
美国数学会的精心主办,加上哈佛大学、多伦多大学等名校学子的踊跃参与,让这项赛事的桂冠成为无数学子梦寐以求的殊荣,其权威性和挑战性,那是得到了全球学界的公认。
而最近,来自斯坦福的一项研究,却让大家惊掉了下巴:仅仅对题目中的变量、常量等要素稍作修改,大模型「尖子生」o1-preview模型的准确率就立刻大幅下降,降幅高达 30%!

这就好比一位武林高手,平时在熟悉的招式里威风八面,一旦对手换个路数,就立马乱了阵脚。这不禁让人好奇,这些难住最强推理模型的变体题,到底藏着怎样的玄机?
北美最难数学竞赛题「变脸」,AI有点懵
OpenAI的o1-preview模型自出道以来,凭借超强的推理能力,在各个领域大杀四方。
就拿编程来说,在Codeforces编程竞赛这个「高手如云」的赛场上,它的Elo评分高达 1807,把93%的竞争对手都远远甩在身后,写起代码来又快又准,就像一位经验老到的程序员。
在数学领域更是展现出了惊人的实力。2024年的美国数学邀请赛(AIME)题目集上,o1-preview的正确率高达83%,相当于全美参赛选手top500的水平。
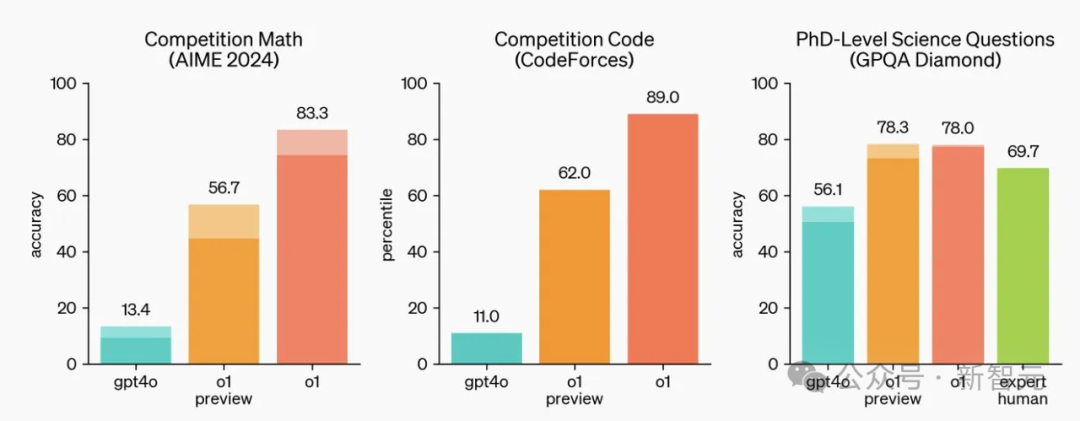
医学诊断方面,哈佛医学院和斯坦福大学组成的科研团队曾对o1-preview进行过全方位的 「考核」,结果令人惊叹:在生成诊断意见、诊断临床推理和管理推理这些关键任务上,它甚至超越了人类医生。面对复杂的病例,它能快速分析症状、病史等信息,并给出准确的诊断建议。
然而,就是这样一个在多领域「开挂」的模型,在面对普特南数学竞赛题的变体时,却仿佛迷失了方向。
