
DeepSeek大爆出圈,现在连夜发布新模型——
多模态Janus-Pro-7B,发布即开源。
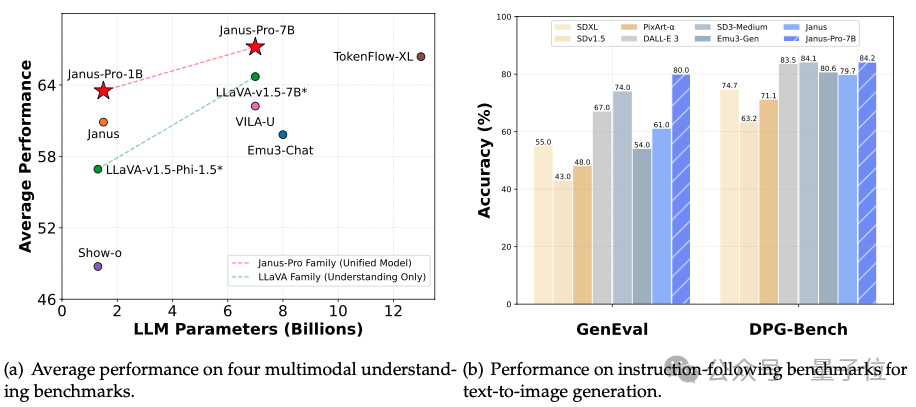
在GenEval和DPG-Bench基准测试中击败了DALL-E 3和Stable Diffusion。
想必大家这几天完全被DeepSeek刷屏了吧。
它长时间霸榜热搜第一,甚至AI第一股英伟达直接被干崩了——最大跌幅近17%,一夜蒸发5890亿美元(约合人民币4.24万亿元),创下美股单日跌幅最大纪录。
而Deepseek神话还在继续,春节假期中全国人民都开始体验了,Deepseek服务器还一度卡到宕机。



值得一提,同一夜,阿里旗下大模型通义千问Qwen也更新了自己的开源家族:
视觉语言模型Qwen2.5-VL,包括3B、7B 和 72B三种尺寸。
真~今夜杭州都不睡,起舞竞速大模型。
DeepSeek连夜发布新模型
先来看看DeepSeek新模型,这其实是此前Janus、JanusFlow的高级版本和延续。

