


Modern AI systems rely heavily on post-training techniques like supervised fine-tuning (SFT) and reinforcement learning (RL) to adapt foundation models for specific tasks. However, a critical question remains unresolved: do these methods help models memorize training data or generalize to new scenarios? This distinction is vital for building robust AI systems capable of handling real-world variability.
Prior work suggests SFT risks overfitting to training data, making models brittle when faced with new task variants. For example, an SFT-tuned model might excel at arithmetic problems using specific card values (e.g., treating ‘J’ as 11) but fail if the rules change (e.g., ‘J’ becomes 10). Similarly, RL’s reliance on reward signals could either encourage flexible problem-solving or reinforce narrow strategies. However, existing evaluations often conflate memorization and true generalization, leaving practitioners uncertain about which method to prioritize. In a latest paper from HKU, UC Berkeley, Google DeepMind, and NYU investigate this by comparing how SFT and RL affect a model’s ability to adapt to unseen rule-based and visual challenges.
They propose to test generalization in controlled settings to isolate memorization from generalization. Researchers designed two tasks: GeneralPoints (arithmetic reasoning) and V-IRL (visual navigation). Both tasks include in-distribution (ID) training data and out-of-distribution (OOD) variants to test adaptability:
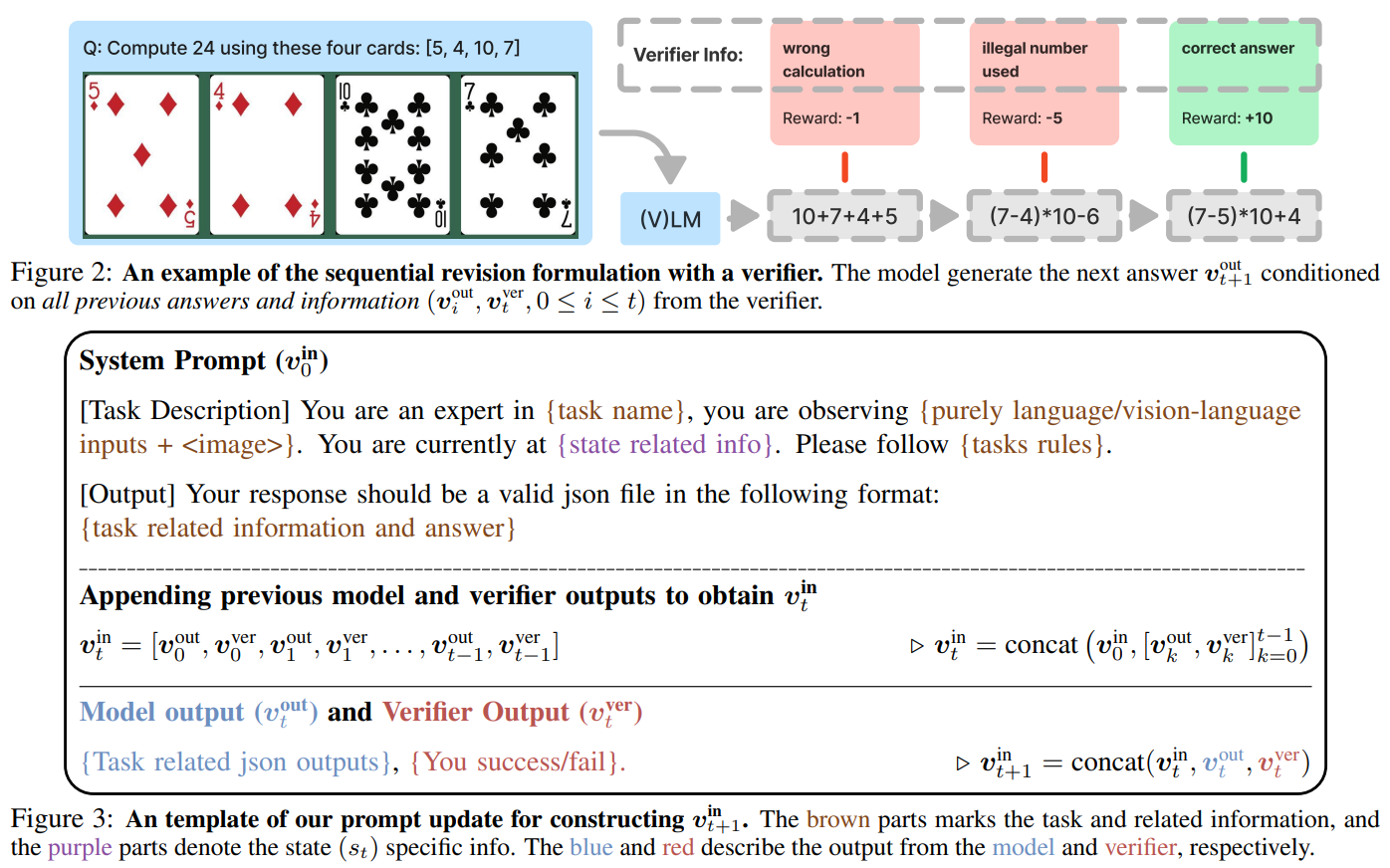
- Rule-Based Generalization (GeneralPoints, shown in Fig 3):
- Task: Create equations equal to 24 using four numbers from playing cards.Variants: Change card-value rules (e.g., ‘J’ = 11 vs. ‘J’ = 10) or card colors (red vs. blue).Goal: Determine if models learn arithmetic principles or memorize specific rules.
