
春节期间,DeepSeek新一代开源模型以惊人的低成本和高性能引发热议,在全球投资界引发剧震。市场上甚至出现了DeepSeek“仅用500万美元就复制OpenAI”的说法,认为这将给整个AI基础设施产业带来“末日”。

对此,华尔街知名投行伯恩斯坦在详细研究DeepSeek技术文档后发布报告称,这种市场恐慌情绪明显过度,DeepSeek用“500万美元复制OpenAI”是市场误读。
另外,该行认为,虽然DeepSeek的效率提升显著,但从技术角度看,并非奇迹。而且,即便DeepSeek确实实现了10倍的效率提升,这也仅相当于当前AI模型每年的成本增长幅度。
该行还表示,目前AI计算需求远未触及天花板,新增算力很可能会被不断增长的使用需求吸收,因此对AI板块保持乐观。
“500万美元复制OpenAI”是误读
对于“500万美元复制OpenAI”的说法,伯恩斯坦认为,实际上是对DeepSeek V3模型训练成本的片面解读,简单将GPU租用成本计算等同于了总投入:
这500万美元仅仅是基于每GPU小时2美元的租赁价格估算的V3模型训练成本,并未包括前期研发投入、数据成本以及其他相关费用。
技术创新:效率大幅提升但非颠覆性突破
接着,伯恩斯坦在报告中详细分析了DeepSeek发布的两大模型V3、R1详细技术特点。
(1)V3模型的效率革命
该行表示,V3模型采用专家混合架构,用2048块NVIDIA H800 GPU、约270万GPU小时就达到了可与主流大模型媲美的性能。
具体而言,V3模型采用了混合专家(MoE)架构,这一架构本身就旨在降低训练和运行成本。在此基础上,V3还结合了多头潜在注意力(MHLA)技术,显著降低了缓存大小和内存使用。
同时,FP8混合精度训练的运用进一步优化了性能表现。这些技术的综合运用,使得V3模型在训练时仅需同等规模开源模型约9%的算力,便能达到甚至超越其性能。
例如,V3预训练仅需约270万GPU小时,而同样规模的开源LLaMA模型则需要约3000万GPU小时。
MoE架构: 每次只激活部分参数,减少计算量。
MHLA技术: 降低内存占用,提升效率。
FP8混合精度训练: 在保证性能的同时,进一步提升计算效率。
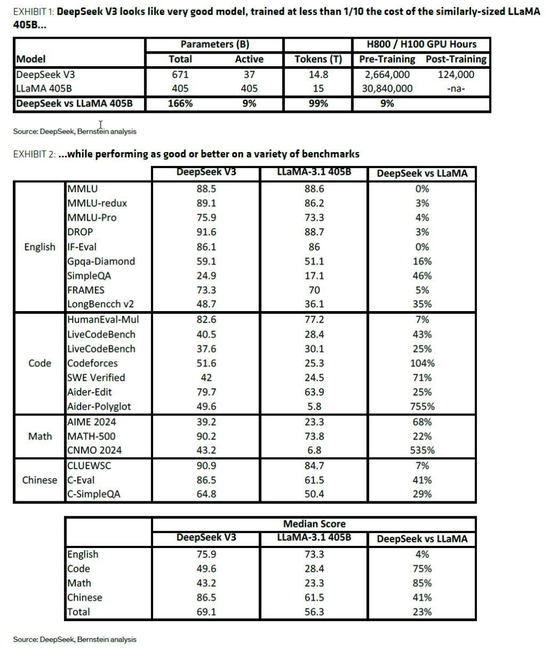
谈及V3模型带来的效率提升,伯恩斯坦认为,与业界3-7倍的常见效率提升相比并非颠覆性突破:
MoE架构的重点是显著降低训练和运行的成本,因为在任何一次只有一部分参数集是活动的(例如,当训练V3时,只有671B个参数中的37B为任何一个令牌更新,而密集模型中所有参数都被更新)。
对其他MoE比较的调查表明,典型的效率是3-7倍,而类似大小的密度模型具有类似的性能;
V3看起来甚至比这个更好(10倍以上),可能考虑到该公司在模型中带来的其他一些创新,但认为这是完全革命性的想法似乎有点夸张,并且不值得在过去几天里席卷twitter世界的歇斯底里。
(2)R1模型的推理能力与“蒸馏”策略
DeepSeek的R1模型则在V3的基础上,通过强化学习(RL)等创新技术,显著提升了推理能力,使其能够与OpenAI的o1模型相媲美。
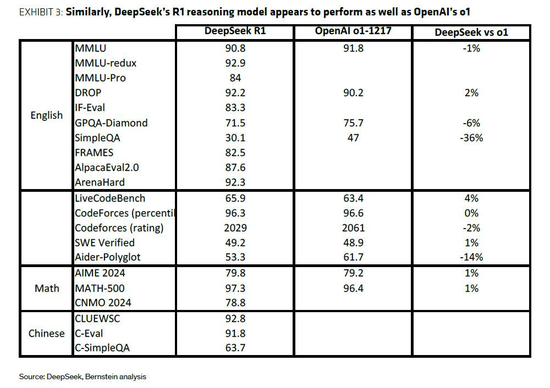
值得一提的是,DeepSeek还采用了“模型蒸馏”策略,利用R1模型作为“教师”,生成数据来微调更小的模型,这些小模型在性能上可以与OpenAI的o1-mini等竞争模型相媲美。这种策略不仅降低了成本,也为AI技术的普及提供了新的思路。
强化学习(RL): 提升模型推理能力。
模型蒸馏: 利用大模型训练小模型,降低成本。
对AI板块保持乐观
伯恩斯坦认为,即便DeepSeek确实实现了10倍的效率提升,这也仅相当于当前AI模型每年的成本增长幅度。
事实上,在“模型规模定律”不断推动成本上升的背景下,像MoE、模型蒸馏、混合精度计算等创新对AI发展至关重要。
根据杰文斯悖论,效率提升通常会带来更大的需求,而非削减开支。该行认为,目前AI计算需求远未触及天花板,新增算力很可能会被不断增长的使用需求吸收。
基于以上分析,伯恩斯坦对AI板块保持乐观。