一作为博士毕业于北大的陈小康。
具体来说,它基于DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base构建的,是一个统一理解和生成的多模态大模型。整个模型采用自回归框架。
它通过将视觉编码解耦为单独的路径来解决以前方法的局限性,同时仍然使用单一、统一的转换器架构进行处理。
这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。
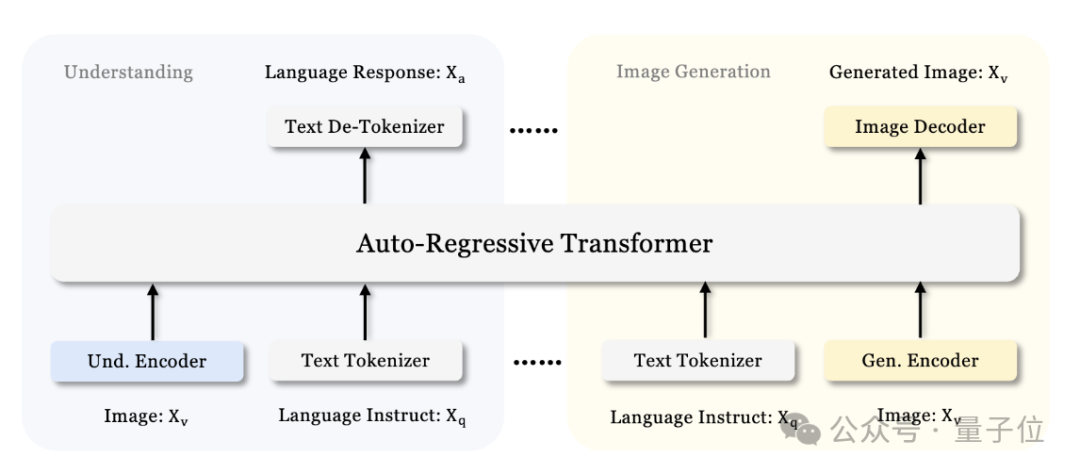
对于多模态理解,它使用SigLIP-L作为视觉编码器,支持 384 x 384 图像输入。对于图像生成,Janus-Pro使用LIamaGen中的VQ标记器,将图像转换为离散的ID,下采样率为16。
ID序列被扁平化为一维后,他们使用生成适配器将每个ID对应的代码库嵌入映射到 LLM 的输入空间中。然后,将这些特征序列连接起来,形成一个多模态特征序列,随后将其输入 LLM 进行处理。
除了 LLM 内置的预测头,还在视觉生成任务中使用随机初始化的预测头进行图像预测。
相较于前一个版本Janus的三个训练阶段,团队发现这一训练策略并不理想,会大大降低计算效率。
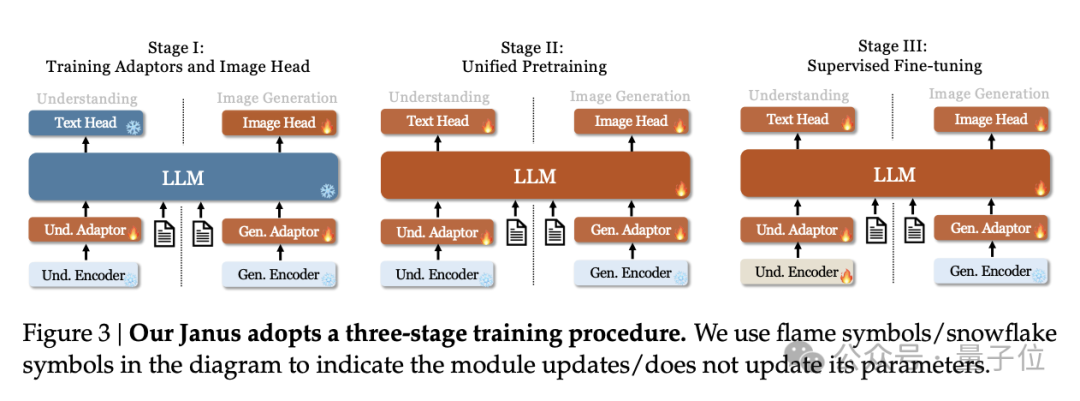