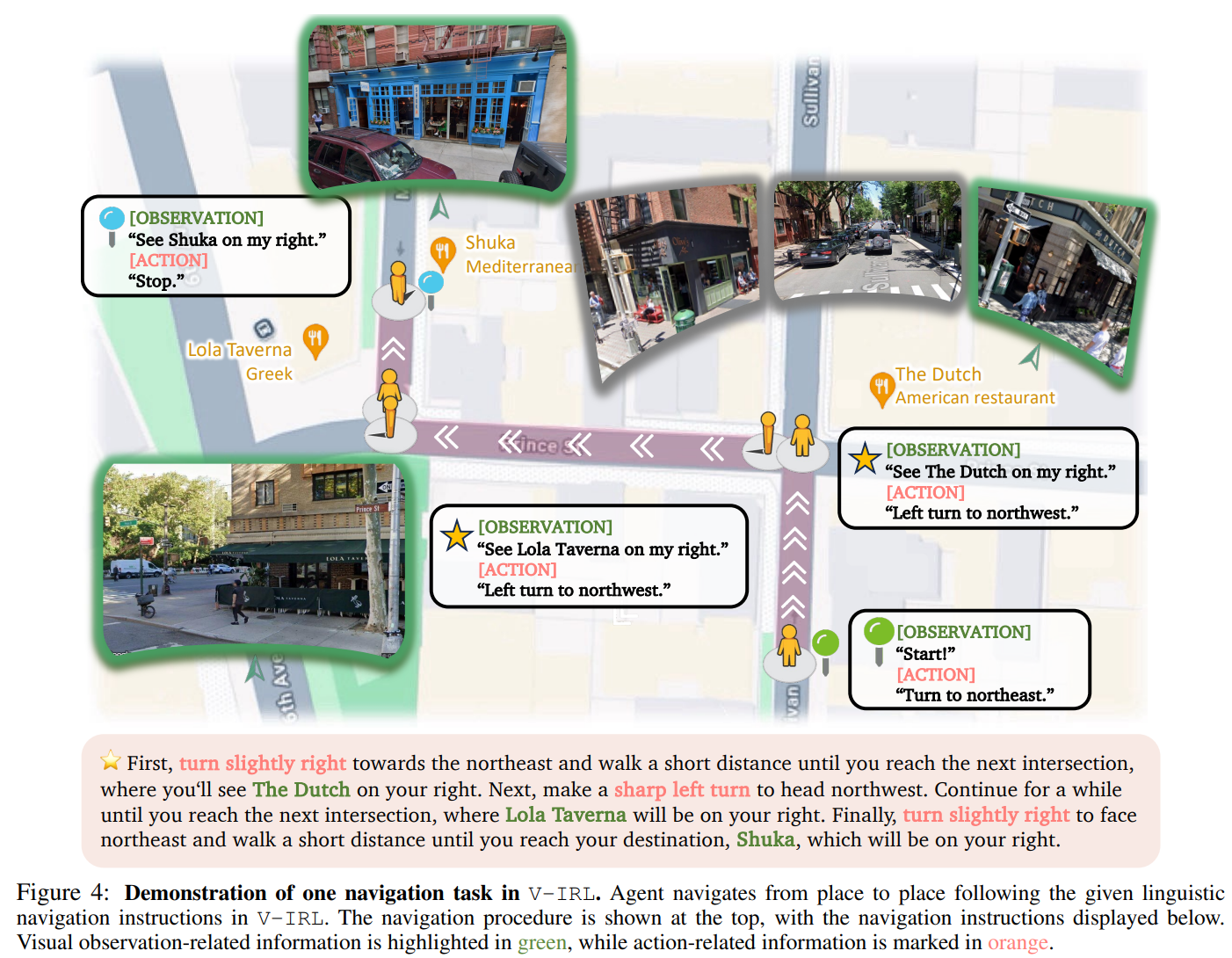
- Visual Generalization (V-IRL, shown in Fig 4):
- Task: Navigate to a target location using visual landmarks.Variants: Switch action spaces (absolute directions like “north” vs. relative commands like “turn left”) or test in unseen cities.Goal: Assess spatial reasoning independent of memorized landmarks.
For experiments, the study uses Llama-3.2-Vision-11B as the base model, applying SFT first (standard practice) followed by RL. Key experiments measured performance on OOD tasks after each training phase. Let’s now discuss some critical insights from the paper:
How do SFT and RL Differ in Learning Mechanisms?
- SFT’s Memorization Bias: SFT trains models to replicate correct responses from labeled data. While effective for ID tasks, this approach encourages pattern matching. For instance, if trained on red cards in GeneralPoints, the model associates color with specific number assignments. When tested on blue cards (OOD), performance plummets because it memorizes color-number correlations instead of arithmetic logic. Similarly, in V-IRL, SFT models memorize landmark sequences but struggle with new city layouts.
