


Mixture-of-Experts (MoE) models utilize a router to allocate tokens to specific expert modules, activating only a subset of parameters, often leading to superior efficiency and performance compared to dense models. In these models, a large feed-forward network is divided into smaller expert networks, with the router—typically an MLP classifier—determining which expert processes each input. However, a key issue arises from the router’s separation from the experts’ execution. Without direct knowledge of the experts’ capabilities, the router’s assignments are predictions without labels. Misassignments can hinder expert performance, requiring expert adaptation or iterative router improvement, resulting in inefficiencies during training.
Researchers from Renmin University of China, Tencent, and Southeast University have introduced Autonomy-of-Experts (AoE), a new MoE paradigm where experts independently decide whether to process inputs. This approach leverages each expert’s awareness of its ability to handle tokens, reflected in the scale of its internal activations. In AoE, experts calculate internal activations for all inputs, and only the top-ranked ones, based on activation norms, proceed with further processing, eliminating the need for routers. The overhead from caching unused activations is reduced using low-rank weight factorization. With up to 4 billion parameters, pre-trained AoE models outperform traditional MoE models in efficiency and downstream tasks.
The study examines sparse MoE models, where each feed-forward network (FFN) module functions as an expert. Unlike dense MoE models, which utilize all parameters, sparse MoE models improve efficiency by activating only the most relevant experts for specific inputs. These models rely on a router to assign inputs to the appropriate experts, typically using a “token choosing Top-K experts” approach. A key challenge is maintaining balanced expert utilization, as routers often overuse certain experts, leading to inefficiencies. To address this, load-balancing mechanisms ensure a more equitable distribution of tasks among experts by incorporating auxiliary losses, thereby enhancing overall efficiency.
The AoE is a method where experts independently determine their selection based on internal activation norms, eliminating the need for explicit routing mechanisms. Initial experiments revealed that the scale of activation norms at certain computational points reflects an expert’s capability to process inputs effectively. AoE builds on this insight by ranking experts based on the L2 norms of compressed activations, selecting the top-performing ones for computation. By factorizing weight matrices and caching low-dimensional activations, AoE significantly reduces computational and memory overhead while maintaining high efficiency, addressing limitations in traditional MoE frameworks.
The research compares the AoE framework to traditional MoE models through experiments on smaller pre-trained language models. Using a 12-layer model with 732 million parameters and eight experts per layer, trained on 100 billion tokens, the findings highlight that AoE performs better than MoE in both downstream tasks and training efficiency. It shows that the best performance is achieved when the reduced dimension is about one-third of the model’s overall dimension. AoE enhances load balancing and expert utilization across layers, leading to better generalization and efficiency when combined with alternative expert selection methods.
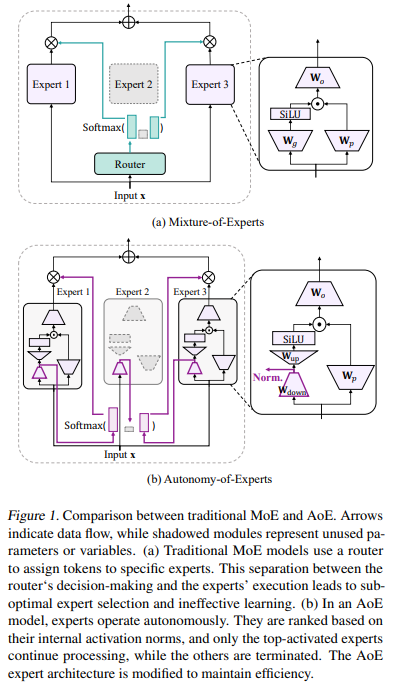
In conclusion, AoE is a MoE framework designed to overcome a key limitation in traditional MoE models: separating the router’s decisions and the experts’ execution, often resulting in inefficient expert selection and suboptimal learning. In AoE, experts autonomously select themselves based on their internal activation scales, eliminating the need for routers. This process involves pre-computing activations and ranking experts by their activation norms, allowing only top-ranking experts to proceed. Efficiency is enhanced through low-rank weight factorization. Pre-trained language models using AoE outperform conventional MoE models, showcasing improved expert selection and overall learning efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Autonomy-of-Experts (AoE): A Router-Free Paradigm for Efficient and Adaptive Mixture-of-Experts Models appeared first on MarkTechPost.