对此,他们做了两处大的修改。
第一阶段Stage I的长时间训练:增加了第一阶段的训练步骤,以便在 ImageNet 数据集上进行充分的训练。研究结果表明,即使在 LLM 参数固定的情况下,模型也能有效地模拟像素依赖性,并根据类别名称生成合理的图像。
第二阶段Stage II:的集中训练:在第二阶段,放弃了 ImageNet 数据,直接利用常规文本到图像数据来训练模型,以生成基于密集描述的图像。
此外在第三阶段的监督微调过程中,还调整了不同类型数据集的数据比例,将多模态数据、纯文本数据和文本图像数据的比例从 7:3:10 调整为 5:1:4。
通过略微降低文本到图像数据的比例发现,这一调整可以让在保持强大的视觉生成能力的同时,提高多模态理解性能。
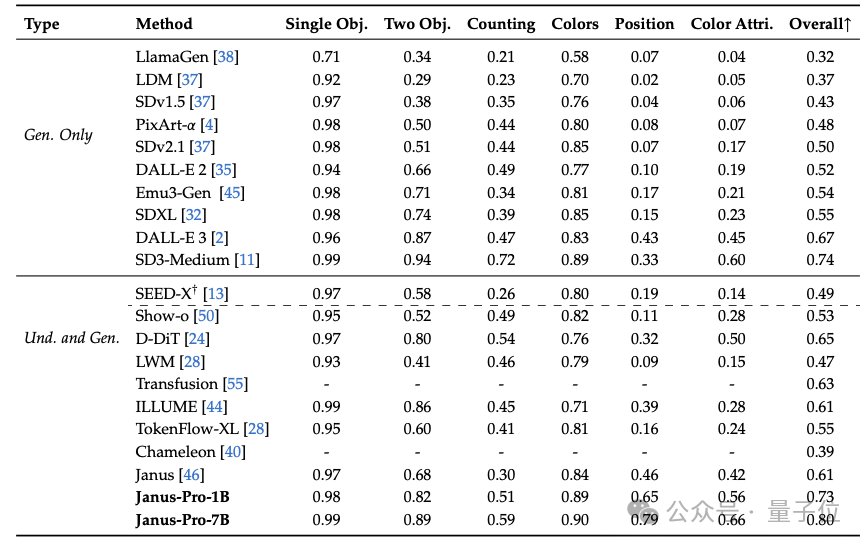
最终结果显示,实现了与现有视觉理解生成SOTA模型持平的水准。
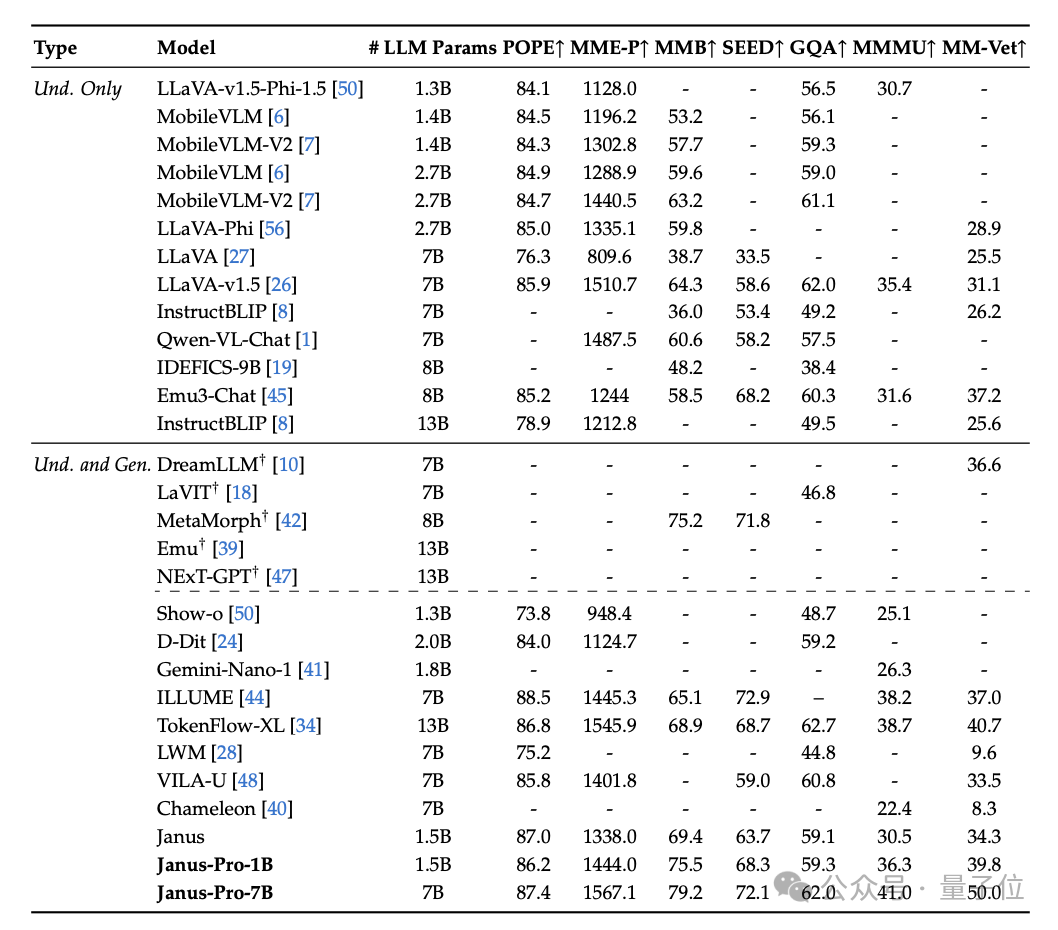
△GenEval基准
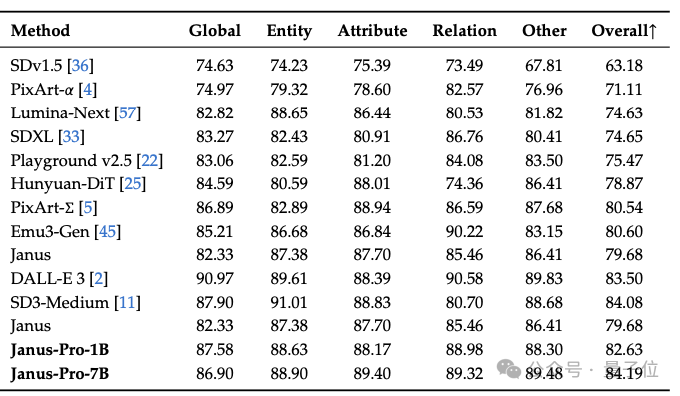 △DPG-Bench基准
△DPG-Bench基准
与上一个版本 Janus相比,它可以为简短提示提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。

