度。关于度偏差,我们的工作以非常轻的额外计算成本大大提高了 GNN 对代表性不足的节点的有效性。这些贡献不仅解决了将 GNN 应用于特定领域的关键差距,而且为未来在基于图的现实世界任务的更广泛领域的探索奠定了基础。

论文题目:Empowering Graph Neural Networks for Real-World Tasks
作者:Zhichun Guo
类型:2024年博士论文
学校:University of Notre Dame(美国圣母大学)
下载链接:
链接: https://pan.baidu.com/s/1ZrEI1TXvHBn4nVE1_EHZDw?pwd=jcxd
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
许多类型的现实世界数据都可以自然地表示为图,例如社交媒体中的社交网络、金融中的交易网络和生物学中的分子。鉴于它们的普遍性,获得有效的图表示以促进下游任务至关重要。近年来,图神经网络(GNN)[68,100]已被广泛使用并在各种任务中表现出显着的性能,例如节点分类[25,189],图分类[164,225]和链接预测[165,239]。
现实世界中的图表现出广泛的多样性,其特征是各种因素,例如图的大小。当根据图的大小和 GNN 训练所需的图数量在坐标系上绘制图时,大多数图出现在两个不同的对角线区域中,如图 1.1 所示。这种观点将图分为两个主要组:一个由相对较小的图组成,例如分子和大脑,我们通常在多个实例中训练和测试 GNN 以完成图级任务。另一个包括大型单个图,如基因和社交网络,重点是单个图中的节点级任务。这种划分不仅突出了 GNN 的广泛适用性,而且还指出了每种类型的图固有的特殊挑战。
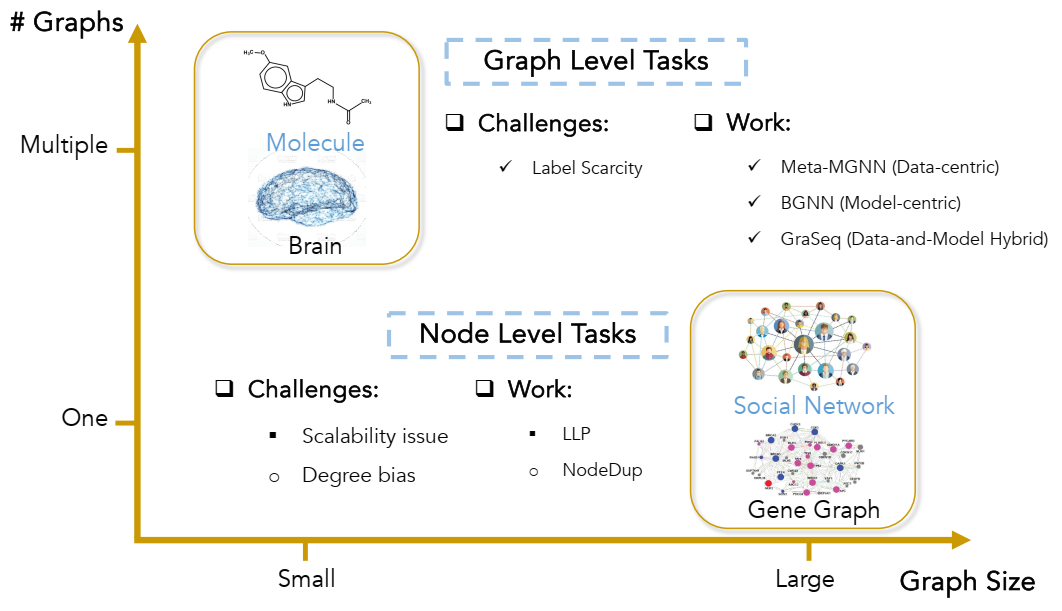 论文概述。
论文概述。
本论文研究了将 GNN 应用于各种图形类型所面临的独特挑战,特别关注化学和社交网络分析领域,作为各个图形类型的关键示例。它介绍了我们在应对这些挑战方面所做的创新努力,提高了 GNN 在这些情况下的有效性和效率。本论文分为两个主要部分,分别解决每种图形类型中遇到的具体挑战。
