


Multi-vector retrieval has emerged as a critical advancement in information retrieval, particularly with the adoption of transformer-based models. Unlike single-vector retrieval, which encodes queries and documents as a single dense vector, multi-vector retrieval allows for multiple embeddings per document and query. This approach provides a more granular representation, improving search accuracy and retrieval quality. Over time, researchers have developed various techniques to enhance the efficiency and scalability of multi-vector retrieval, addressing computational challenges in handling large datasets.
A central problem in multi-vector retrieval is balancing computational efficiency with retrieval performance. Traditional retrieval techniques are fast but frequently fail to retrieve complex semantic relationships within documents. On the other hand, accurate multi-vector retrieval methods experience high latency mainly because multiple calculations of similarity measures are required. The challenge, therefore, is to make a system such that the desirable features of the multi-vector retrieval are maintained. Yet, the computational overhead is reduced significantly to make a real-time search possible for a large-scale application.
Several improvements have been introduced to enhance efficiency in multi-vector retrieval. ColBERT introduced a late interaction mechanism to optimize retrieval, making query-document interactions computationally efficient. Thereafter, ColBERTv2 and PLAID further elaborated on the idea by introducing higher pruning techniques and optimized kernels in C++. Concurrently, the XTR framework from Google DeepMind has simplified the scoring process without requiring an independent stage for document gathering. However, such models were still efficiency-prone, mainly token retrieval and document scoring, making the associated latency and utilization of resources higher.
A research team from ETH Zurich, UC Berkeley, and Stanford University introduced WARP, a search engine designed to optimize XTR-based ColBERT retrieval. WARP integrates advancements from ColBERTv2 and PLAID while incorporating unique optimizations to improve retrieval efficiency. The key innovations of WARP include WARPSELECT, a method for dynamic similarity imputation that eliminates unnecessary computations, an implicit decompression mechanism that reduces memory operations, and a two-stage reduction process for faster scoring. These enhancements allow WARP to deliver significant speed improvements without compromising retrieval quality.
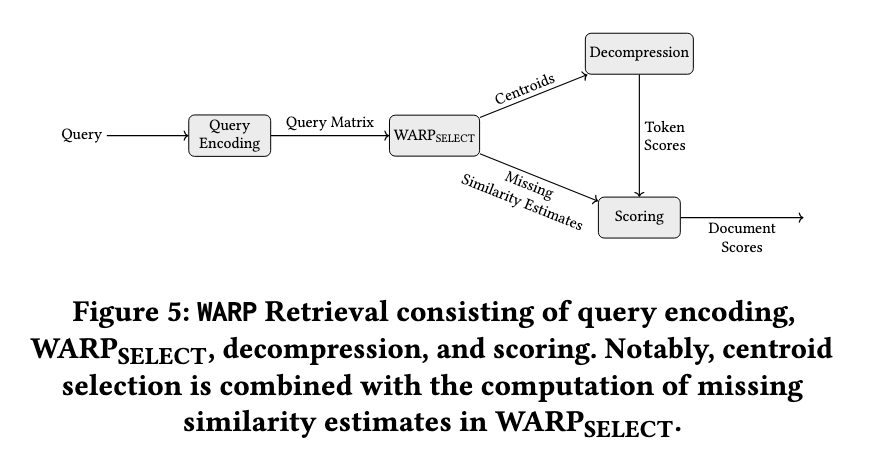
The WARP retrieval engine uses a structured optimization approach to improve retrieval efficiency. First, it encodes the queries and documents using a fine-tuned T5 transformer and produces token-level embeddings. Then, WARPSELECT decides on the most relevant document clusters for a query while avoiding redundant similarity calculations. Instead of explicit decompression during retrieval, WARP performs implicit decompression to reduce computational overhead significantly. A two-stage reduction method is then used to calculate document scores efficiently. This aggregation of token-level scores and then summing up the document-level scores with dynamically handling missing similarity estimates makes WARP highly efficient compared to other retrieval engines.