更多多模态理解和视觉生成能力的定性结果。
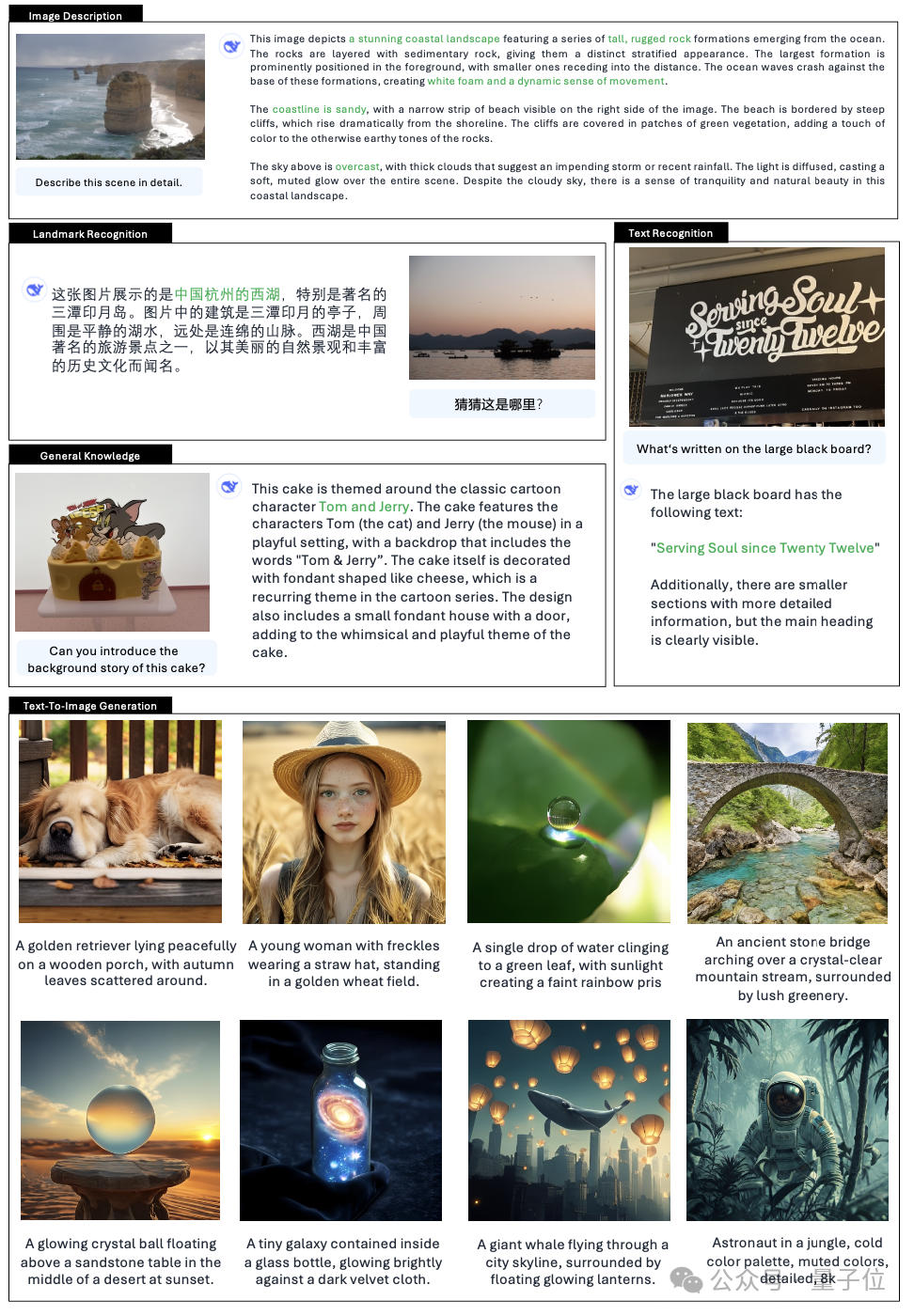
DeepSeek征服全球用户
想必这两天一定是被DeepSeek刷屏了——
是科技圈非科技圈、七大姑八大姨都搁那讨论的程度。
像同为杭州六小龙的游戏科学,其创始人CEO、《黑神话:悟空》制作人也专门发微博支持:顶级科技成果,六大突破。