第一部分重点关注如何应对化学领域的挑战,目标是加速药物发现过程。正如我们之前介绍的那样,分子是相对较小的图,重点是将整个图作为单个单元进行分析。我们通常在多个不同的图中训练和测试 GNN,强调每个分子的整体属性和特征。因此,目标是在多个不同的图中推广 GNN,这需要一个全面的标记数据集来确保广泛的适用性。然而,由于湿实验室化学实验的标记过程劳动密集且成本高昂,标签稀缺是化学领域人工智能的一个严重问题。为了应对这一挑战,第一部分涵盖了以数据为中心、以模型为中心和创新混合视角的策略,以提高 GNN 在分子性质预测等关键化学应用中的效率。
第 2 章从数据角度解决了标签稀缺问题。在这项工作中,我们观察到,虽然某些属性的标记分子数量可能有限,但总体而言存在大量不同的属性。我们开创性地将分子属性预测挑战视为少数学习问题,并引入了 Meta-MGNN,这是一个元学习框架,旨在利用这些属性的多样性来缓解标记分子有限的问题。Meta-MGNN 进一步将分子结构、基于属性的自监督模块和自注意力任务权重纳入框架。这种结合不仅利用了未标记的分子数据,还解决了不同分子属性的任务异质性,从而加强了整个学习模型。
第 3 章重点介绍以模型为中心的策略。在这项工作中,我们观察到,虽然 GNN 共享相同的消息传递框架,但不同的 GNN 从同一张图中学习不同的知识。这意味着通过从多个模型中提炼互补知识可以提高性能。在这项工作中,我们提出了一种称为 BGNN 的新型自适应知识提炼框架,该框架将知识从多个 GNN 顺序转移到学生 GNN。我们还引入了自适应温度模块和权重提升模块。这些模块引导学生获得适当的知识以进行有效学习。通过改进 GNN,我们可以使用现有数据集获得卓越的预测结果。
第 4 章探讨了一种使用 GraSeq 的混合方法,GraSeq 是一种联合图形和序列表示学习模型,可利用分子的图形(分子图)和序列(SMILES 字符串)表示的知识。它采用由无监督重建和下游任务组成的多任务损失框架,有效地利用了有限大小的标记数据集进行训练。这种双重方法优于任何依赖单一类型分子表示的模型,体现了结合不同分子表示的强度。
第二部分过渡到大型网络领域,特别是社交网络,其中分析转移到单个图中的节点级焦点。在这种情况下,GNN 的有效性取决于邻居信息的有效聚合,这个过程在较大的网络中变得越来越繁琐。这不仅会导致训练和推理的高延迟,还会影响连接有限的节点(尤其是新传入的节点)的预测准确性。为了应对这些挑战,第二部分概述了两种旨在缓解可扩展性和程度偏差问题的不同方法。这些策略专门用于提高 GNN 在链接预测任务上的效率和有效性。