- RL’s Generalization Strength: RL optimizes for reward maximization, which forces models to understand task structure. In GeneralPoints, RL-trained models adapt to new card rules by focusing on arithmetic relationships rather than fixed values. For V-IRL, RL agents learn spatial relationships (e.g., “left” means rotating 90 degrees) instead of memorizing turn sequences. This makes them robust to visual changes, such as unfamiliar landmarks.
Another critical insight is that RL benefits from verification iterations—multiple attempts to solve a task within a single training step. More iterations (e.g., 10 vs. 1) allow the model to explore diverse strategies, improving OOD performance by +5.99% in some cases.
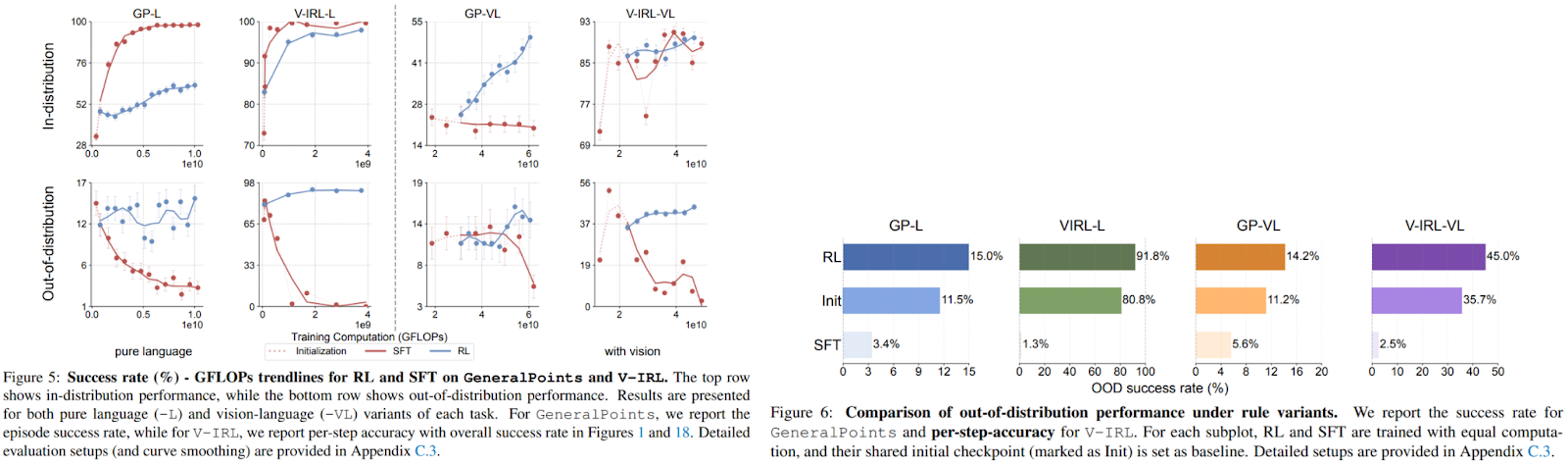
In performance evaluation RL outperforms SFT consistently in both tasks as shown in Fig 5 & 6:
- Rule-Based Tasks:
- RL improved OOD accuracy by +3.5% (GP-L) and +11.0% (V-IRL-L), while SFT degraded performance by -8.1% and -79.5%, respectively.Example: When card rules changed from ‘J=11’ to ‘J=10’, RL models adjusted equations using the new values, whereas SFT models reused invalid memorized solutions.
- RL boosted OOD performance by +17.6% (GP-VL) and +61.1% (V-IRL-VL), while SFT dropped by -9.9% and -5.6%.In V-IRL, RL agents navigated unseen cities by recognizing spatial patterns, while SFT failed due to reliance on memorized landmarks.
The study also suggests that SFT is necessary to initialize models for RL. Without SFT, RL struggles because the base model lacks basic instruction-following skills. However, overly-tuned SFT checkpoints harm RL’s adaptability, where RL couldn’t recover OOD performance after excessive SFT. However, the researchers clarify that their findings—specific to the Llama-3.2 backbone model—do not conflict with earlier work such as DeepSeekAI et al. (2025), which proposed that SFT could be omitted for downstream RL training when using alternative base architectures.
In conclusion, this study demonstrates a clear trade-off: SFT excels at fitting training data but falters under distribution shifts, while RL prioritizes adaptable, generalizable strategies. For practitioners, this implies that RL should follow SFT—but only until the model achieves basic task competence. Over-reliance on SFT risks “locking in” memorized patterns, limiting RL’s ability to explore novel solutions. However, RL isn’t a panacea; it requires careful tuning (e.g., verification steps) and balanced initialization.
Check out the PAPER. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Memorization vs. Generalization: How Supervised Fine-Tuning SFT and Reinforcement Learning RL Shape Foundation Model Learning appeared first on MarkTechPost.