还有DeepSeek自称MOSS,也被流浪地球导演郭帆注意到了。
好好好,DeepSeek是不是直接预订下一部主角了(Doge)。
而这故事的一开始,正是前几天刚刚开源的推理模型R1,以其低廉的成本、免费的使用以及完全不输o1的性能,征服了全球用户,直接引发行业地震。
仅仅花费560万美元训练的R1,相当于Meta GenAI团队任一高管的薪资,在很多AI基准测试中已经达到甚至超越OpenAI o1模型。
而且DeepSeek是真的免费,而ChatGPT虽然在免费榜上,但要是想解锁它的完全体,还是要掏上200美元。
于是乎,大家开始纷纷转向DeepSeek来“构建一切”,也就迅速登顶美区苹果应用商店免费App排行第一,超越了ChatGPT和Meta的Threads等热门应用。

用户量的激增也导致DeepSeek服务器多次宕机,官方不得不紧急维护。
而聚焦于行业内,大家对于DeepSeek的关注,在于如何在有限的资源成本情况下,实现与OpenAI持平的水准。
相比于国外动辄百亿千亿美元成本、几十上百万张卡这种粗放的模式,用DeepSeek很多技术细节都放在如何降低成本开销上。
比如蒸馏。R1总共开源了6个在R1数据上的蒸馏小模型,蒸馏版Qwen-1.5B都能在部分任务上超过GPT-4o。
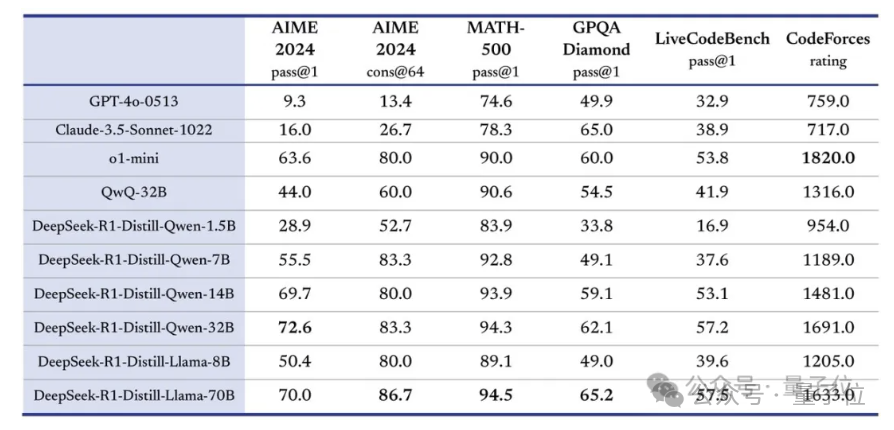
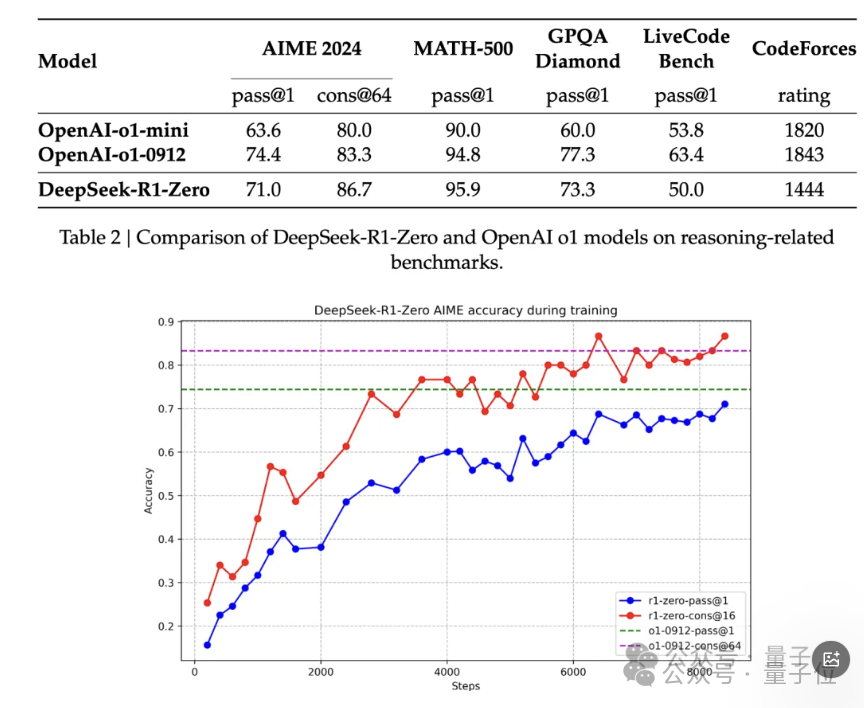
还有就是纯强化学习,抛弃SFT环节,通过数千次的强化学习来提升模型的推理能力,然后在AIME 2024上的得分与OpenAI-o1-0912的表现相当。
也正因为这样,让人不免想到OpenAI前几天砸5000亿美元建数据中心以及英伟达长时间以来在高端GPU的垄断地位。
拿5000亿美元建数据中心,是有必要的吗?
大规模的AI算力投资,是有必要的吗?
这样的讨论,在资本市场得到了响应。美股开盘后,英伟达股价暴跌17%,创下自2020年3月以来最大跌幅,市值蒸发近6000亿美元,老黄自己的个人财富一夜之间也缩水了超130亿美元。
博通、AMD等芯片巨头也纷纷大幅下跌。