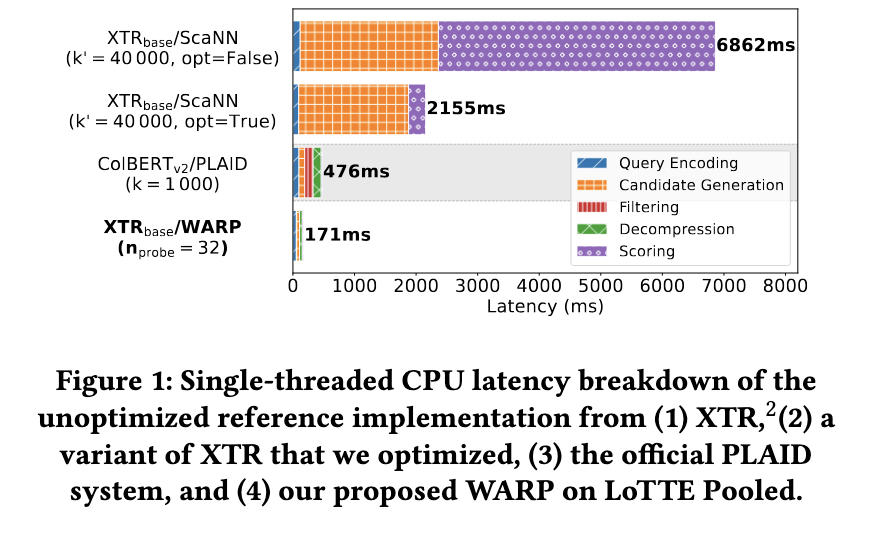
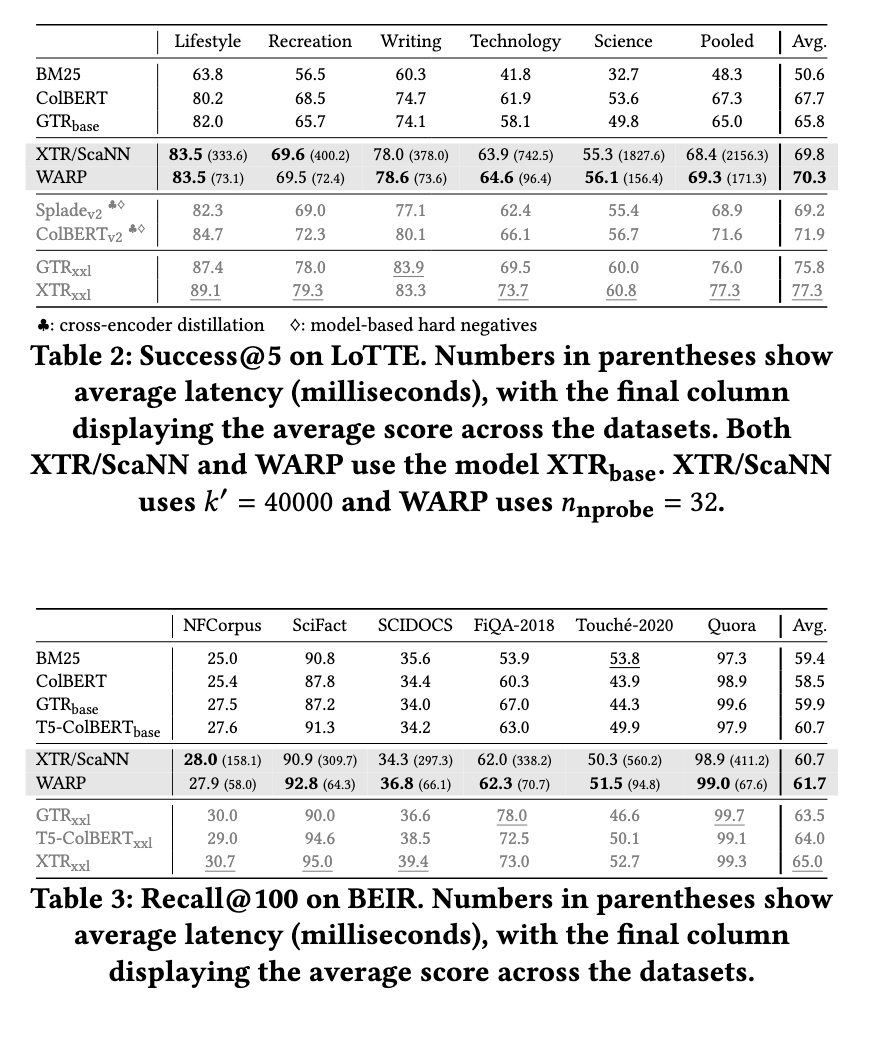
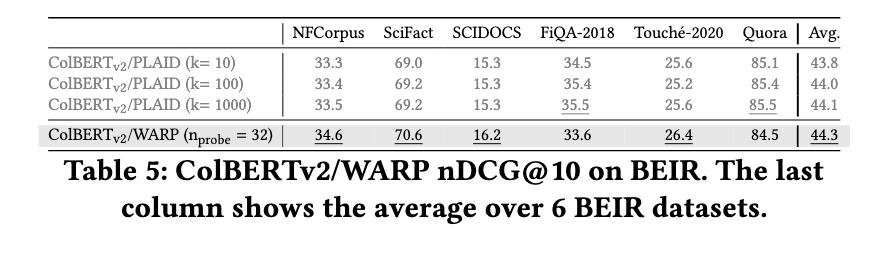
WARP significantly improves retrieval performance while reducing query processing time significantly. Experimental results show that WARP reduces end-to-end query latency by 41 times compared with the XTR reference implementation on LoTTE Pooled and brings query response times down from over 6 seconds to 171 milliseconds with a single thread. Moreover, WARP can achieve a threefold speedup over ColBERTv2/PLAID. Index size is also optimized, achieving 2x-4x less storage requirements than the baseline methods. Moreover, WARP outperforms previous retrieval models while keeping high quality across benchmark datasets.
The development of WARP marks a significant step forward in multi-vector retrieval optimization. The research team has successfully improved both speed and efficiency by integrating novel computational techniques with established retrieval frameworks. The study highlights the importance of reducing computational bottlenecks while maintaining retrieval quality. The introduction of WARP paves the way for future improvements in multi-vector search systems, offering a scalable solution for high-speed and accurate information retrieval.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Researchers from Stanford, UC Berkeley and ETH Zurich Introduces WARP: An Efficient Multi-Vector Retrieval Engine for Faster and Scalable Search appeared first on MarkTechPost.