第 5 章讨论了 GNN 在链接预测任务上的可扩展性问题。受 GNN 通常比 MLP 更准确但效率更低的观察结果的启发,我们提出了一个关系知识提炼框架“无链接链接预测”(LLP),它将链接预测相关知识从 GNN 提炼到 MLP。通过我们提出的基于排名和基于分布的匹配策略,LLP 有效地将以每个(锚点)节点为中心的关系知识提炼到学生 MLP。因此,LLP 显著加速了链接预测推理,同时保持或提高了 GNN 的预测性能。
第 6 章通过一种简单但有效的增强技术 NodeDup 解决了度偏差问题,该技术复制低度节点并在遵循标准监督链接预测训练方案之前在节点和它们自己的重复节点之间创建链接。通过利用低度节点的“多视图”视角,NodeDup 在低度节点上显示出显着的 LP 性能改进,而不会影响高度节点上的任何性能。此外,作为即插即用的增强模块,NodeDup 可以轻松应用于现有的 GNN,并且计算成本非常低。
在第 7 章中,我们总结了本文,并从各个方面展望了 AI 在化学领域的未来发展以及进一步增强 GNN 的能力。
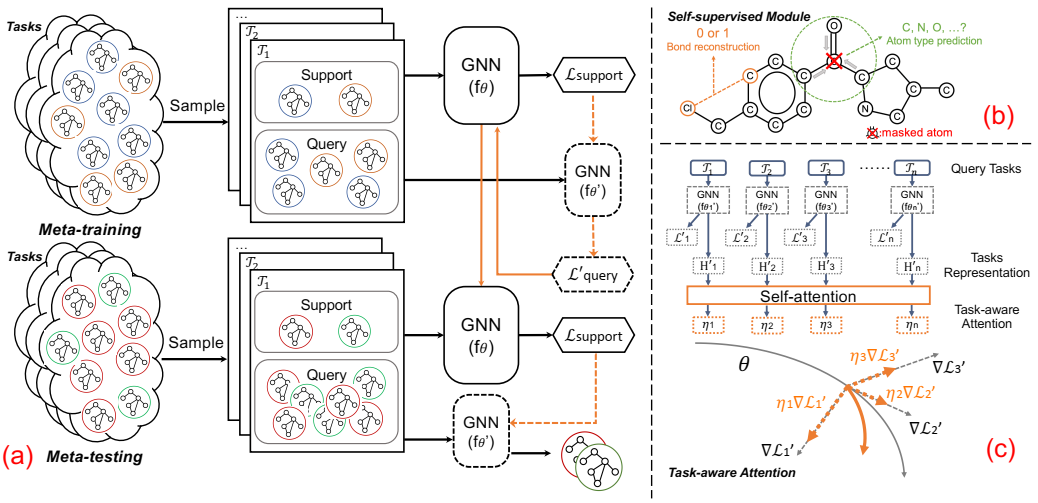 (a) Meta-MGNN 的整体框架:首先对一批训练任务进行采样。对于每个任务,支持集中都有几个数据示例。这些示例被输入到由 θ 参数化的 GNN 中。然后计算支持损失 Lsupport 并利用该损失将 GNN 参数更新为 θ′。接下来,将相应查询集中的示例输入到由 θ′ 参数化的 GNN 中,并计算此任务的损失 L′query。对其他训练任务重复相同的过程。之后,我们计算所有采样任务的 L′query 的总和,并使用它来进一步更新用于测试的 GNN 参数。(b) 自监督模块:它包括键重构和原子类型预测。橙色部分显示我们采样两个原子并使用 GNN 预测它们之间是否存在键。绿色部分显示我们随机屏蔽几个原子并使用 GNN 预测它们的类型。(c)任务感知注意:计算来自同一任务的查询集的所有分子嵌入的平均值来表示该任务。利用每个任务的嵌入,我们设计一个自注意层来计算每个任务的权重,然后将其纳入元训练过程以更新模型参数θ。