对此,英伟达公开回应称,DeepSeek是一项卓越的人工智能进展,也是测试时扩展的绝佳范例。DeepSeek的研究展示了如何运用该技术,借助广泛可用的模型以及完全符合出口管制规定的算力,创建新模型。推理过程需要大量英伟达 GPU和高性能网络。如今我们有三条扩展定律:持续适用的预训练和后训练定律,以及新的测试时扩展定律。
同样被动摇的还有Meta、OpenAI。
Meta内部甚至成立了专门的研究小组,试图剖析DeepSeek的技术细节,以改进其Llama系列模型,并且新年计划中预算4000亿起步搞AI,年底AI算力将达130万卡。
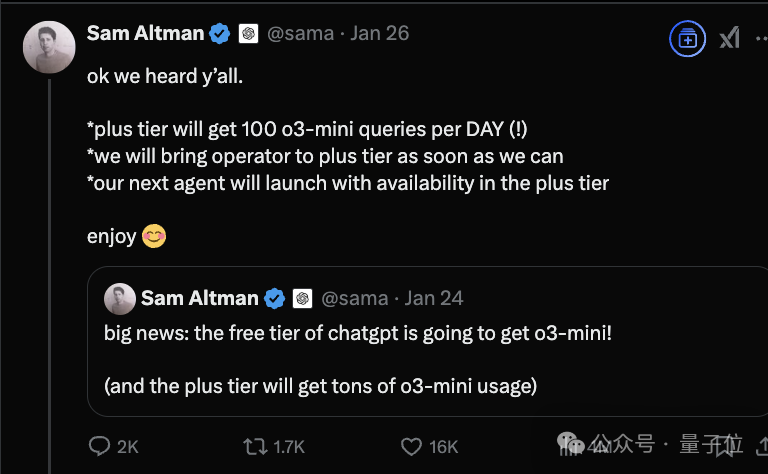
奥特曼也紧急透露新模型o3-mini即将免费上线ChatGPT的消息,试图挽回一点市场热度。
现在有了新模型发布,关于DeepSeek的讨论还在继续。
DeepSeek新版本疑似很快发布,时间是2025年2月25日。

杭州昨夜不眠
同一个夜晚,同一个杭州。
就在DeepSeek新模型发布不久,Qwen也更新了自己的开源家族:
Qwen2.5-VL。

这个标题怎么有三体那味了。
它有3B、7B 和 72B三种尺寸,可以支持视觉理解事物、Agent、理解长视频并且捕捉事件,结构化输出等等。
(详情内容可以参考下一篇推文)
ps,最后,继杭州六小龙之后,广东AI三杰也出现了。
(杭州六小龙分别是游戏科学、DeepSeek、宇树科技、云深处科技、强脑科技和群核科技)
他们分别是湛江人梁文锋(DeepSeek创始人),汕头人杨植麟(月之暗面、Kimi创始人)以及AI学术大佬广州人何恺明。

抱抱脸链接:
https://huggingface.co/deepseek-ai/Janus-Pro-7B
GitHub链接:
https://github.com/deepseek-ai/Janus
— 完 —
量子位智库年终发布三大年度报告!
带你一起回顾2024年人工智能、智能驾驶、Robotaxi新趋势,预见2025年科技行业新机遇!

2024年度AI十大趋势报告

Robotaxi2024年度格局报告

智能驾驶2024年度报告
一键关注 ? 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