在原始题目上,o1-preview本能达到41.95%的准确率,而一旦题目中的变量、常量被修改,准确率就像坐了滑梯一样,直线下降约30%。
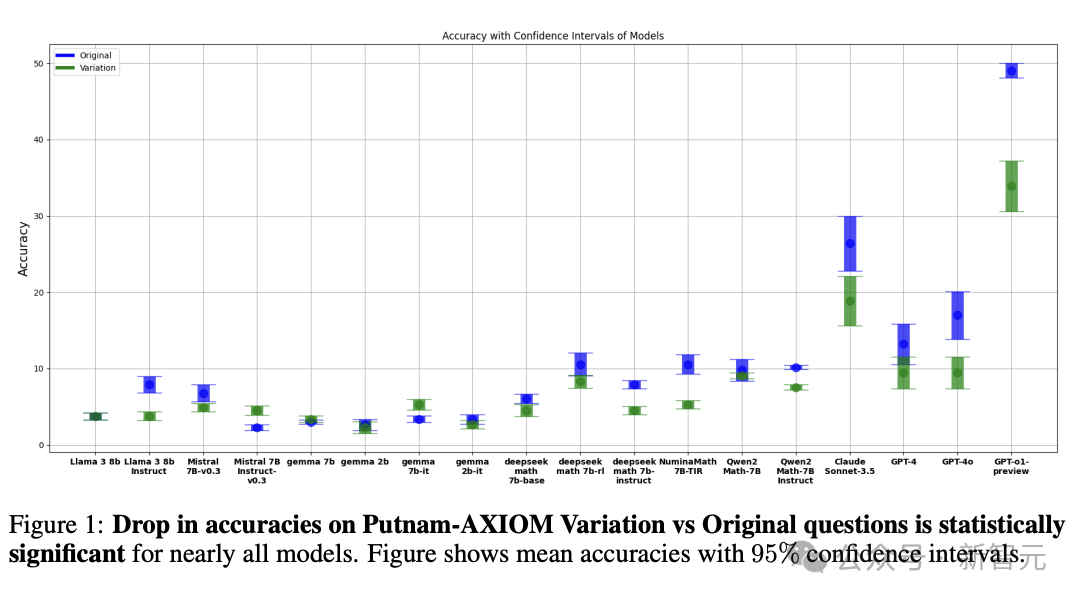
这巨大的反差,背后其实有着深层次的原因。普特南竞赛题本就以超高的难度、独特的出题思路著称,原始题目和变体题目之间,虽然看似只有细微的差别,但这些改变往往涉及到数学概念的深层次运用和逻辑结构的巧妙变换。
o1-preview模型在训练过程中,可能更多是对常见的数学题型、编程模式、医学案例进行学习和优化,对于这种专门设计、极度刁钻的变体题,缺乏足够的「应对经验」,难以迅速抓住问题的关键,从而导致准确率大幅下滑。
Putnam-AXIOM基准,AI数学能力的「试金石」
为了更准确深入地评估AI大模型的数学能力,研究团队精心打造了Putnam-AXIOM Original基准,收纳了来自历年普特南数学竞赛(Putnam)的236个数学问题,从复杂的代数变换到精妙的几何证明,从抽象的数论难题到变幻莫测的组合数学谜题,无一不是对人类智慧极限的挑战。
但这项基准的价值远不止于收录原题,更厉害的是,研究者们设计了一套巧妙的程序化修改机制,可以对问题中的变量、常量等关键要素进行修改,从而生成无限多个全新且难度相当的问题。

比如说,把一个几何问题中的边长数值进行变换,或者改变函数题中的参数取值范围,这些看似微小的调整,却能让整个问题的解法路径大不相同。