(a) Meta-MGNN 的整体框架:首先对一批训练任务进行采样。对于每个任务,支持集中都有几个数据示例。这些示例被输入到由 θ 参数化的 GNN 中。然后计算支持损失 Lsupport 并利用该损失将 GNN 参数更新为 θ′。接下来,将相应查询集中的示例输入到由 θ′ 参数化的 GNN 中,并计算此任务的损失 L′query。对其他训练任务重复相同的过程。之后,我们计算所有采样任务的 L′query 的总和,并使用它来进一步更新用于测试的 GNN 参数。(b) 自监督模块:它包括键重构和原子类型预测。橙色部分显示我们采样两个原子并使用 GNN 预测它们之间是否存在键。绿色部分显示我们随机屏蔽几个原子并使用 GNN 预测它们的类型。(c)任务感知注意:计算来自同一任务的查询集的所有分子嵌入的平均值来表示该任务。利用每个任务的嵌入,我们设计一个自注意层来计算每个任务的权重,然后将其纳入元训练过程以更新模型参数θ。
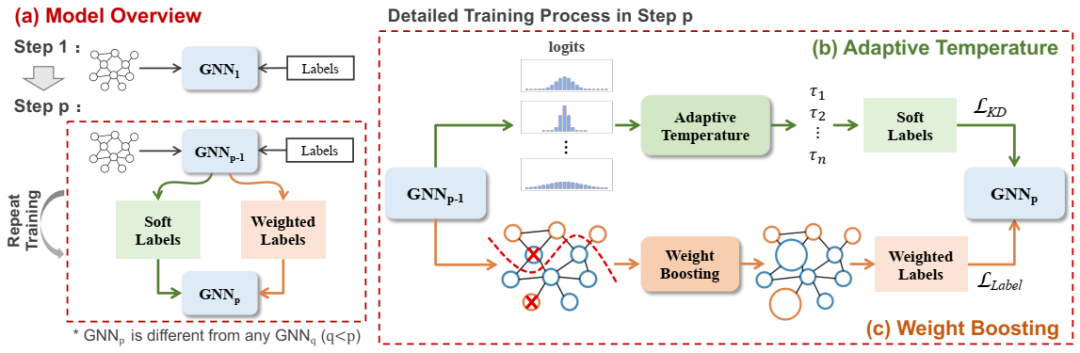 BGNN 的整体框架。(a) 展示了我们的顺序训练过程,我们训练一个带有标签的教师 GNN1。然后,我们重复地将上一步生成的 GNN 模型作为教师,以生成软标签并更新训练节点的权重以训练新的初始化学生。(b) 介绍了自适应温度模块,其中根据每个节点的教师 logits 分布调整温度。(c) 展示了权重提升模块,其中教师 GNN 错误分类的节点的权重得到提升(上图中尺寸较大的节点)。
BGNN 的整体框架。(a) 展示了我们的顺序训练过程,我们训练一个带有标签的教师 GNN1。然后,我们重复地将上一步生成的 GNN 模型作为教师,以生成软标签并更新训练节点的权重以训练新的初始化学生。(b) 介绍了自适应温度模块,其中根据每个节点的教师 logits 分布调整温度。(c) 展示了权重提升模块,其中教师 GNN 错误分类的节点的权重得到提升(上图中尺寸较大的节点)。
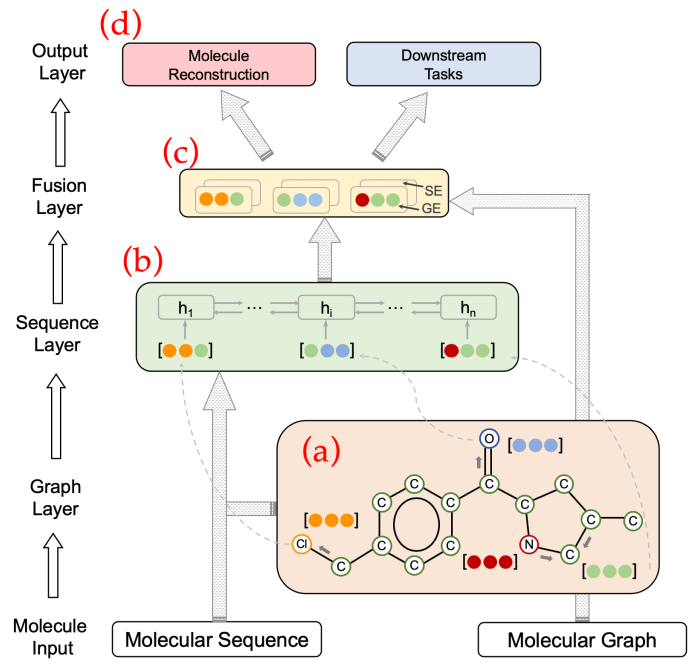 GraSeq 模型由四部分组成:首先,它使用图神经网络对分子图进行编码;其次,它应用语言模型对分子序列进行编码;第三,它使用融合层将输出图嵌入(表示为 GE)和序列嵌入(表示为 SE)结合起来;最后,它将多个下游任务作为监督,并与分子重建任务相关联。