而且,这些新生成的题目从未在互联网上出现过,因此也不可能泄露到任何模型的训练数据集中,完全杜绝了AI靠 「死记硬背」答案来作弊的可能,真正做到了对 AI 数学推理能力的精准探测。
在这个新设计的基准上,研究人员大范围选择了各种模型进行测试,包括OpenAI的o1-preview、GPT-4和GPT-4o,Anthropic的旗舰模型Claude-3.5 Sonnet,Llama、Qwen的等有影响力的开源模型,以及Gemma、Mistral、DeepSeek、Numina等以数学能力闻名的开源模型。
首先,将Putnam-AXIOM基准中的236道原题输入给各个模型,记录它们的解题时间、推理步骤以及最终答案,算出准确率。接着,把经过程序化修改后的变体题抛给这些模型,同样严格记录解题过程中各项数据。
在原始题目上,o1-preview模型以41.95%的准确率暂居榜首,可一旦切换到变体题,它的准确率就「跳水」到了 11.95%左右,足足下降了30个百分点。
其他模型的准确率滑坡也相当显著,但值得注意的是,Gemma和Mistral系列模型中的某些型号在变体题上的准确率不降反升。
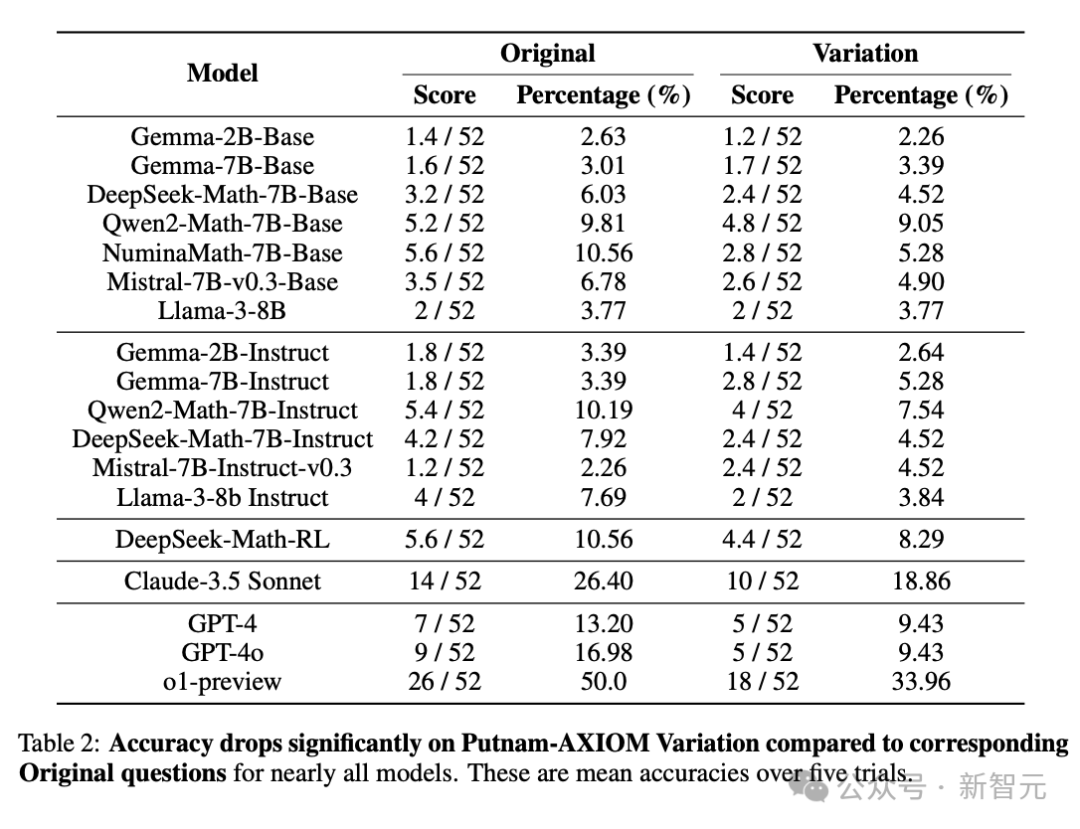
这些数据背后,反映出的问题相当深刻。一方面,当前的AI模型,哪怕是最顶尖的,在面对数学问题的灵活变化时适应性较差。它们可能对大规模数据训练出来的固定模式有一定依赖,一旦题目超出了熟悉的套路就会出现显著滑坡。
另一方面,普特南竞赛题的变体设计,精准地击中了 AI 的「软肋」,这也为未来AI模型的训练和提升指明了另一种方向。



内容中包含的图片若涉及版权问题,请及时与我们联系删除