GraSeq 模型由四部分组成:首先,它使用图神经网络对分子图进行编码;其次,它应用语言模型对分子序列进行编码;第三,它使用融合层将输出图嵌入(表示为 GE)和序列嵌入(表示为 SE)结合起来;最后,它将多个下游任务作为监督,并与分子重建任务相关联。
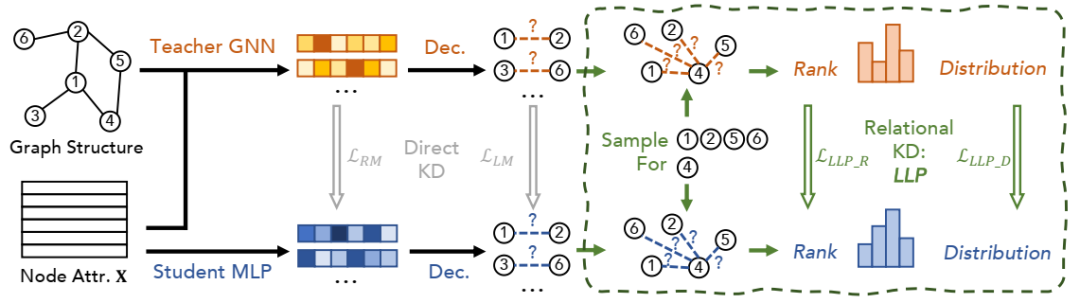 我们探索用于链接预测的 KD 方法,该方法将知识从 Teacher GNN 提炼到 Student MLP 编码器,每个编码器都有自己的解码器。我们首先探索直接 KD 方法:表示匹配和逻辑匹配(第 5.4.1 节)。在观察到它们无法提炼关系信息的缺点后,我们进一步提出了一个关系 KD 框架:LLP(第 5.4.3 节),它通过我们提出的基于排名的匹配和基于分布的匹配目标,为学生模型提供每个(锚点)节点与其他(上下文)节点的关系的知识。
我们探索用于链接预测的 KD 方法,该方法将知识从 Teacher GNN 提炼到 Student MLP 编码器,每个编码器都有自己的解码器。我们首先探索直接 KD 方法:表示匹配和逻辑匹配(第 5.4.1 节)。在观察到它们无法提炼关系信息的缺点后,我们进一步提出了一个关系 KD 框架:LLP(第 5.4.3 节),它通过我们提出的基于排名的匹配和基于分布的匹配目标,为学生模型提供每个(锚点)节点与其他(上下文)节点的关系的知识。
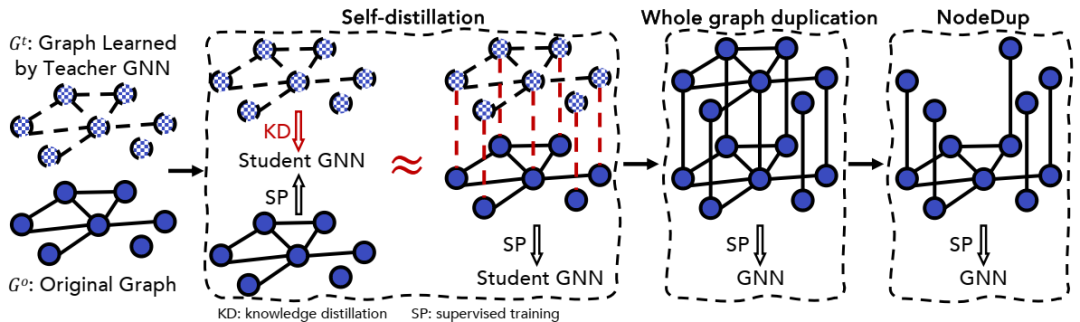 将 NodeDup 与自我蒸馏进行比较。自我蒸馏过程可以通过在增强图上训练学生 GNN 来近似,该图结合了 Go、Gt 和连接两个图中相应节点的边。可以通过将 Gt 替换为 Go 来进一步改进此过程,以探索整个图重复。NodeDup 是它的轻量级变体。
将 NodeDup 与自我蒸馏进行比较。自我蒸馏过程可以通过在增强图上训练学生 GNN 来近似,该图结合了 Go、Gt 和连接两个图中相应节点的边。可以通过将 Gt 替换为 Go 来进一步改进此过程,以探索整个图重复。NodeDup 是它的轻量级变体。







内容中包含的图片若涉及版权问题,请及时与我们联系删除
